小时候都被问过一个脑筋急转弯,把大象放进冰箱有几个步骤?我们一开始都会抓耳挠腮,去想着该如何把大象塞进冰箱。最终揭晓的答案却根本不关心具体的操作方法,只是提供了 3 个步骤组成的流程,「把冰箱打开,把大象放进去,再把冰箱关上」。而对于每一位开发者来说,变更数据库字段是绕不过去的操作。而当被问及需要几步时,不少人都会脱口而出 1 步, 不就是执行一条 ALTER TABLE 语句嘛。
这当然不是一道脑筋急转弯题,但确实是一道经典的技术面试题,而答 1 步的同学,基本就挂掉了。实际上,一个标准的数据库字段变更操作需要分成很多步,比如给字段重命名,会分成 6 步:
- 创建一个使用新名字的字段
- 更新应用,同时双写 (dual-write)旧字段和新字段
- 把启动双写前,旧字段的数据回填 (backfill) 到新字段
- 当回填结束后,添加诸如 NOT NULL 之类的约束到新字段
- 更新应用,移除所有对于旧字段的依赖,只使用新字段
- 删除旧名字的字段
以上只是一个大致的执行步骤,而具体的执行细节多到值得许多公司都会单独撰文
![file]()
![file]()
![file]()
有关如何做数据库变更的讨论一直也是 HN 上的热点话题
![file]()
两年多前,Bytebase 的诞生就是来专门解决这个业界难题,两年多过去了,Bytebase 已经形成了一套全面的解决方案,包括:
- 可视化变更
- 批量变更
- 大表在线变更
- 库表同步
- SQL 审核
- GitOps
- 代码 CI/CD 流水线集成
- Schema 漂移检测
- 敏感变更脚本内容脱敏
同时我们也看到行业里有其他队伍加入了进来,从不同的角度来尝试解决这个问题。比如 Neon 基于 CoW 技术的 Branching
![file]()
Xata 基于 Postgres schema 实现的可回滚变更
![file]()
接下来我们会写一系列的文章来拆解一下数据库变更的步骤,并且提供每一个环节的最佳实践。而这第一篇就从数据库变更的三种流程说起。
1. 单步变更 - 和应用一起打包
把对应的数据库变更脚本和应用打包在一起。在应用升级之后的第一次启动时,应用会自查是否针对新版本要变更数据库。如果需要的话,就先执行数据库变更脚本。执行完成后,再启动应用。各种语言的 ORM (比如 Rails 的 Active Record Migrations),还有像 Liquibase, Flyway 这样的工具都提供了类似的能力。
![file]()
如果应用跑在 Kubernetes 上,那么通常在 Pod 启动的过程中,会先通过 init container 来完成数据库的变更,之后再启动 app container。
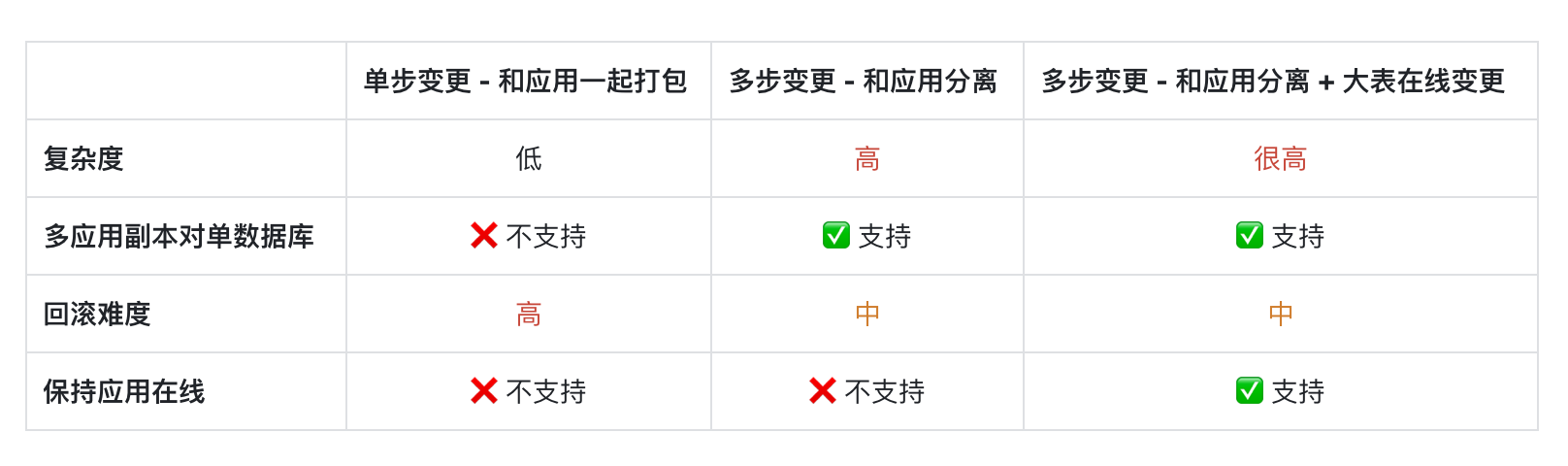
和应用打包在一起的优点是简单,代码只要针对最新的 schema 写就行了,因为启动顺序保证了只有数据库变更到了最新的 schema,才会启动新的应用版本。但这个方案也有不少局限性:
- 不能支持应用副本和数据库多对一的情况,否则在升级过程中,就很难协调到底由哪个副本来变更数据库,无法保证新旧应用版本和数据库 schema 的兼容性。
- 回滚困难,因为变更完后,新版本就直接写到新的数据库结构了。这个时候如果发现升级有问题,回滚的话就要把数据库和应用一起回滚,这可能会造成数据丢失。而如果只是回滚应用的话,则又要考虑旧应用版本和新数据库结构的兼容性问题。
- 如果数据库变更需要比较长的时间,而应用本身不允许长时间的不可用,那么也不能用该方案。
2. 多步变更 - 和应用分离
把数据库的变更和代码的变更分离,通常是先变更完数据库,然后再在之后的某一个时间点升级应用。这个方案增加了复杂度,因为需要应用代码同时支持新旧不同版本的 schema,这通常通过引入特性开关 (feature flag) 来实现,大致上的逻辑
if (version >= 2.0)
// use v2 schema
else
// use v1 schema
这个方案解决了第一种方案的几个问题:
- 可以支持应用副本和数据库多对一的情况,因为数据库的变更是一个单独的流程,不再和应用升级绑定了。
- 减少回滚难度,因为数据库变更完后,如果发现问题,就直接回滚数据库的变更。因为这时新的数据库结构还没有实际使用,所以没有数据库丢失的问题。而应用运行的还是老版本代码,所以只要把数据库回滚到老版本,就也自然没有了兼容性问题。
整个变更流程需要应用侧的配合,就会形成前文提到的 6 步变更。
3. 多步变更 - 和应用分离 + 大表在线变更
但还有 6 步也不够的情况,前面的多步变更方案还有一个问题没有解决,就是如果要变更的表很大,那么变更会持续很长的时间,变更期间的锁表会造成数据库不可用,进而导致整个应用服务不可用。这对于许多在线业务是不可接受的。这个时候就需要一套在线变更的方案,MySQL 里 gh-ost,pt-osc,Postgres 的 Reshape 都提供了相关能力,Bytebase 里面也提供了基于 gh-ost 的可视化大表在线变更。我们后面也会单独撰文介绍大表在线变更。
最佳实践
![file]()
绝大多数在线服务都会结合使用后面两种多步变更的方案,首先是要把数据库变更和应用变更分离。因为在线服务的应用都有多副本,而在应用升级过程中,副本间的版本也是不同的,所以不同版本的应用副本和数据库多对一是刚需。而如果要变更的表很大,还要保证服务在线,就还要使用复杂度更高的大表在线变更。
而无论是何种变更方式,回滚难度都是不低的。因为要处理状态,回滚数据库的难度就是比回滚应用高一个数量级。应对回滚难的策略还是要尽量避免回滚,这个可以通过去改进数据库变更脚本的管理和审核能力。代码管理和审核我们已经有了 GitLab / GitHub 这样的工具和提炼出来的最佳实践,数据库变更审核方面还比较欠缺,这也正是 Bytebase 正在填补的空白,下一篇我们就会来讲一下数据库变更审核 SQL Review,以及集成相关研发工作流的最佳实践。
💡 你可以访问官网,免费注册云账号,立即体验 Bytebase。