本文分享自华为云社区《当创建一个service后,kubernetes会发生什么?》,作者:可以交个朋友。
一、Service介绍
1.1 Kubernetes为什么会引入service?
考虑到集群中Pod实例IP地址随着工作负载的生命周期的变化,常规通过访问Pod实例的IP方法变得不再实用。
每个工作负载通常有一个或者更多个后端Pod实例,如何将流量请求做到负载均衡转发也是迫在眉睫。
1.2 Service概念
service用于一组提供服务、具有相同 label Pod的抽象集合的网络访问地址(包括网络协议IPv4/IPv6地址和服务域名地址),提供集群内/外访问通信,屏蔽后端实例Pod信息并为后端Pod实例提供负载均衡的能力。
1.3 Kubernetes中存在哪些类型的service?
clusterIP:Kubernetes集群默认自动设置service的虚拟IP地址,仅可被集群内的其他客户端访问。
NodePort:将service的端口映射到每个Node的(指定/随机)端口,供集群外客户端通过集群任一节点的IP地址+(指定/随机)端口访问,即NodePort。
LoadBalancer:将service映射到一个已存在的负载均衡器IP地址上,此service方式多见于云厂商。
ExternalName:通过在集群内创建该类service,可将集群外部服务引入至集群内,供集群内其他服务通过IP地址或域名地址访问。
Headless service: 在一些特殊场景中,客户端访问不需要kubernetes中service实现的负载均衡功能,而是由客户端直接去发现/选择服务端的后端实例访问,就需要一种特殊的服务“Headless service”。这是一种没有访问入口(即service没有IP地址)的service。kube-proxy不会为这种类型的service(Headless service)创建iptables/ipvs转发规则。
二、Service、Endpoint、Pod以及与kube-proxy组件的关联协作结构示意图
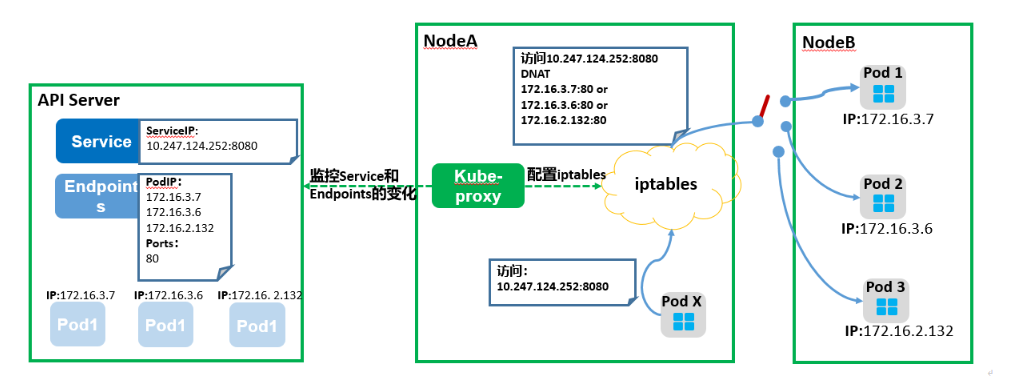
下图是一个实际访问Service的图示,PodX访问Service(10.247.124.252:8080),在发送数据包时,在节点上根据iptables规则,目的IP:Port被随机替换为后端Pod组中某一个Pod的IP:Port,从而通过Service转发到到实际的Pod。从这里也可以看出,service对应的ip(clusterip)不是一个真实的ip地址,是通过节点kube-proxy组件通过刷新节点iptables或者ipvs规则,将四层报文的目的ip从clusterip DNAT转换为podip做通的通道。集群外节点没有kube-proxy组件去刷新相关规则,是集群外节点无法访问clusterip的本质原因。
![cke_117.png]()
三、Service创建流程图以及解读
3.1 Service创建后,各个组件协同关系介绍
![cke_118.png]()
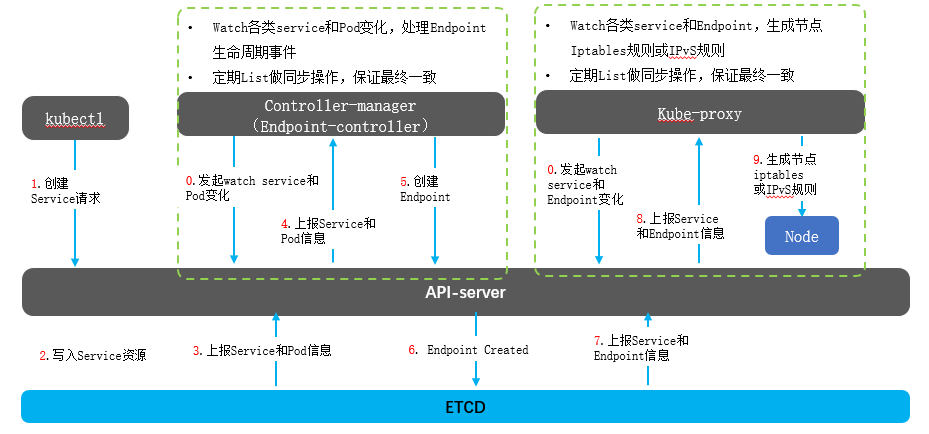
用户使用通过kubectl客户端发起创建service资源对象请求至api-server。
api-server对请求用户鉴权、准入控制操作,然后将该请求事件写入到etcd存储中。
考虑到Endpoint-controller采用非阻塞式长连接watch机制实时获取service资源对象信息,一旦集群中有service变化(包括创建、更新、删除),则通过apiserver获取etcd中相关service资源对象。且通过service资源对象中lable字段遍历、关联相关Pod资源。
api-server将相关service资源信息和pod资源信息返回给Endpoint-controller的watch接口长连接。
Endpoint-controller通过获取的service和pod资源对象生成对应的Endpoint资源对象,并将结果通过调用api-server写入etcd。
api-server将endpoint资源写入到etcd做持久化存储
考虑到kube-proxy采用非阻塞式长连接watch机制实时获取service资源对象和endpoint资源对象信息,一旦集群中有service和Endpoint变化(包括创建、更新、删除),则通过apiserver获取etcd中相关资源对象。
api-server将相关service资源信息和Endpoint资源信息返回给kube-proxy 的watch接口长连接。
每个节点上kube-proxy组件进程生成节点系统iptables规则或ipvs规则。
3.2 EndpointController能力说明
Endpoint也是Kubernetes集群中的一个资源对象,存储在Etcd中。Endpoint-controller控制器通过监听集群内Service和Pod资源对象的变化,管理维护Endpoint的生命周期。
监听到service创建,则创建同名的Enpoint资源,然后根据service的标签,获取集群中关联的Podip和相关端口生成Endpoint资源对象。。
监听到service更新,则根据更新后的service信息获取关联的Pod的信息,更新对应Enpoint对象。
监听到service删除,则删除与service同名的endpoint。
如果监听到Pod发生变化,则更新endpoint对象的Pod IP列表,将异常的Pod从endpoint后端列表中剔除,恢复或者新建后加入到Endpoint的列表中。
点击关注,第一时间了解华为云新鲜技术~