
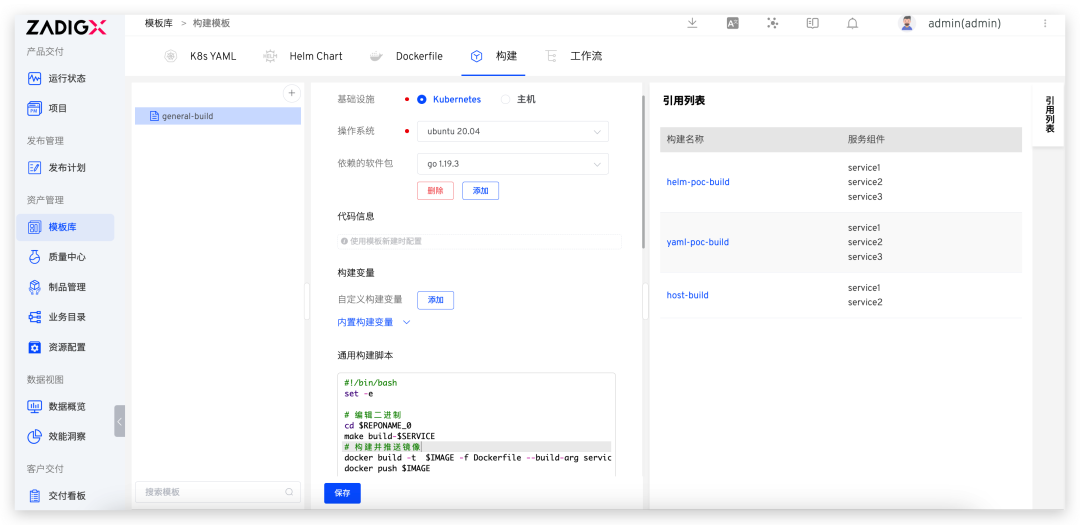
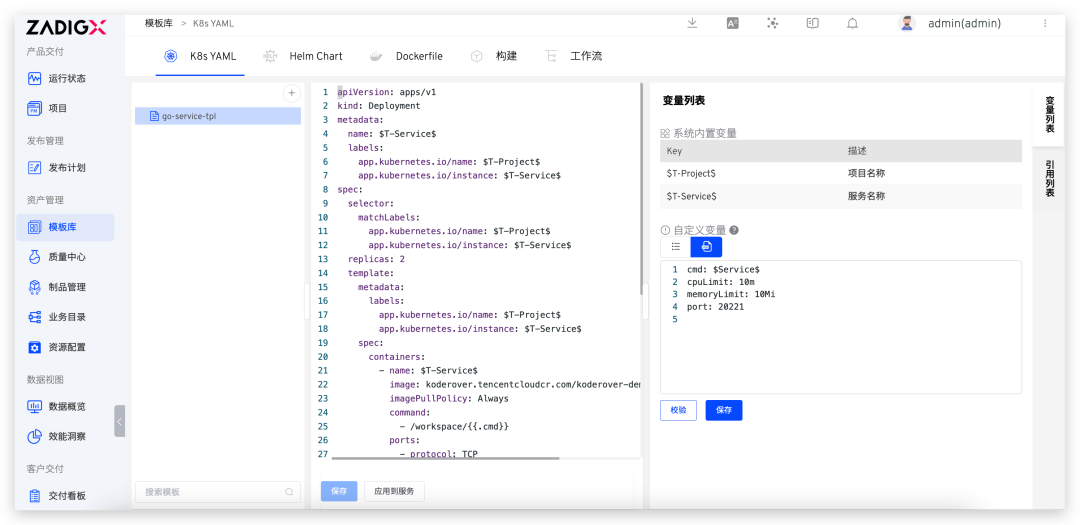
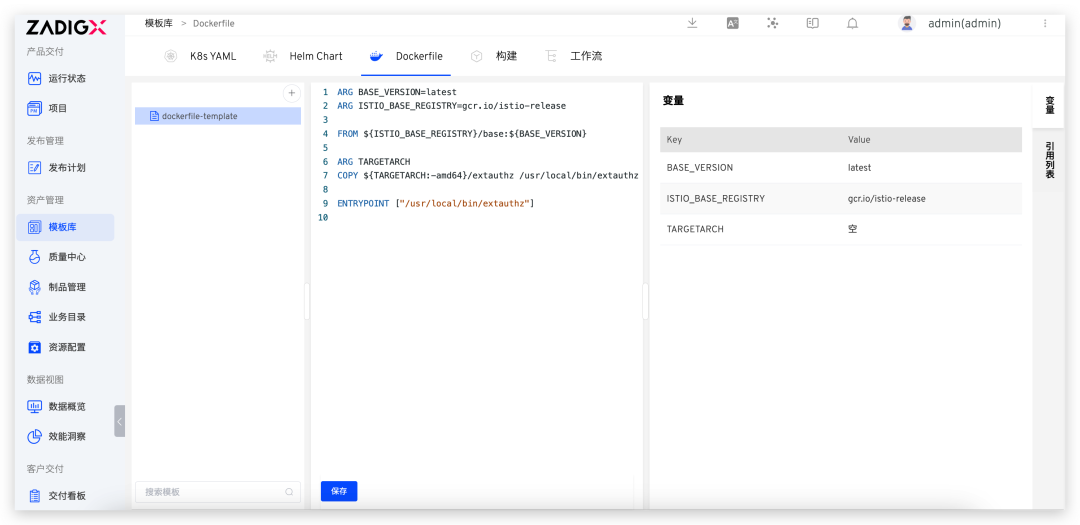
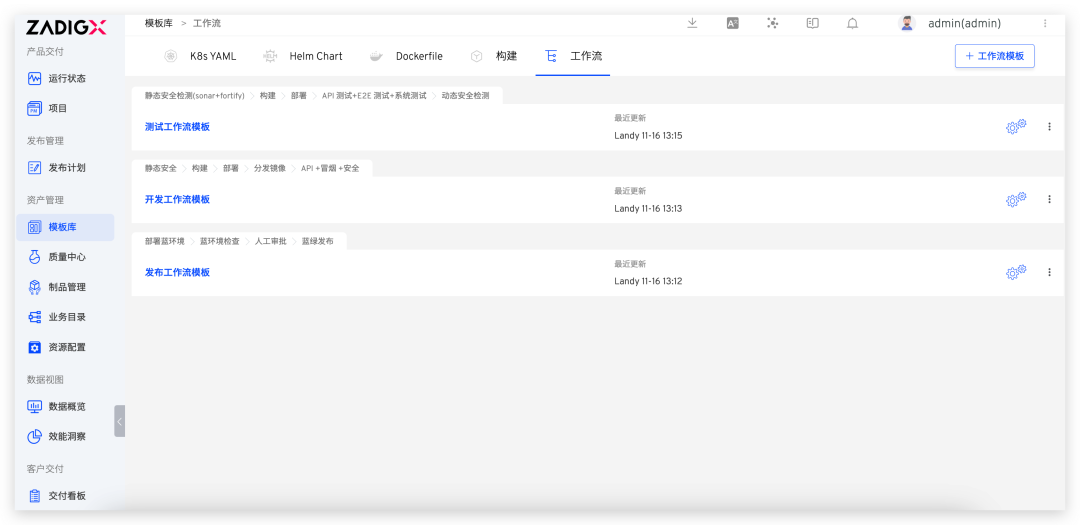







Spark Commiter 深度解读:Apache Spark Native Engine
本文来自网易杭研大数据技术专家、Apache Kyuubi PMC Member、Apache Spark Committer 尤夕多, 内容主要围绕 Apache Spark 与 Native Engine 展开,分享什么是 Native Engine,为什么要做 Native Engine,以及怎么做 Native Engine。 前言 Apache Spark 是基于 JVM 语言开发的分布式计算引擎,其 SQL 单个算子的执行性能已经很长时间没有得到提升,比如 Aggregation,Join 等。我们从 Spark2 迁移升级到 Spark3 的主要性能收益来源是 AQE ,而 AQE 其实是一个优化执行计划以及 Shuffle 数据读取的框架,和算子性能本身没有关系,因此 AQE 的优化效果也是有上限的。而在降本增效的背景下,计算集群资源越来越紧张,在不加机器下的基线保证成为常态,但是计算任务却会越来越多,因此用更底层的语言比如 C,C++,Rust 来实现 Native Engine 加速 Spark SQL 计算性能的需求就出现了。其实在 OLAP 生态里,已经有很多成...