开发部门在做指标加工的全流程中,是否经常出现如下问题:
· 业务部门看指标数据的时候,看到两个名称相似的指标,不清楚两个指标的差异性,来咨询开发部门指标计算口径,开发部门配合业务部门翻找代码,找出指标口径差异性,影响工作效率
![file]()
· 业务部门看指标数据的时候,总会出现不同页面的同一指标统计的结果不一致的问题,业务部门不知道该以哪个数据为准,就会给开发部门提线上问题;开发部门在收到线上问题后,总会花费很多时间去定位任务、翻看代码差异来排查指标口径问题,修复后发布上线,但此时业务的决策进度已经受到了负向影响
· 开发部门基于业务诉求上线了一个新的指标,也在平台A上验证了数据的正确性,但第二天业务部门在平台B上看数据的时候发现了很严重的线上BUG(不产出数据甚至是数据错误),阻塞了业务层工作进展,甚至影响的是客户数据,直接产生了外部客户的客诉行为
出现上述问题,大概率是因为开发部门在指标加工的过程中没有做指标管理,或是指标管理粒度不够。业务初期没有做指标管理问题不大,但随着业务的不断演进,因为指标管理没做好而导致的指标问题就会日益严重,到后期会大到开发每天陷入查线上问题、解线上问题,再产生新的线上问题的恶性循环中。
为了避免后期产生如此严重的问题,在业务发展初期,我们就要做好规范的指标管理,以保证随着业务的不断发展,数据化决策能够成为业务强有力的支撑。本文将为大家详解如何通过袋鼠云指标管理平台DataIndex 进行规范化的指标开发管理,轻松开发指标。
指标问题产生的原因
要想做好指标管理,我们首先需要知道在指标加工过程中,究竟是哪些环节存在问题导致后续会产生指标问题。
指标血缘无法追踪
从需求提出到指标上线应用的全流程,没有做指标加工的全流程跟进。最初的指标需求提出是由其他平台完成,甚至是口头提出,开发过程中只是保证了代码的实现,不考虑前后链路的关联性,导致随着时间的推移,无法追溯需求来源,也不方便追踪指标流向,后期治理起来的成本很大。
以下图为例,2022年销售额数据计算,因某一任务数据计算异常,导致该数据计算结果错误,因无法通过指标血缘查询上游数据变化,导致任务排查速度大大降低。
![file]()
没有统一的地方做指标定义口径的管理
指标口径定义完全依赖开发对表定义、字段定义、表说明、字段说明、代码注释等方式实现,没有额外的地方对指标和表之间的关联关系、生成规则做规范化的记录。或是记录分散在不同的地方,以不规范的方式记录着各种各样凌乱的业务诉求。
以表格文件的方式粗放的记录指标口径
初期的版本记录会相对规范些,但随着指标版本的不断更新,出现了越来越多的文件,产生了越来越多的记录,文件检索与更新都变得十分困难,这种方式也渐渐失去了它本该产生的价值。
同时,随着时间的推移,大量的文件管理也容易产生丢失的情况,导致原本的指标管理问题演化成了文件管理问题。
![file]()
指标重复计算
因为前期没有做好指标管理,指标检索周期长。同时基于业务的紧急程度需要,没时间去查找历史相同指标,就会紧急给业务侧出一个新指标,后续就会出现两个相同的指标在同时运行的情况。
因为不同的业务方正在使用不同的指标表,也不方便做下线或变更处理,只能继续同时运行着,无形中造成了大量人力、资源的浪费。
指标加工过程中耦合严重
一张表同时生成了多个指标,不同的指标又有不同业务层的过滤条件,彼此之间相互影响,牵一发而动全身。导致后期因不确定口径修改的影响点,不能轻易下线指标、修改指标口径,只能通过新增的方式做指标计算,重复指标进一步增加。
如何实现高效指标管理
找到了指标加工问题产生的原因,接下来就是如何通过袋鼠云指标平台DataIndex 来逐个击破难点,实现指标的轻松管理。
第一步:确定全流程需求管理方案
指标需求的来源通常是业务层,业务层的数据需求需要有统一的录入入口,以便后续业务方可以有效跟进需求开发进展,开发部门也可以对需求来源及需求流向有统一的管理。
需求管理过程中主要有四类角色参与:
· 业务方:负责产生需求,在整个需求开发过程中主要做需求答疑、需求结果验收
· 需求管理方:主要负责整个数据管理过程中的制度管理,如:需求的拆解、任务的指派、指标发布审批等,在整个开发过程中起到统筹规划、全局管控的作用
· 指标管理方:通常每个人会负责一个业务域,管理自己业务域下的指标,保障指标的规范定义,是业务方与开发方沟通的重要桥梁。主要负责判定分派的指标任务所属业务域,指标重复性检索、指标口径定义、指标需求评审等,是指标开发方的重要输入来源
· 指标开发方:负责指标的开发落地与任务运维,同时在需求开发过程中配合需求管理方、指标管理方做指标重复性检索与指标口径定义
![file]()
实际生产中,四类角色可以根据实际情况做一定的组合,如需求管理方和指标管理方可以由一人负责,指标管理方与指标开发方可以由一人负责,负责的工作范围则是多个角色工作范围的组合。需求管理的过程就是对这一步步需求流转流程的细化与保障,让整个过程好管、好控、好查、好跟进。
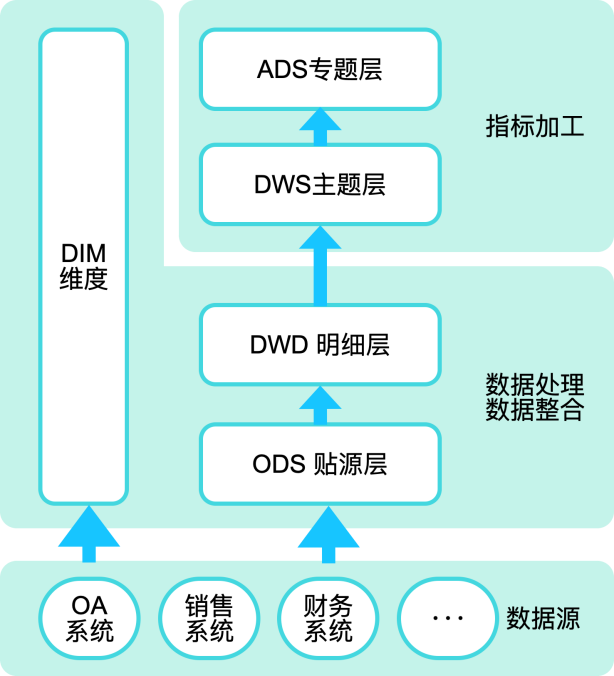
第二步:准备好底层数据
指标管理本质上是面向业务层面的管理,业务层面的频繁更新、不断迭代加工出繁多的指标类数据。所以在进行指标层数据加工前,需要先在 ODS、DWD 层将数据清洗、整合完成。整合后的数据表尽量不会出现因为业务场景/诉求的变化,需要频繁对表结构做变更的情况,指标加工时依赖 DWD、DM 层数据即可。
![file]()
第三步:实现指标平台的冷启动
对历史已有指标做梳理,形成一套指标体系,并落地指标平台,实现指标平台的冷启动。冷启动的过程相对是艰难而痛苦的过程,但梳理好了之后,后续的指标管理就会轻松很多。
这个过程涉及到各方角色的共同参与,梳理历史指标口径,拆分出聚合维度、统计周期、业务限定、通用计算公式,规划好指标目录、描述指标的指标元信息,依次生成数据模型、原子指标、派生指标、复合指标,由系统实现任务的有序调度管理。具体的指标体系设计与加工方案可以参考之前的文章:实用五步法教会你指标体系的设计与加工丨DTVision分析洞察篇
在整个指标加工的过程中,系统也会时刻做好指标的重复性校验,以保障通过指标平台生成的指标不会出现指标重复加工的问题。
第四步:对新需求的规范化承接与落地
当来了一个新的指标需求,首先由需求管理方对需求进行拆解,确定是否是指标需求以及该指标需求是否有对应的已经加工的指标可用,已有的指标可直接匹配,自动完成任务,尚未实现的指标则指派给对应的指标管理方做指标的分析与口径定义。
定义好的指标则由开发进行指标加工与运维,并由指标管理方对开发结果做初步验收,这个过程很多可以通过系统直接实现,如 SQL 生成、任务提交、实例运行等。
最后由需求管理方完成指标的发布上线,根据制度规范校验好配置的指标权限、数据权限,业务方便可进行数据查询,用数据助力自己做后续业务决策。整个指标资源可通过指标市场进行汇总与检索。
![file]()
第五步:让业务通过指标平台实现指标查询与数据分析
业务方可通过袋鼠云指标管理平台自主实现指标看板的搭建、数据临时查询。因整个指标有了规范的加工流程,任务加工过程中存在的断点问题也可以通过指标血缘、任务提示、指标口径比较等快速定位,业务方的决策效率将得到有效保障。
同时,对于上层的业务平台的数据应用与呈现,也可通过 API 轻松实现查询与展示,系统将根据上游指标的更新自动完成下游指标更新甚至 API 的更新,API 调用数据不会再出现不同业务系统数据存在差异的情况。
通过上述五步对指标加工全流程的管理与保障,让曾经不断阻塞业务的难题通过袋鼠云指标管理平台DataIndex 迎刃而解。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack