12 月 16 日,The Verge 根据获得的内部文件报道称,字节跳动曾秘密使用 OpenAI 的技术来开发自己的大语言模型,在代号为 Project Seed 的项目各阶段,都使用了 Azure 上的 OpenAI API 进行模型的训练和评估,并且频繁触及 API 的最大限额。
![]()
来源:https://www.theverge.com/2023/12/15/24003151/bytedance-china-openai-microsoft-competitor-llm
报道还称,相关员工知悉这种做法违反 OpenAI 使用政策,并在内部 Lark 上的对话中提及了「数据脱敏」等说法。但几个月前,字节命令团队在「模型开发的任何阶段」停止使用 GPT 生成的文本。同期,字节的「豆包」服务在国内获批并上线。据称,字节的内部目标是年底达到 GPT-3.5 的水平,明年中达到 GPT-4 的水平。
![]()
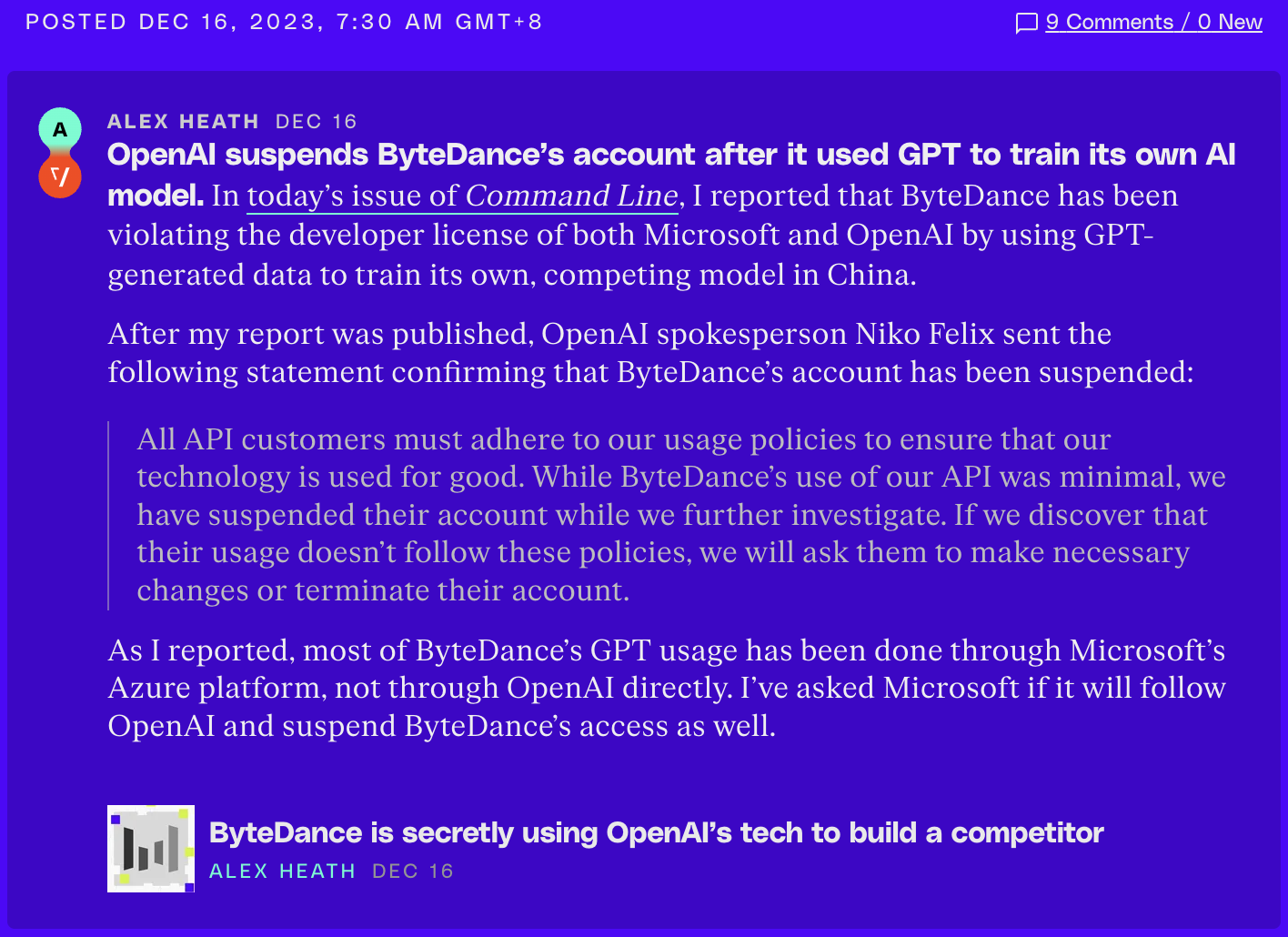
该报道发出后,OpenAI 声明称,字节的 API 用量很少,但已将其账户暂停使用并做进一步调查。如发现违反使用政策,将要求纠正或关停账户。微软在声明中重述了 Azure OpenAI 服务的政策,但未对报道事实或后续措施置评。
![]()
OpenAI 发言人 Niko Felix 确认字节跳动的账户已被暂停,并说道:“所有 API 客户都必须遵守我们的使用政策,以确保我们的技术得到良好利用。虽然字节跳动对我们 API 的使用很少,但我们在进一步调查期间已暂停了他们的帐户。如果我们发现他们的使用不遵守这些政策,我们将要求他们进行必要的更改或终止其帐户。”
就此,字节国外发言人于 16 日对 The Verge 表示,GPT 生成的数据在 Project Seed 项目开发的早期就被用于注释模型,并在今年年中左右从字节跳动的训练数据中删除。GPT 仅在中国以外市场的产品和功能中使用,豆包则是基于自行开发的模型,且仅在中国可用。
字节相关负责人则于 17 日回应媒体称,仅在年初有部分工程师将 OpenAI 服务用于较小模型的实验性项目研究;随着公司在 4 月引入 GPT API 调用规范检查,这种做法已经停止;9 月,内部又进行了一轮检查并采取进一步规范措施;在未来几天里会再次全面检查,以确保严格遵守相关服务的使用条款。
对于 OpenAI 禁止用其服务训练竞争模型的政策,历来存在不同看法。支持的观点认为,OpenAI 为训练模型做了大量前期投入,借助其服务「抄近道」是不正当的。反对的观点则认为,OpenAI 的训练过程得益于当时对 AI 训练无戒备的外部环境,在其之后的模型已不再能轻易获得到同样规模的训练数据,阻止其他公司调用其模型相当于建立事实上的垄断。