在 DROP (Discrete Reasoning Over Paragraphs,段落级离散推理) 评估中,模型需要先从英文文段中提取相关信息,然后再对其执行离散推理 (例如,对目标对象进行排序或计数以得出正确答案,如下图中的例子)。其使用的指标是自定义 F1 以及精确匹配分数。
基于文段的推理示例
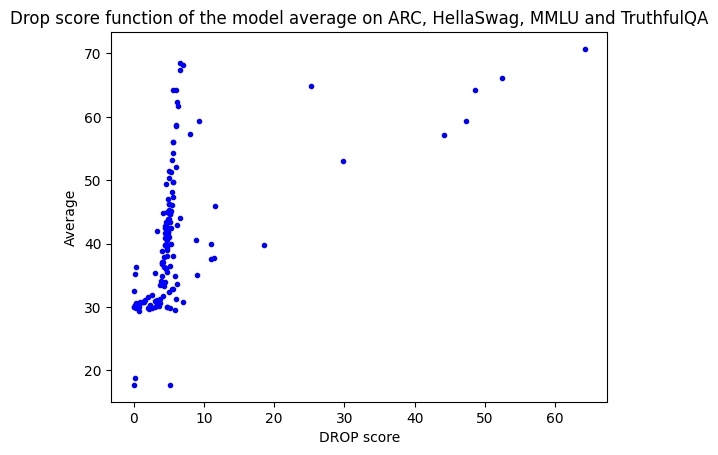
三周前,我们将 DROP 添加至开放 LLM 排行榜中,然后我们观察到预训练模型的 DROP F1 分数有个奇怪的趋势: 当我们把排行榜所有原始基准 (ARC、HellaSwag、TruthfulQA 和 MMLU) 的平均分 (我们认为其一定程度上代表了模型的总体性能) 和 DROP 分数作为两个轴绘制散点图时,我们本来希望看到 DROP 分数与原始均分呈正相关的关系 (即原始均值高的模型,DROP 分数也应更高)。然而,事实证明只有少数模型符合这一预期,其他大多数模型的 DROP F1 分数都非常低,低于 10。
该图展现了两类趋势: 少部分模型 DROP 分数与原始均分正相关 (对角线那几个点),大多数模型则不管原始均分多少,DROP 分数统一集中在 5 左右 (图左侧的垂直线)。
文本规范化的锅
第一站,我们观察到文本规范化的结果与预期不符: 在某些情况下,当正确的数字答案后面直接跟有除空格之外的其他空白字符 (如: 换行符) 时,规范化操作导致即使答案正确也无法匹配。举个例子,假设生成的文本是 10\n\nPassage: The 2011 census recorded a population of 1,001,360 ,而对应的标准答案为 10 。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。