NGINX 向云原生演进,All in OpenNJet
需求
为了节省带宽、能够快速获取资源,在中间代理服务器上,通常会配置缓存。缓存机制的基本原理是将 Web 资源(如 HTML、CSS、JavaScript、图像等)保存在客户端或中间代理服务器上,以便在后续请求中直接使用该缓存副本,而不必重新获取资源。当客户端或代理服务器收到对资源的请求时,它们首先检查缓存,如果存在有效的缓存副本,可以直接返回缓存的副本,从而避免请求的发送和服务器端的处理过程。
但是上述的缓存机制仍然存在一定的问题,第一次访问资源是没有缓存的,所以首先要跟服务器通信,然后下载资源,如果带宽有限而且资源很大的情况(比如视频文件),客户端就会长时间处于下载阶段,效率低下。针对这种情况,我们就需要实现 cache 应用加速的功能。
cache 应用加速由 Web 管理员提前通过下发配置到代理服务器,由代理服务器提前下载资源并进行缓存,这样当客户端首次访问的时候也能够直接从缓存中获取资源,避免等待。
下面假设一种场景进行详细说明:
比如某银行总部上传了一个很大的文件,各银行分部第二天就需要使用这个文件,当银行分部员工下载这个文件的时候,由于带宽有限或者带宽资源紧张就可能导致该员工一直等待下载文件中,从而影响客户的办理进度。
基于该场景,现有 cache 缓存功能时序图如下:![]()
而使用cache应用加速功能后,时序图如下:![]()
方案
消息持久化
通过在 ctrl 进程中开启一个 cache 动态 API 入口,分别实现添加、删除配置接口以及动态获取进度接口
dyn_http_cache_module
|
Bash
location /cache {
cache_quick_api;
} |
消息持久化:
采用与健康检查类似的持久化方式,使用 kv_get\kv_set 进行存取
reload:
reload 重启之后通过 kv_get 获取所有 cache 配置进行处理
前提:
- 需要 http 层配置 proxy_cache_path(zone下面以cache作为示例)
- 需要 http 层配置 map $purge_method (支持通过PURGE方法删除)
|
Bash
proxy_cache_path /data/njet/cache levels=1:2 keys_zone=cache:10m purger=on max_size=20g inactive=30m;
map $request_method $purge_method{
PURGE 1;
default 0;
} |
proxy_cache_path参数说明:
|
参数 |
说明 |
|
/data/njet/cache |
缓存文件存放本地磁盘位置 |
|
levels=1:2 |
最多三级存放 |
|
keys_zone=cache:10m |
缓存使用的共享内存名称以及大小 |
|
purger=on |
是否支持purge清除 |
|
max_size=20g |
最大 cache 空间 |
|
inactive=30m |
缓存资源不活跃时间,超过该时间没被访问,该资源就会被清理 |
被代理服务器上需要通知代理服务器缓存内容的时间,否则代理服务器不会对内容进行缓存,通过X-Accel-Expires,expires,Cache-Control “max-age=”其中一个参数指定时间。如果代理服务器上配置了proxy_cache_valid的时间,那么被代理服务器可以不指定缓存内容的时间。
下面的示例配置,代理缓存时间主要由两个参数来控制
proxy_cache_path指令后面的inactive 表示不活跃时间,在该时间内资源没有被访问就会被清理
proxy_cache_valid 指令后面的时间表示最长缓存时间,在满足上面inactive时间内保持访问,也最多到这个最长缓存时间有效
比如要缓存一周,可使用下面的配置:
|
http {
proxy_cache_path /data/njet/cache levels=1:2 keys_zone=cache:10m purger=on max_size=20g inactive=7d;
map $request_method $purge_method{
PURGE 1;
default 0;
}
server {
listen 80;
proxy_cache_valid any 7d;
}
server {
listen 443 ssl;
proxy_cache_valid any 7d;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;
ssl_certificate /etc/vsftpd/.sslkey/vsftpd.pem;
ssl_certificate_key /etc/vsftpd/.sslkey/vsftpd.pem;
}
} |
![]()
API 接口
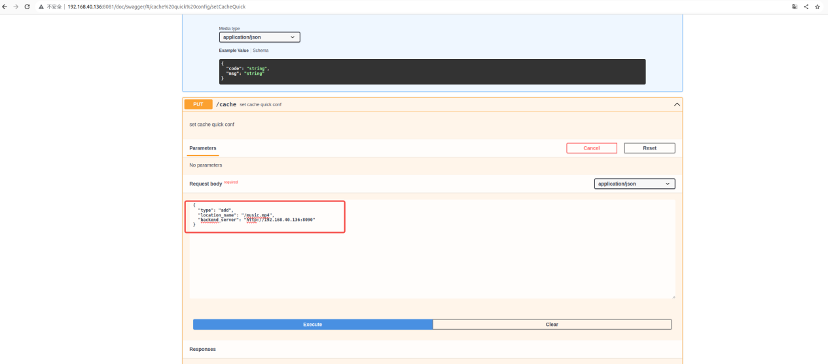
添加cache加速配置
PUT http://192.168.40.136:8081/cache
- 往特定server下添加特定的资源location,通过调用动态location 添加接口实现
比如往80端口,servername为www.a.com下添加一个/music.mp4 location
|
server {
listen 80;
server_name www.a.com;
location /music.mp4 {
proxy_pass https://localhost:8002;
proxy_cache cache;
proxy_cache_purge 1;
}
} |
动态location api 添加location格式如下
|
{
"type": "add",
"addr_port": "0.0.0.0:80",
"server_name": "www.a.com",
"locations": [
{
"location_rule": "=",
"location_name": "/music.mp4",
"location_body": "return 200 ok",
"proxy_pass": "https://backend1"
}
]
} |
cache api 收到该请求后,组装动态location api需要的格式如下:
|
{
"type": "add",
"addr_port": "0.0.0.0:80",
"server_name": "www.a.com",
"locations": [
{
"location_rule": "=",
"location_name": "/music.mp4",
"location_body": "proxy_cache cache; proxy_cache_purge $purge_method",
"proxy_pass": "http://backend1"
}
]
} |
- 启动一个访问该资源location的事件,在该事件中创建对该资源的http连接,维护读写时间,读取的数据丢弃即可
调用njt_event_connect_peer创建一个peer_connection, 如果是ssl,需要再调用njt_http_hc_ssl_init_connection
然后设置该connection的读写handler
peer_connection->write->handler= njt_http_cache_write_handler;
peer_connection->read->handler= njt_http_cache_read_handler;
write handler 组装http报文发送
read handler 接收数据并丢弃,同时维护数据下载的元数据
根据http response 的content_length作为资源总大小,试试读取返回的资源大小累计作为已下载大小
request:
|
{
"type": "add",
"location_name": "/music.mp4",
#代理的server类型与backend_server的类型一致
#http 固定使用80端口
#https 固定使用443端口
"backend_server":"https://192.168.40.136:8090"
} |
|
参数 |
类型 |
必填 |
取值 |
说明 |
|
type |
string |
是 |
add |
|
|
location_name |
string |
是 |
location 名字 |
|
|
backend_server |
string |
是 |
http://{ip}:{port} 或者https://{ip}:{port}
|
#代理的server类型与backend_server的类型一致
#http 固定使用80端口
#https 固定使用443端口 |
response:
|
Bash
{
"code": 0, #0:success 非0: error
"msg": "success"
} |
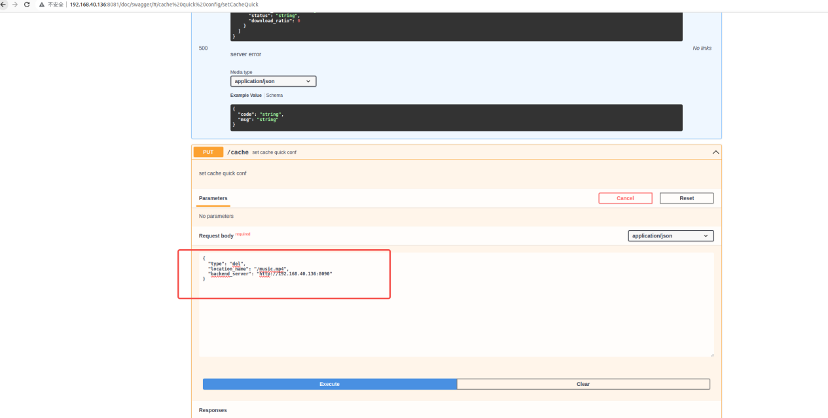
删除cache加速配置
根据输入的信息组装动态删除location结构,调用删除location api删除该资源
根据输入的信息从动态hash结构查找资源,将其删除
PUT http://192.168.40.136:8081/cache
删除cache配置如下,与动态删除location接口一致
|
{
"type": "del",
#location_name 与backend_server字段要与add cache配置时一致
"location_name": "/music.mp4",
"backend_server":"https://192.168.40.136:8090"
} |
|
参数 |
类型 |
必填 |
取值 |
说明 |
|
type |
string |
是 |
del |
|
|
location_name |
string |
是 |
location 名字 |
|
|
backend_server |
string |
是 |
http://{ip}:{port} 或者https://{ip}:{port} |
|
response:
|
{
"code": 0, #0:success 非0: error
"msg": "success"
} |
查询特定cache下载进度
根据输入的信息从动态hash结构查找资源,根据目前已下载大小和总大小,计算出下载进度
PUT http://192.168.40.136:8081/cache
request:
|
{
"type": "download_status",
#location_name 与backend_server字段要与add cache配置时一致
"location_name": "/music.mp4",
"backend_server":"https://192.168.40.136:8090"
} |
|
参数 |
类型 |
必填 |
取值 |
说明 |
|
type |
string |
是 |
download_status |
|
|
location_name |
string |
是 |
location 名字 |
|
|
backend_server |
string |
是 |
http://{ip}:{port} 或者https://{ip}:{port} |
|
response:
|
{
"code": 0, #0:success 非0: error
"msg": "download_ratio: 0" #0-100, 百分比
} |
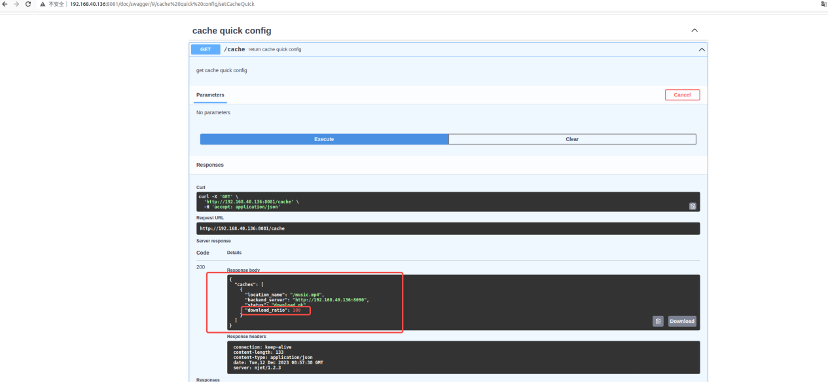
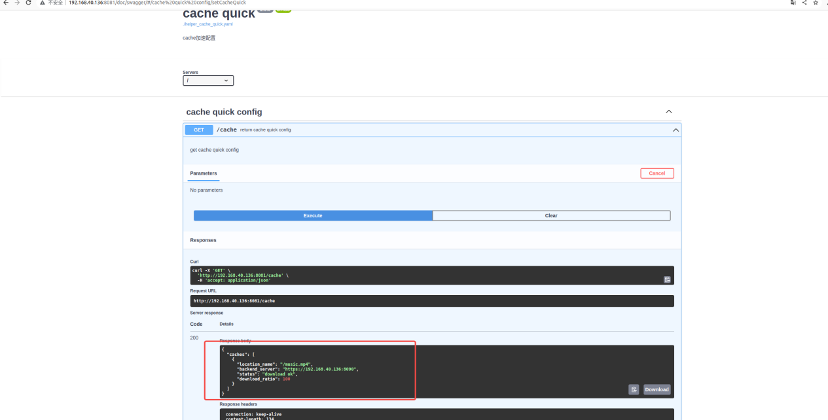
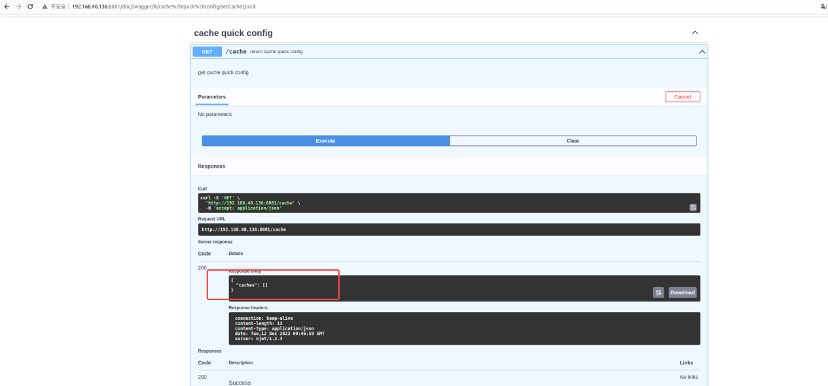
查询所有cache配置
查询所有cache加速配置
GET http://192.168.40.136:8081/cache
response:
|
{
"caches": [
{
"location_name": "/music.mp4",
"backend_server":"https://192.168.40.136:8090",
"status": "success",
"download_ratio": 100
},
{
"location_name": "/music2.mp4",
"backend_server":"http://192.168.40.136:8091",
"status": " add dyn location error",
"download_ratio": 0
}
]
} |
测试
配置示例
njet.conf
|
...
http {
...
proxy_cache_path /root/bug/njet1.0/cache levels=1:2 keys_zone=cache_quick:10m purger=on max_size=20g inactive=7d;
map $request_method $purge_method{
PURGE 1;
default 0;
}
#用于http cache加速测试
server {
listen 80;
proxy_cache_valid any 7d; #缓存7天,注意上面proxy_cache_path后inactive也设置为7天
}
#用于https cache加速测试
server {
listen 443 ssl;
proxy_cache_valid any 7d;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5;
ssl_certificate /etc/vsftpd/.sslkey/vsftpd.pem;
ssl_certificate_key /etc/vsftpd/.sslkey/vsftpd.pem;
}
} |
njet_ctrl.conf
|
...
load_module modules/njt_http_cache_quick_module.so; #加载cache加速模块so
...
http {
dyn_sendmsg_conf conf/iot-ctrl.conf;
access_log logs/access_ctrl.log combined;
#register config=conf/register.json server=127.0.0.1 port=8081 location=/adc;
include mime.types;
lua_package_path "/root/project/njet/njet_main/work/work/etc/njet/lualib/lib/?.lua;$prefix/scripts/?.lua;;";
server {
listen 8081;
#配置cache加速开关location
location /cache {
cache_quick_api;
}
}
} |
HTTP cache测试
添加一项cache 配置
![]()
下载完成后,查询进度
![]()
通过curl访问,会显示命中缓存
![]()
删除该cache配置,查询不到该信息
![]()
![]()
Https cache测试
添加一项cache 配置
![]()
下载完成后,查询进度
![]()
通过curl访问,会显示命中缓存
curl https://192.168.40.136:443/music.mp4 -v -k
![]()
删除该cache配置,查询不到该信息
![]()
![]()
遗留问题&注意事项
- reload后或者njet停掉重新启动后,只会加载配置项,不会去重新下载,如果需要重新下载,可以先删除规则再重新添加规则可触发下载
- 缓存的有效期时间依赖于客户端的cache header等设置或者server端proxy_cache_valid 指令的影响
- 如果需要主动删除缓存,可以通过PURGE方法删除
- 对于失败的规则,查询会在status字段提示错误原因,比如配置项错误等或者内部错误,可根据提示选择删除该规则,并进行新规则添加
- 目前删除规则后并不会自动清理本地缓存的文件内容
OpenNJet 最早是基于 NGINX1.19 基础 fork 并独立演进,具有高性能、稳定、易扩展的特点,同时也解决了 NGINX 长期存在的难于动态配置、管理功能影响业务等问题。 邮件组 官