![]()
如何搭建一个高效的推荐系统?
简单来说,现代推荐系统由训练/推理流水线(pipeline)组成,涉及数据获取、数据预处理、模型训练和调整检索、过滤、排名和评分相关的超参数等多个阶段。走遍这些流程之后,推荐系统能够给出高度个性化的推荐结果,从而提升产品的用户体验。
为了方便大家对此进行深入了解,我们邀请到 NVIDIA Merlin 团队,他们将详细介绍推荐系统的上述多个阶段的工作流程,以及推荐系统在电商、流媒体、社交媒体等多个行业领域的实践和用例。
01.
NVIDIA Merlin & Milvus
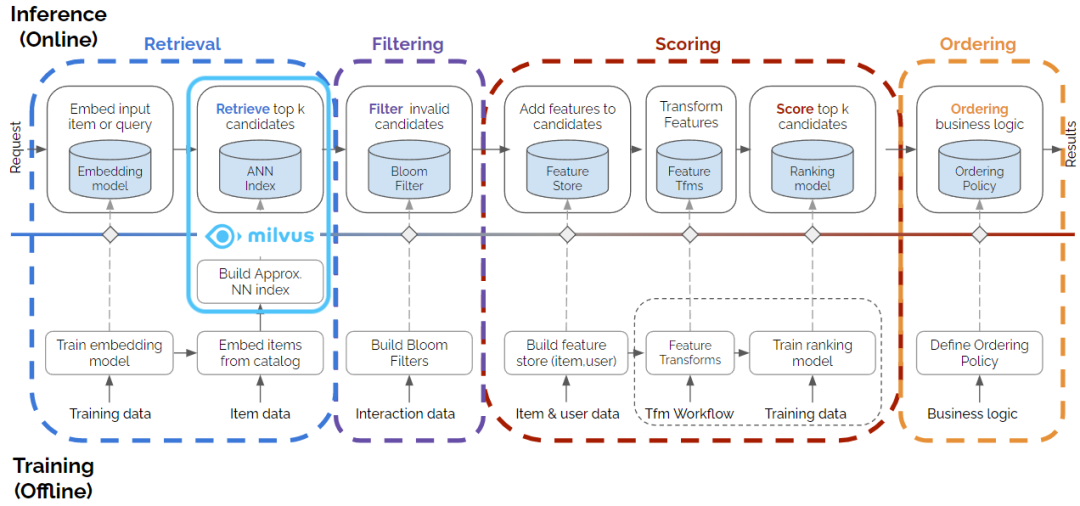
推荐系统 pipeline 中至关重要的一环便是为用户检索并找到最相关的商品。为了实现这一目标,通常会使用低维向量(embedding)表示商品,使用数据库存储及索引数据,最终对数据库中数据进行近似最近邻(ANN)搜索。这些向量表示是通过深度学习模型获取的,而这些深度学习模型基于用户和产品或服务之间的交互进行训练。使用计算机视觉算法或语言模型,还可以从各种数据模态(例如图像、视频或产品与用户的文本描述)中生成向量表示。获取向量表示后便迎来关键步骤——对数十万甚至数百万/数十亿的向量嵌入数据集(例如电商库存产品 embedding)进行高效的 top-k(即 k 个最相似)搜索。
NVIDIA Merlin (https://github.com/NVIDIA-Merlin) 是一个开源框架,用于训练端到端模型,从而为各类规模的数据生成推荐,轻松集成高效的向量数据库索引和搜索框架。而 Milvus 作为大模型时代备受关注的向量数据库可以提供高效索引和查询功能。
最近,Milvus (https://zilliz.com/what-is-milvus)新增支持 NVIDIA GPU 加速 https://github.com/milvus-io/milvus/releases/tag/v2.3.0,可提升查寻的并发和速度,这对于现代推荐系统十分有用。截至 2023 年 10月,Milvus 获得了 689 万次 docker pull 及 2.3 万颗 GitHub Star,被业界广泛应用 https://zilliz.com.cn/blog?tag=4。
接下来,我们将演示 Milvus 如何与 Merlin RecSys 框架集成、Milvus 如何在项目检索阶段与高效的 top-k 向量搜索技术相结合以及如何在推断时使用 NVIDIA Triton Inference Server (TIS)。根据 NVIDIA 性能测试结果显示:使用 Merlin 模型生成向量并使用 GPU 加速版的 Milvus 可以将搜索速度提升 37 至 91 倍。我们使用的 Merlin-Milvus 集成代码和详细性能测试结果均可在 (https://github.com/bbozkaya/merlin-milvus/tree/main)处获取。
![]()
图1|Milvus 框架为多阶段推荐系统的检索阶段做出贡献。(原始多阶段图的来源:https://medium.com/nvidia-merlin/recommender-systems-not-just-recommender-models-485c161c755e)
由于推荐系统具备的多阶段的性质以及各种组件和库的可用性问题,其主要挑战就是在端到端流程中无缝集成所有组件,因此我们的目标是在示例 notebook 中尽可能简化集成工作。
另一个挑战是加速整个推荐流程。虽然加速在训练大型神经网络中扮演着重要的角色,但 GPU 是在近期才被添加到向量数据库和 ANN 搜索领域中的。随着电商库存产品、流媒体等数据规模爆炸式增长和用户数量的井喷,CPU 从性能上而言已经无法满足服务数百万用户的推荐系统的需求。为了解决这个挑战,需要在流程的其他部分进行 GPU 加速。本文提出的解决方案展示了 ANN 搜索时使用 GPU 加速可以有效解决这一问题。
现在,介绍一下即将用到的技术栈。
首先需要一个推荐系统框架作为基础,本例中我们使用 NVIDIA Merlin https://github.com/NVIDIA-Merlin/Merlin,因为这个开源库提供在 NVIDIA GPU 上加速推荐系统的高级 API (high-level API)。Merlin 可以助力数据科学家、机器学习工程师和研究人员构建高性能推荐系统。除了 Merlin 以外,本例中还使用了以下开源工具/库:
-
NVTabular:用于预处理输入表格数据和特征工程 https://github.com/NVIDIA-Merlin/NVTabular。
-
Merlin Models:用于训练深度学习模型,从用户交互数据中学习获取用户和商品向量 https://github.com/NVIDIA-Merlin/models。
-
Merlin Systems:用于集成基于 TensorFlow 的推荐模型与其他组件(例如特征存储、Milvus 的 ANN 搜索功能),以便在 TIS 中提供服务 https://github.com/NVIDIA-Merlin/systems。
-
Triton Inference Server:用于在推断阶段传递用户特征向量并生成产品推荐 https://github.com/triton-inference-server/server。
-
容器化:上述所有内容都可以在 NVIDIA 提供的 NGC 目录(https://catalog.ngc.nvidia.com/)中获取。本例使用 Merlin TensorFlow 23.06 容器(https://catalog.ngc.nvidia.com/orgs/nvidia/teams/merlin/containers/merlin-tensorflow) 。
-
Milvus 2.3:用于启用 GPU 加速的向量索引和查询 https://github.com/milvus-io/milvus/releases/tag/v2.3.0。
-
Milvus 2.2.11:与上述相同,但在 CPU 上执行向量索引和查询 https://github.com/milvus-io/milvus/releases。
-
pymilvus SDK:用于连接 Milvus 服务器、创建向量数据库索引并通过 Python 接口运行查询命令。
-
Feast:用作端到端 RecSys 流程中保存和检索用户、商品向量的(开源)特征存储 https://github.com/feast-dev/feast。
此外,我们还用到了许多底层库和框架。例如,Merlin 依赖于 cuDF 和 Dask 等其他 NVIDIA 库,这两个库均可在 RAPIDS cuDF (https://github.com/rapidsai/cudf)中获取。同样,Milvus 依赖于 NVIDIA RAFT (https://github.com/rapidsai/raft)实现 GPU 加速,HNSW 和 FAISS 等进行搜索。
02.
了解向量数据库
ANN 搜索是关系型数据库无法提供的功能。关系型数据库只能用于处理具有预定义结构、可直接比较值的表格型数据。因此,关系数据库索引也是基于这一点来比较数据。但是 Embedding 向量无法通过这种方式直接相互比较。因为我们不知道向量中的每个值代表什么意思,无法使用关系型数据库来确定一个向量是否一定小于另一个向量,唯一能做的就是计算两个向量之间的距离。
如果两个向量之间的距离很小,可以假设它们所代表的特征相似;如果距离很大,可以假设它们代表的数据十分不同。对我们而言,向量距离及其含义是有用的。我们可以创建索引结构,高效搜索这些数据。但是为向量数据构建索引也有不小挑战:计算两个向量间距离成本高昂,而且向量索引一旦构建完成后,不易于修改。因此,我们无法直接使用传统的关系型数据库来处理向量数据,需要使用专为向量数据而打造的向量数据库。
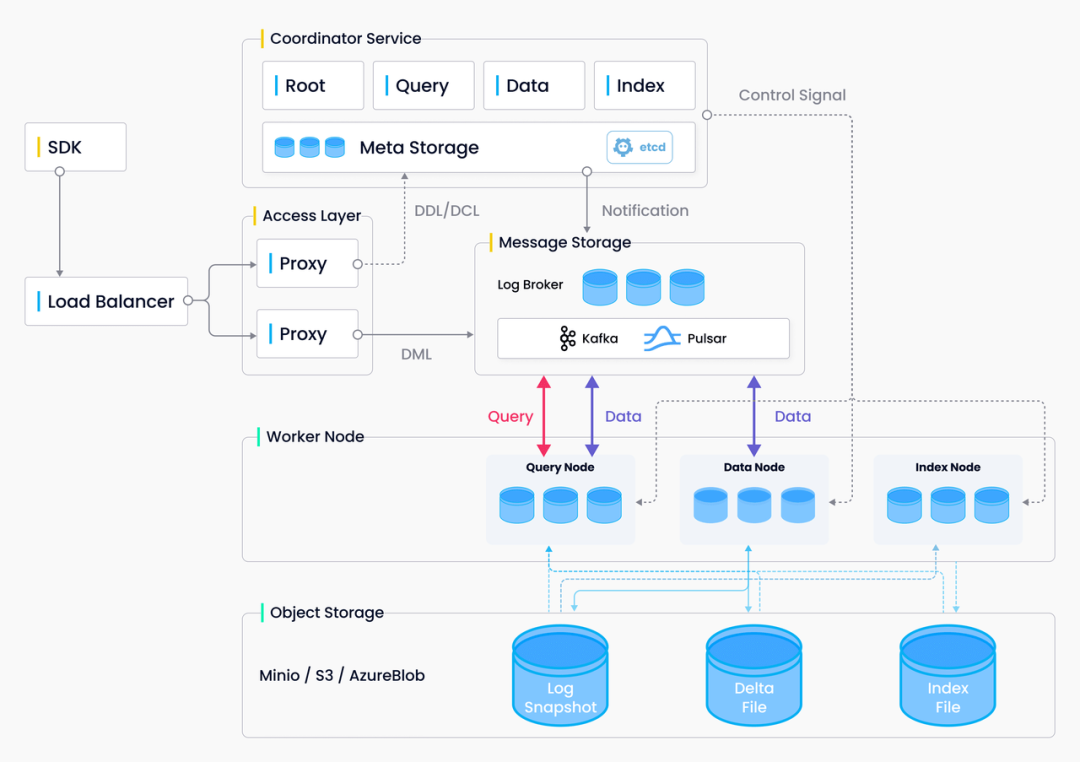
Milvus 是一款专为向量数据处理而设计的向量数据库,可以解决传统关系型数据库无法处理向量的问题,为海量向量数据高效构建索引。为了满足云原生的要求,Milvus 将计算和存储以及不同的计算任务(查询、数据处理和索引)分离开来。用户可以根据不同的应用灵活扩展每个组件。无论是数据插入密集型应用还是搜索密集型应用, Milvus 都能够轻松应对。如果有大量插入请求涌入,用户可以临时水平和垂直扩展索引节点以处理数据。同样,如果没有大量插入数据,但有大量搜索操作,用户可以减少索引节点的数量,并提高查询节点的吞吐量。Milvus 的系统架构设计(见图2)采用并行计算的思维方式,助力我们进一步优化本例中的推荐系统应用。
![]()
图2|Milvus 架构设计
此外,Milvus 还整合了许多最先进的索引库,以便为用户提供尽可能多的系统自定义功能。稍后,我们将讨论这些索引的区别以及各自的优缺点。
大多数向量索引可以分成两种类型——聚类和图。IVF 是聚类类别中的一种算法,它使用 k-means 来计算最近邻的聚类。然后,将查询向量与最近的质心聚类进行比较,并在搜索时进行搜索。HNSW、DiskANN 和图类别中的其他基于图的算法主要围绕着导航扩展图进行搜索,这些图在 ANN 搜索时效率更高。但是图算法往往也更加复杂。如果大家对此感兴趣,可以阅读(https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW)。
除了上述这些算法,还有一类叫做乘积量化 (PQ) 的算法。PQ 是一种将向量数据压缩以减少资源使用并提高性能的方法,但其代价是降低召回率/准确性。该领域中的大多数算法都是量化的变体,以允许降低内存使用或提高其方法的性能。
所有这些算法和组合之间的区别是什么?为什么有这么多算法呢?它们之间的区别在于性能、召回率和内存使用之间的权衡。例如,IVF_FLAT 索引是一个平衡了上述 3 个方面的索引,可以在不过多增加内存开销的情况下以较快的速度获得良好的结果。基于压缩的索引,如 IVF_SQ8 和 IVF_PQ,在速度和减少内存使用方面更强大,但根据所使用的压缩级别,会降低召回率。HNSW 则以性能和召回率为目标,但代价是内存消耗。与其他索引相比,DiskANN 是最独特的,因为它是一种基于磁盘的索引。前面的索引都完全存储在内存中,需要大量的 RAM。DiskANN 只在内存中保存少量索引数据,并将大部分数据保存在磁盘存储器中,这样可以大大减少内存使用量,同时仍然保持较高的召回率。但是,使用 DiskANN 会降低吞吐性能,并且根据所使用的 SSD 类型,会影响延迟性能。
如今,并非只有大型用户/公司才能访问非常大的数据集,小型用户可能会从其数据中生成数十亿个向量,并需要以最经济的方式进行搜索。相比之下,大型用户有时虽然只有几十万个数据,但每秒需要处理数万个查询。为了解决这些问题,索引层面提供很多定制化的参数来支持不同的用例。更多详情,请访问 (https://milvus.io/docs/index.md)查看。
对于大多数用户来说,GPU 索引是获得所需性能的关键。GPU 索引提供了许多用例所需的高吞吐量,同时从长期而言可以节省成本。
构建和搜索索引主要依赖向量化计算,可以在 CPU 上完成,但使用 GPU 效率大大提升。Milvus 将搜索计算迁移到 GPU 后,查询每秒 (QPS) 的性能提高了 37 至 91 倍,性能提升非常显著。想要获得如此大的性能提升的唯一其他途径就是扩展集群规模。但是这种方式开销较大。通过使用 GPU,用户可以提升性能的同时简化集群,减少额外节点和调度开销。
然而,基于 GPU 的搜索有一个限制,那就是低并发情况。Milvus 对高并发有优化,会尝试合并查询并一起做主存和 GPU 内存的搬移,来降低单个查询需要的搬移次数。在低并发情况下,GPU 的延迟较大,因为 CPU 可以比将数据传输到 GPU 再从 GPU 传回的时间内更快地完成搜索。
03.
示例
我们提供的示例演示了在商品检索阶段如何集成 Milvus 与 Merlin,其中用到了来自 RecSys Challenge 2015 的真实数据集进行训练。同时,我们也训练了一个双塔深度学习模型,用于学习用户和商品向量。在本章节的最后,我们还会提供一些性能测试相关的信息,包括在性能测试过程中观察的指标和使用的参数范围。
在集成和性能测试时,我们使用了由 YOOCHOOSE GmbH 在 RecSys Challenge 2015 中提供的数据集,可在 Kaggle 上下载。这个数据集中包含了欧洲在线零售商提供的用户点击/购买事件,其中包括与点击/购买相关的会话 ID、时间戳、商品 ID和商品类别等信息。这些内容均可在文件yoochoose-clicks.dat中获取。各个会话都是独立的,不考虑回购用户的情况。因此我们将每个会话视为属于不同用户的会话。该数据集包含 9,249,729 个会话(用户)和 52,739 个商品。
工作流程主要包括:a) 数据获取和预处理。b) 搭建双塔深度学习模型,训练数据。c) 在 Milvus 向量数据库中创建索引。d) 在 Milvus 向量数据库中进行向量相似性搜索。接下来,我们会简要描述每个步骤,如果大家对每个步骤的详情感兴趣,请参考 (https://github.com/bbozkaya/merlin-milvus/tree/main/notebooks)。
用 NVTabular(https://github.com/NVIDIA-Merlin/NVTabular)对数据进行预处理。这个工具利用了 Merlin 的 GPU 加速能力,是高度可扩展的特征提取和预处理组件,能够帮助我们轻松处理 T 字节级别的数据集、搭建训练基于深度学习的推荐系统。
NVTabular 经过抽象,提供一套简化的代码,使用 RAPIDS 的 Dask-cuDF(https://github.com/rapidsai/dask-cudf) 库在 GPU 上实现加速计算。用 NVTabular 将数据读入 GPU 内存,并按需重新排列特征,最终导出为 Parquet 文件。最终得到了 7,305,761 个用户向量和 49,008 个商品向量以供后续训练使用。在预处理时,我们还会将每列数据和值进行分类,转换为整数值。
用双塔 https://github.com/NVIDIA-Merlin/models/blob/main/examples/05-Retrieval-Model.ipynb深度学习模型来生成用户和商品向量,随后为这些向量创建索引并查询向量。我们将用户属性(user_id, user_age)和商品属性(item_id, item_category)输入到 Two-Tower 模型中。这个过程中,可以选择是否要包含一个目标列,只包括具有正交互作用的行。模型训练完成后,提取学习到的用户和商品嵌入向量。
接下来是两个可选步骤:
1. 使用 DLRM(https://arxiv.org/abs/1906.00091) 模型对检索到的商品进行排序。
2. 使用特征存储(在本例中为 Feast)存储和检索用户和商品特征。在本示例中,加入了这两个步骤从而更为完整地展示推荐系统的多阶段工作流程。
最后,将用户和商品向量导出为 parquet 文件,稍后可以重新加载并为其在 Milvus 中创建向量索引。现在,可以启动 Milvus 服务器并上传商品向量、创建向量索引。然后,在推理时使用NVIDIA TIS 和自定义的 Merlin 系统 Operator 对现有用户和新用户进行相似性搜索查询。请参见 notebook 中的第二个示例。
Milvus 通过在推理机上启动一个服务来实现向量索引和相似度搜索。在 notebook 2 中,我们通过 pip 安装了 milvus 服务器和 pymilvus,然后使用默认的监听端口启动了服务器。接下来,我们将演示如何使用两个函数 setup_milvus 和 query_milvus 来构建一个简单的索引 (IVF_FLAT) 并对其进行查询。
当我们将相同任务作为 TIS 框架中的多阶段推理的一部分完成时,事情变得更有趣了。Merlin 提供了一个高级 API,Merlin Systems,允许将推荐系统的不同阶段组合成一个单独的链式“集成模型”。因此,上述所有阶段都在对 TIS 发送的单个请求中执行。在这里,我们实现了一个自定义的 Merlin Systems 操作符作为集成的一部分,名为 QueryMilvus。
细心的朋友可以已经注意到,pymilvus 库没有使用 GPU 加速,而 NVTabular 和 Merlin Models 却使用了 GPU。这是因为 Milvus 的 GPU 加速版本需要启动多个容器,而我们使用的 Merlin 容器不支持这样做。相反,通过 pymilvus,在 notebook 所在的同一个容器中将 Milvus 服务器作为一个进程启动。要在 GPU 上运行 Milvus,可以参考最新的 Milvus 发版说明(https://github.com/milvus-io/milvus/releases/tag/v2.3.1)。下面性能测试是在 GPU 上完成的,使用的是 Milvus 最新版。
为了证明使用快速高效的向量索引/搜索库(如 Milvus)的必要性,我们设计了两组性能测试:
-
使用 Milvus 构建向量索引,我们生成了两组向量:1)针对 730 万个用户向量,按照 85% 的训练集(用于索引)和 15% 的测试集(用于查询)进行划分;2)针对 4.9 万个商品向量,按照 照 50% 的训练集(用于索引)和 50% 的测试集(用于查询)进行划分。性能测试针对每个向量数据集独立进行,生成独立的结果。
-
使用 Milvus 构建一个针对 4.9 万个商品向量数据集的索引,并基于该索引使用 730 万个用户向量进行相似性搜索。
在性能测试中,我们使用了 GPU 和 CPU 版的 IVF_PQ 和 HNSW 索引算法,并尝试了各种参数组合。详细信息请参见 (https://github.com/bbozkaya/merlin-milvus/tree/main/results)。
在生产环境中,一个重要的性能考量指标是搜索质量和吞吐量之间的平衡(tradeoff)。Milvus 允许完全控制索引参数,以探索这个 tradeoff,以达到与基准结果相关的更好搜索结果。这可能意味着减少吞吐量或每秒查询数(QPS),增加计算成本。我们使用召回率指标来衡量 ANN 搜索的质量,并提供了 QPS-召回率 曲线来展示 tradeoff。然后,您可以根据计算资源、延迟/吞吐量需求来决定可接受的搜索质量水平。
还请注意我们基准测试中使用的查询批处理大小(nq)。这在工作流中非常有用,其中会同时向推理发送多个请求(例如,将离线推荐请求发送给一系列电子邮件收件人,或者通过汇集并同时处理到达的并发请求生成在线推荐)。根据具体情况,TIS 还可以帮助以批处理方式处理这些请求。
04.
结果
以下展示基于 CPU 和 GPU 的 3 组性能测试结果。该测试使用了 Milvus 的 HNSW(仅 CPU)和IVF_PQ(CPU 和 GPU)索引类型。
对于给定的参数组合,将 50% 的商品向量作为查询向量,并从剩余的向量中查询出 top-100 个相似向量。我们发现,在测试的参数设置范围内,HNSW 和 IVF_PQ 的召回率很高,分别在 0.958-1.0 和 0.665-0.997 之间。这表明 HNSW 在召回率方面表现更好,但是 IVF_PQ 在 nlist 较小的情况下也能得到非常高的召回率。此外,召回率的值随着索引和查询参数的变化也会发生很大的变化。报告结果在对一般参数范围进行初步实验并进一步深入选择子集之后获得的。
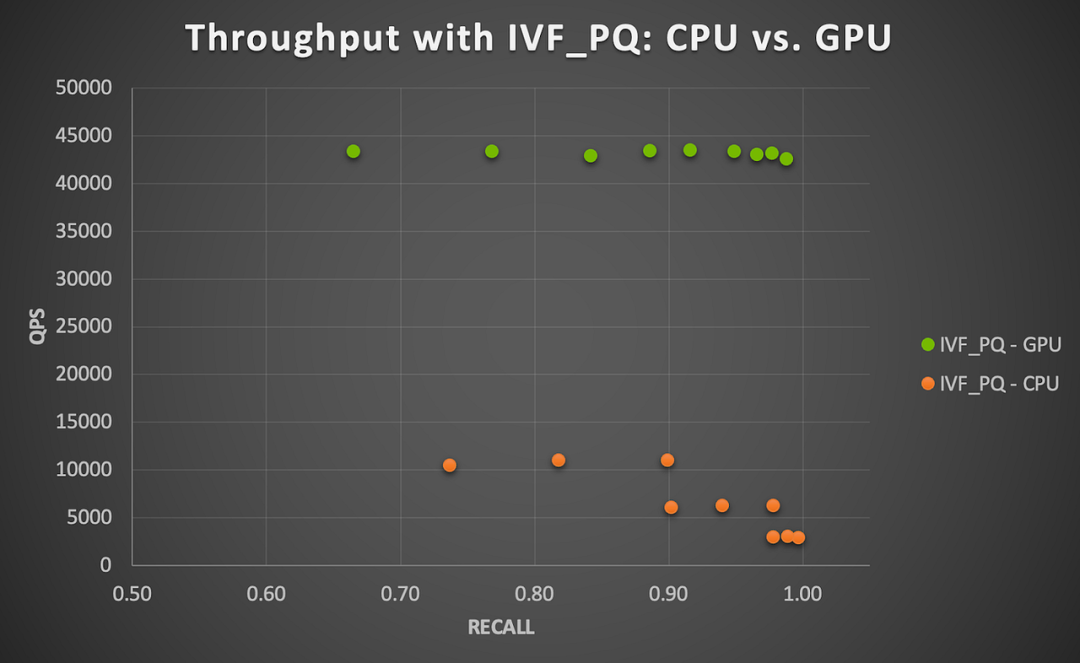
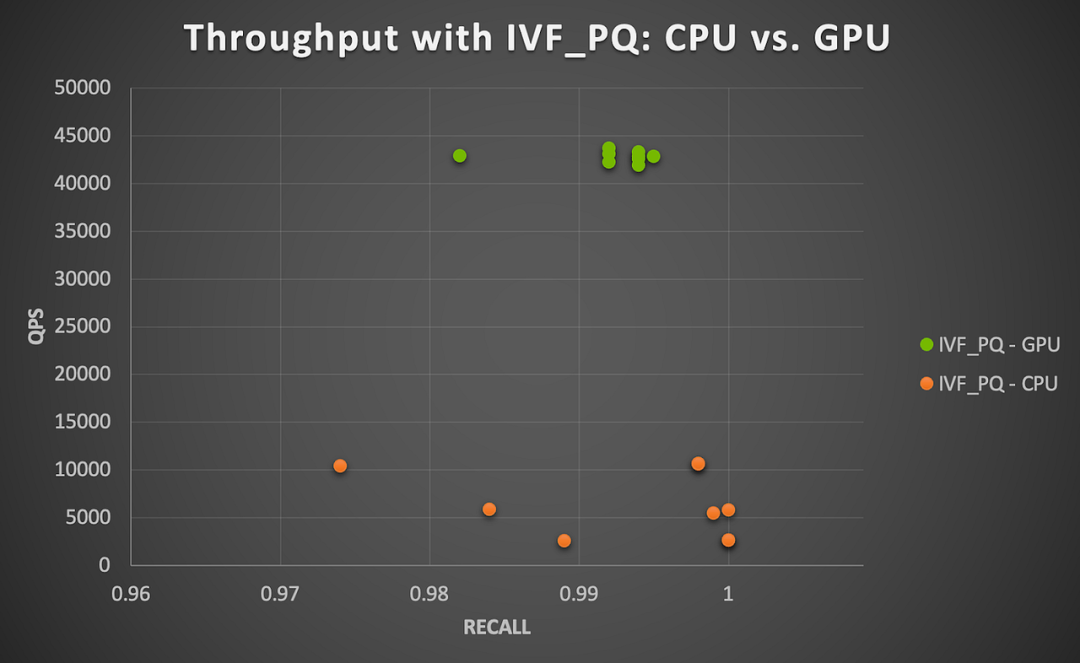
在给定参数组合下,使用 HNSW 在 CPU 上执行所有查询的总时间范围在 5.22 到 5.33 秒之间(在 ef不变的情况下,随着 m 的增大而更快),而使用 IVF_PQ 在 13.67 到 14.67 秒之间(随着 nlist 和 nprobe 的增大而变慢)。如图 3 所示,GPU 加速确实效果更明显。
图 3 显示了在 CPU 和 GPU 上,使用 IVF_PQ 和这个小数据集时召回率和吞吐量之间的 tradeoff。我们发现,GPU 在所有测试的参数组合下都实现了 4 到 15 倍的加速(随着 nprobe 的增大而加速更明显)。这个结果是比较每个参数组合下 GPU 的每秒查询数与 CPU 的每秒查询数得出的。总体而言,这个小数据集对于 CPU 或 GPU 来说都很容易处理,而且不难看出,还有进一步加速空间。
![]()
图3|在 NVIDIA A100 GPU 上运行 Milvus IVF_PQ 算法的 GPU 加速(商品与商品相似性搜索)
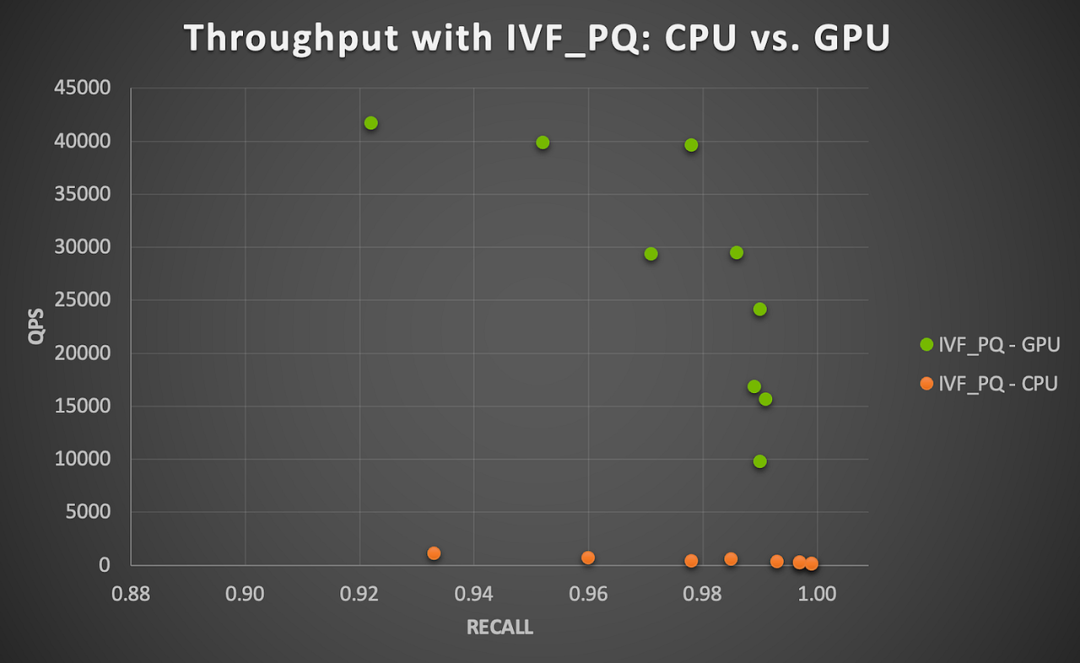
对于更大的第二个数据集(730 万个用户),我们将 85%(约 620万个)的向量用于“训练”(要建立索引的向量集),剩下的 15%(约 110 万个)作为“测试”或查询向量集。在这种情况下,HNSW 和 IVF_PQ 表现非常出色,召回率分别为 0.884-1.0 和 0.922-0.999。然而,它们在计算上要求更高,尤其是在 CPU 上使用 IVF_PQ 的情况。使用 HNSW 在 CPU 上执行所有查询的总时间范围为 279.89 至 295.56 秒,而使用 IVF_PQ 的总时间范围为 3082.67 至 10932.33 秒。注意,这些查询时间是对 110 万个向量进行查询的累积时间,因此可以说针对索引的单个查询仍然非常快。然而,如果推理服务器要对数百万个商品并发请求运行查询,不推荐使用 CPU 查询。
使用 IVF_PQ 和 A100 GPU 时,吞吐量(QPS)提升 37 至 91倍 (平均为 76.1 倍)。这与我们在小数据集中观察到的结果一致,这表明处理数百万向量数据时,Milvus 结合 GPU 加速可以大幅提升性能。
![]()
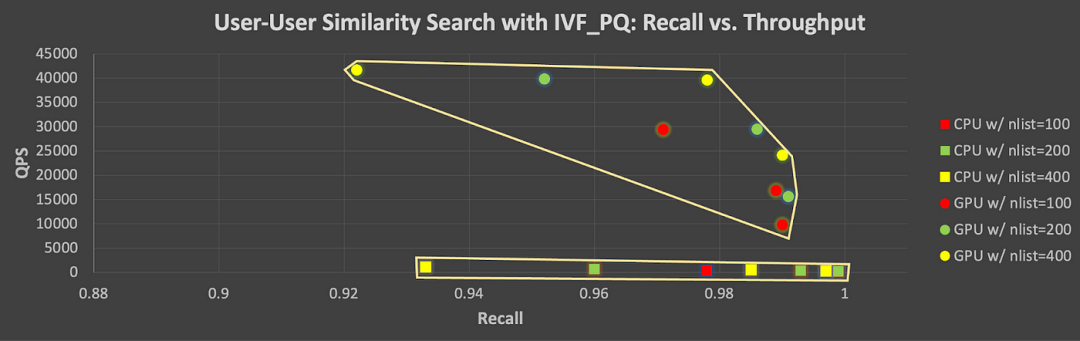
图4|在 NVIDIA A100 GPU 上运行 Milvus IVF_PQ 算法的 GPU 加速比(用户-用户相似性搜索)
此外,图 5 显示了在 CPU 和 GPU 上使用 IVF_PQ 测试的所有参数组合的召回率-QPS tradeoff。该图中每个点(上为GPU,下为 CPU)展示了在改变向量索引/查询参数时召回率和吞吐量的 tradeoff:更高召回率的代价是较低吞吐量。注意,在使用 GPU 的情况下,提高召回率时,QPS 会大幅降低。
![]()
图 5|在 CPU和 GPU 上使用 IVF_PQ 进行测试的参数组合及其召回率-吞吐量tradeoff(User vs. User)。
最后,考虑另一个现实场景,即将用户向量与商品向量进行比较(如上面的 notebook 1 所示)。在这种情况下,我们为 49000 个商品向量创建索引,为每个用户向量查询其 top-100 最相似的商品。
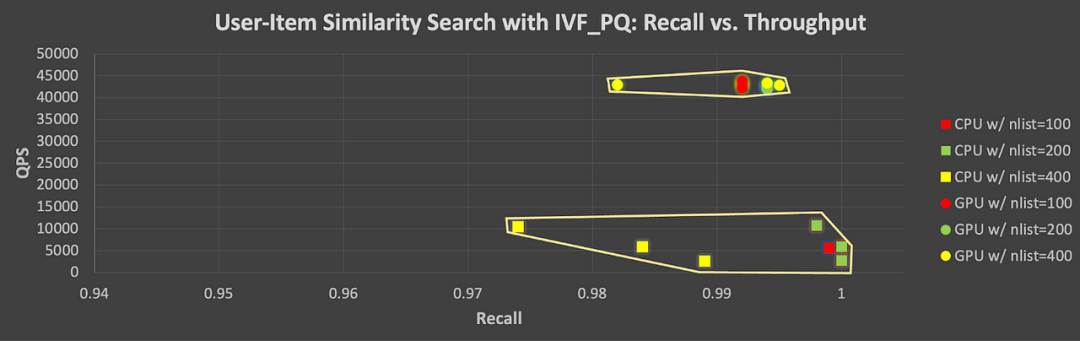
在 CPU 上进行向量批量查询非常耗时,无论是使用 HNSW 还是 IVF_PQ 索引(请参见图 6)。而 GPU 在这种情况下表现更好。当 nlist = 100 时,IVF_PQ 在 CPU 上平均计算时间约为 86 分钟。但计算时间随着 nprobe 值的增加而变化很大(当 nprobe = 5 时为 51 分钟,而当 nprobe = 20 时为 128 分钟)。NVIDIA A100 GPU 能够将性能提升了4 至17倍(当 nprobe 较大时,速度提升更高)。前文也提到,通过其量化技术,IVF_PQ 算法还可以减少内存占用。这样看来,如果结合 GPU 加速方案,能够得到一个计算上更可行的 ANN 搜索解决方案。
![]()
图6|在 NVIDIA A100 GPU 上运行 Milvus IVF_PQ 算法的 GPU 加速比(用户-商品相似性搜索)
与图 5 类似,图 7 显示了使用 IVF_PQ 测试的所有参数组合的召回率-吞吐量间的 tradeoff。我们仍然可以看到在 ANN 搜索中,为了提高吞吐量,可能需要稍微牺牲一些准确性,尤其是在使用 GPU 的情况下。也就是说,我们可以在 GPU 的计算性能上保持相当高的水平,同时实现高召回率。
![]()
图7|使用 IVF_PQ 索引在 CPU 和 GPU 上测试的所有参数组合及其对应召回率-吞吐量 tradeoff(用户 vs 商品)。
05.
结论
最后,和大家分享一些思考。
现代推荐系统复杂和多阶段的特质对每个环节的性能和效率都有很高的要求。因此,大家可以考虑在推荐系统流程中使用以下两个关键功能:
![]()
上述测试结果表明,本文所提出的 Merlin-Milvus 集成方案在训练和推理方面都非常高效且比其他方案更简单。而且,这两个框架都在积极开发中,每个版本都会添加许多新功能,例如,Milvus 新增了基于 GPU 加速的向量数据库索引。向量相似性搜索是计算机视觉、大语言模型系统、推荐系统等工作流程中的关键组成部分,因此十分推荐大家尝试使用 Milvus 向量数据库。
最后,要感谢 Zilliz/Milvus 和 Merlin 以及 RAFT 团队为完成这个项目和这篇博客文章所做出的贡献。当然,如果大家在自己的推荐系统或其他工作流程中使用了 Merlin 和 Milvus,也欢迎和我们分享。
本文作者