什么是移动端BI
维基百科 上对于 移动端商业智能的定义是这样的
> Mobile BI is a system that presents historical and real-time information on mobile devices for effective decision-making and management support. It enables analysis on smartphones and tablets, leading to increased firm performance.
> 移动商业智能是一种在移动设备上展示历史和实时信息的系统,用于有效决策和管理支持。它可以在智能手机和平板电脑上进行分析,从而提高公司业绩
移动端上的数据分析
手机 + BI = 移动端BI ? 从呈现结果上来说是这样的,将数据可视化交互结果通过手机端显示即可。但移动端本身复杂的发展史又在提醒我们,事情未必如此简单。拿最基本的技术实现来说,移动端视图如何处理?(pc、mobile 和平板的呈现布局差异性巨大),移动端的网络请求是否要专门进行优化(一般情况下移动端需要利用有限的网络流量实现指定的需求),是否要开发移动端原生程序,开发运维成本要如何降低? 诸如此类的问题都会导致移动端的数据分析场景需要和 PC 上的数据分析大屏将是两种不同的开发实施策略。换个角度来讲,相比于PC端,如果移动端BI需要增加相应的成本,是否还有必要进行移动端的定制化开发呢,对于公司本身而言,移动端又是否能保证在收益方面的增长会弥补成本上的付出呢。本文就结合移动端数据分析的发展历程来聊聊移动端BI的前世今生。
![]() (图片来源:人人都是产品经理)
(图片来源:人人都是产品经理)
移动端BI的前世今生
早期的移动端数据分析
最开始的移动端商业智能简陋的让人诧异,所有的数据分析信息都是通过短信或者寻呼机来提供的,而且能提供的数据量非常有限,况且没有交互能力。这就导致了通过简短的短信文本拿到的数据价值倒不如直接用打印出来的纸质报表来的方便。这个阶段的移动端数据分析只是一个简陋且昂贵的玩具,鸡肋且体验极差。
![]()
(图片来源:知乎- 第一条短信)
互联网时代的移动端数据分析
经历了早期的短信和呼机时代的移动端数据分析后,进入互联网时代后,移动端分析的舞台便跳转到了web端, 用户可以通过手机浏览器来访问带有数据报表信息的 web 页面, 互联网的打通使得用户可以更便捷快速的获取到数据信息。但是在那个数据流量按 KB/S流通的时代,狭小的设备屏幕,缓慢到让人崩溃的网络服务,过度压缩的展示数据让人们仍然无法对掌间的数据报表提起兴趣。况且那个阶段的移动端浏览器并不成熟,无法满足用户实际的交互需求。
![]()
(图片来源: wikipedia)
移动设备的快速发展
![]()
(图片来源: wikipedia)
随着移动设备迈入了高速发展期,手机屏幕变得更大,可以展示更多信息内容,同时拥有了更灵活的移动交互,用户可以通过设备上的拇指轮和键盘来实现各种数据查询交互。也是在这个时期,商业智能提供商重新进入移动端市场。或通过移动端浏览器访问数据报表(得益于浏览器的不断成熟),或通过专门的原生移动应用程序来获取数据信息, 人们越来越习惯于这种便捷的"口袋数据"。
![]()
(图片来源: wikipedia)
当苹果公司推出了跨时代的产品 Iphone 后, 以一己之力统一了市面上移动设备的通用标准,交互式触摸屏成为了很多手机和平板电脑的标准。紧接着,苹果、安卓系统提供开放的sdk ,支持用户可以自助开发移动设备上的原生应用,整个移动端软件行业都在这次颠覆中重塑了原有的软件交互方式。也从根本上改变了人们在移动设备上使用数据的方式,包括移动商业智能。商业智能应用程序可用于将报表和数据转化为移动仪表盘,并将其即时传送到任意的移动设备上。到目前为止,人们已经习惯于使用移动设备来处理工作生活上的各类信息。移动端BI应用程序早已成为一类专门的商业产品,通过打通业务流程之间的数据孤岛,促进数据流通。每个人都可以通过移动端设备成为数据中心,实时便捷的获取到所有的数据信息。
![]()
移动端数据分析的普及化
总的来说, 移动数据分析的发展历程更像是一台移动设备的历史。正是因为移动设备解决了网络问题,解决了操作易用性问题,解决了生态问题,解决了便携性的问题, 所以才有了今天的智能手机、平板设备。那数据分析呢,或者说,我们是否可以说,因为全球移动互联网用户数达到55亿,基本周围的每个人都在使用移动端设备处理查看数据,所以BI需要强调对移动端的兼容属性?如果明天又诞生了一款替代了移动端的相关设备,那数据分析平台又需要再次强调它在新设备上的兼容情况?我的回答是 "Yes",但和用户使用习惯无关的是,数据分析概念本身也在和移动设备一样从 "特权" 走向 "通用"。
![]()
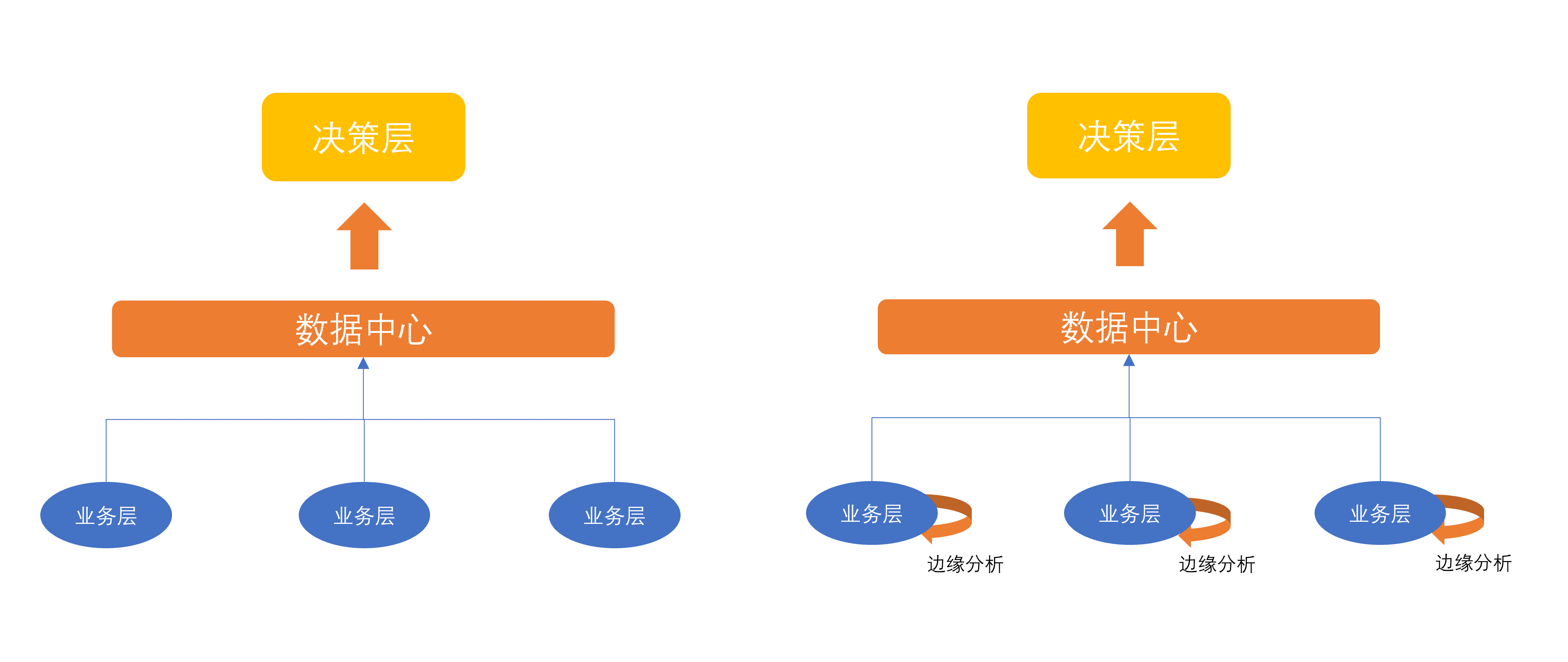
传统商业场景中,BI数据报表作为提供决策层查看的数据依据,需要根据决策者本身对于数据指标的制定和要求,通过IT和业务部门协作来获得实时或者二次统计的业务数据,制作出反映了相关业务指标的数据看板、数据报表。整个数据分析流程是顶层设计、分级汇总,并依此迭代修改的,数据流动方向是从上到下的。但对于目前的实际商业场景来看,我们或许还有不一样的答案。
![]()
从业务视图来说,业务前端应属于数据的产生节点,数据从这里产生,顺着业务系统汇聚到公司层面的数据仓库,最终绘制成决策层眼前的报表,决策层根据报表数据制定接下来的发展策略,然后业务策略一步步再传达到业务前端,重新开始产生反馈新的数据,这是原本的数据循环。但如果我们在业务前端处,也能加入数据分析+数据决策的辅助工作呢? 你会发现数据分析利用的流向发生变化了,整个决策会在前端就进行一部分调整,由自发反馈调整的数据一步步汇整到整个企业中心决策层,由决策层对大的战略层面进一步调整修改。数据流动方向变成了从下到上的,其中双层决策可以保证业务扩展性适应性更强更敏捷。这个思路类比于经常被提到的 "边缘存储","边缘计算" 等概念,我们可以称作边缘分析。在现代多变复杂的业务场景下,边缘分析可以进一步提高决策的敏捷性,极大提高数据的利用率。
APP VS WEB
![]()
即使在大前端如此辉煌的今天,web 应用和 native 应用之间的性能仍然是存在差距的,但 web 端提供的通用适应能力和多终端兼容也是 native 应用所羡艳的,就像 "牧村定律" 一样,通用性和专业性会在不同的阶段往复迭代。如果使用 web 端来构建自己的移动端BI,那将会有如下优势:
- 开发成本低,因为技术栈都是前端方面,需要的开发人员门槛也会有降低。更性价比高的是,一套代码工程就能适配到多终端,极大缩短整个产品周期。
- 嵌入式赋能,web 技术栈最大的优点(缺点?)就是灵活性,完全可以只启动一套 web BI 服务就能服务不同的软件平台,用"赋能"这个词来说,可以实现低成本让整个产品矩阵的数据分析能力全面升级。
- 更新迭代快,同样的开发-部署-实施 的链条节点少了,维护更新周期也会同样的降下来。
那如果是 App 来构建数据分析平台呢
- 性能更强,原生技术带来的性能差异会让使用者的体验感更好。(强是相对来说的,wasm在某些领域已经能和原生性能掰手腕了)
- 离线数据,web 技术最大的特性就是和网络严格绑定,与之相比 APP 在离线场景能缓存部分数据到本地,就可以解决网络不通场景下的数据展示问题。
行业趋势
在实际的使用场景中,还是要根据自己的实际情况来决定哪种技术方案更合适,但实际上还是会存在一些通用性的行业趋势值得用户作为评估因素。
- 自助式, 在前文讲解 移动端bi发展史的时候也提到过, 在初期阶段,用户之所以对 移动端BI 提不起兴趣的很大一点是, 它能提供的信息太过有限,在数据指标展示的灵活性方面完全没有实际的商业价值,更不用提 数据敏捷,数据探索之类的了。所以在选用BI 产品时,自助式探索会是很重要的一点, 从用户侧来讲,可以获取到更多的有用信息。从产品侧来讲,可以节省大量二次开发定制化需求的开发成本。在如今的BI行业中, 自助式也几乎已经成为了行业标准, olap 基本操作中的 筛选、钻取、排序等交互方式也应该作为分析产品的刚需。
- 数据实时更新提醒, 一方面移动端需要在数据实时性方面有保证,让用户能随时能够看到真实的业务状态,另一方面对于提前设定的预警数据要能支持智能预警推送信息,即时提醒等操作。
![]()
总结
从信息化到数字化再到数智化,数字化应用已经从趋势成为当前时,在构建数字化应用时,要结合实际的业务场景选择合适的解决方案。只有了解了各类方案的优劣势才能选择适合自己的最佳实践。
扩展链接:
高级SQL分析函数-如何用窗口函数进行排名计算
3D模型+BI分析,打造全新的交互式3D可视化大屏开发方案
React + Springboot + Quartz,从0实现Excel报表自动化
 (图片来源:人人都是产品经理)
(图片来源:人人都是产品经理)