一、为什么要做稳定性建设
1、从熵增定律引出稳定性建设的必要性
物理学上,用“熵”来描述一个体系的混乱程度。卡尔·弗里德曼提出熵增定律,他认为在一个封闭的系统内,如果没有外力的作用,一切物质都会从有序状态向无序状态发展。
如果我们不希望系统变混乱,有什么办法呢?答案是对抗熵增定律,对抗熵增定律的方法是借助外力,让系统从混乱回归有序。举个例子:
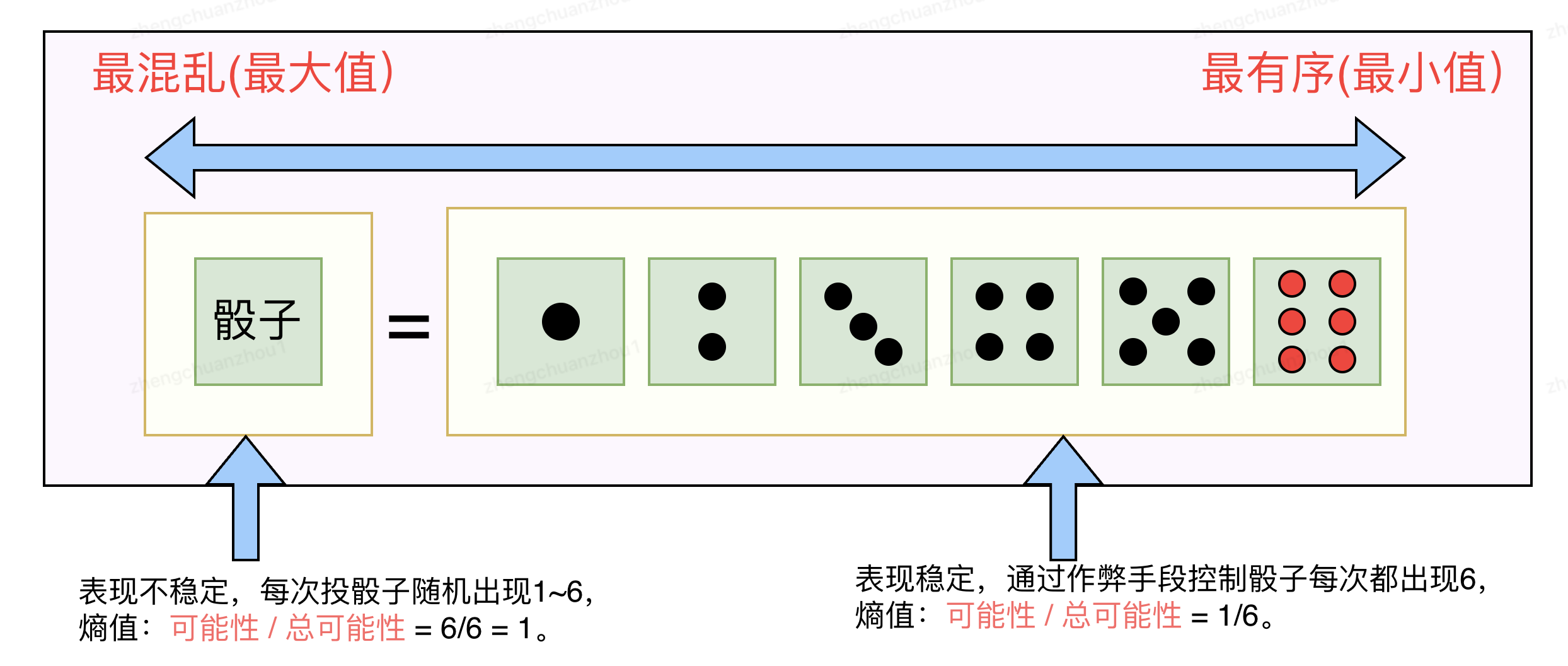
下图中,我们使用“熵”值来衡量“骰子系统”的混乱程度,1(最大值)表示“最混乱”,意味着我们不能控制“投骰子”的结果,每次投骰子的结果会在1~6随机出现,系统表现不稳定;1/6(最小值)表示“最有序”,意味着我们能够控制“投骰子”的结果,系统表现稳定,比如我们希望每次投筛子的结果都是6,我们可以引入作弊手段(即借助外力),让每次投骰子结果都是6。
![]()
熵增定律同样适合软件系统,一个软件系统刚发布时是有序的,熵值趋于1,随着不断迭代,慢慢变成混乱的、脆弱的,从而导致线上问题频发,熵值趋于0,我们需要借助外力,即稳定性治理手段,提高系统熵值,让系统恢复稳定。
2、稳定性建设的意义
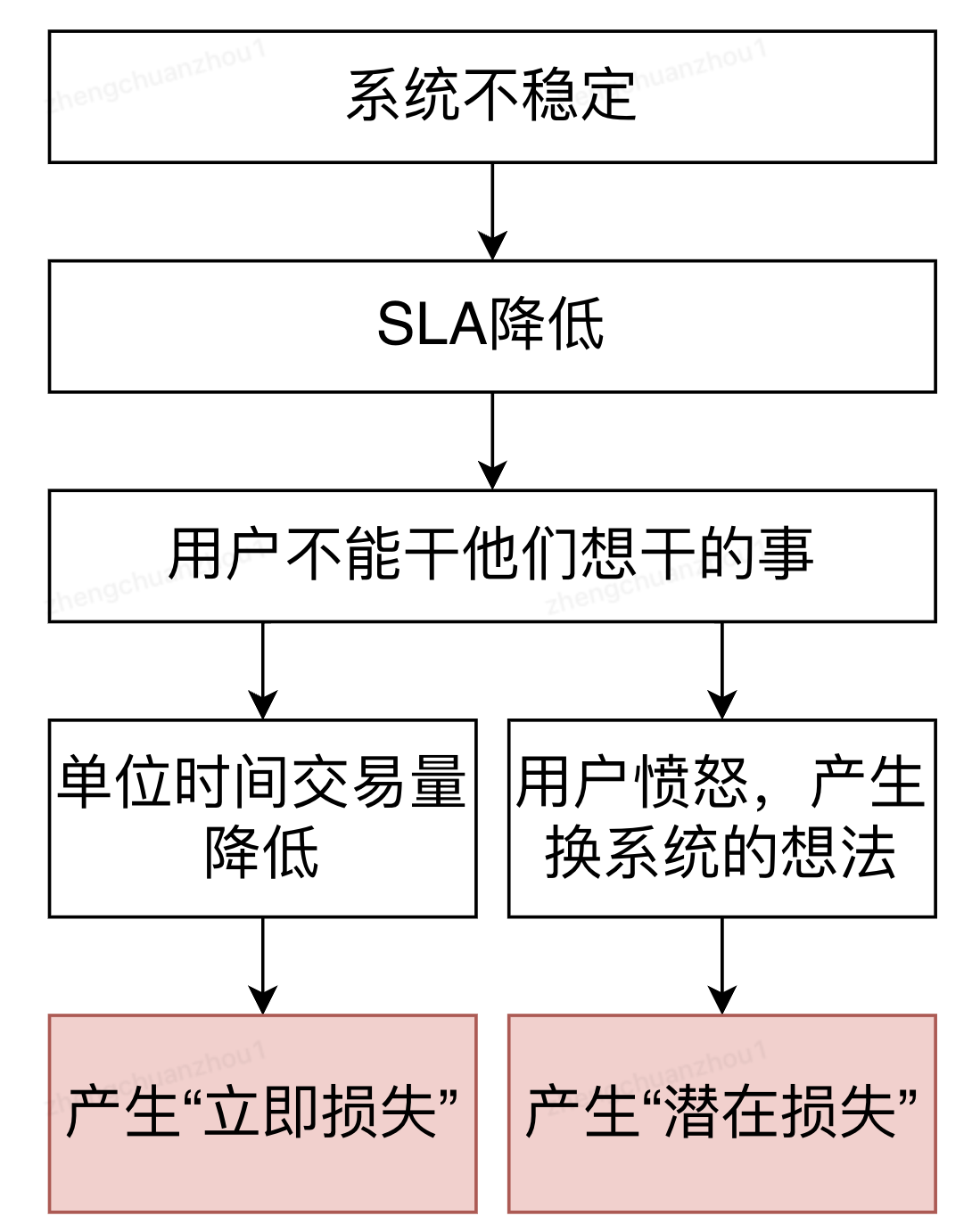
如下图分析,系统不稳定会产生真金白银的损失,因此,稳定性建设的意义是:不是让业务多挣钱,而是让业务不丢钱!
![]()
3、稳定性衡量公式
① 公式
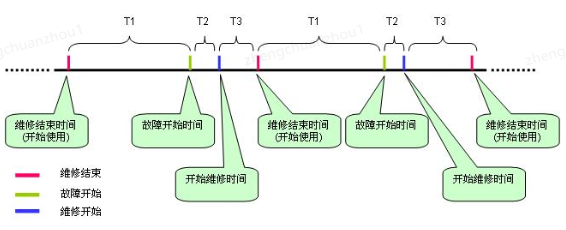
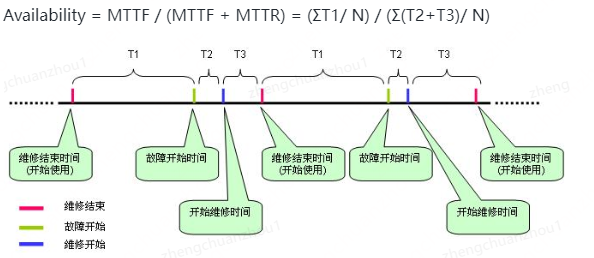
通过如下公式衡量系统稳定性:Availability = MTTF / (MTTF + MTTR) ②公式说明
![]()
MTTF (Mean Time To Failure,平均无故障时间),指系统无故障运行的平均时间,取所有从系统开始正
常运行到发生故障之间的时间段的平均值,即: MTTF =ΣT1/ N。
MTTR (Mean Time To Repair,平均修复时间),指系统从发生故障到维修结束之间的时间段的平均值,即:
MTTR =Σ(T2+T3)/ N。
③公式量化
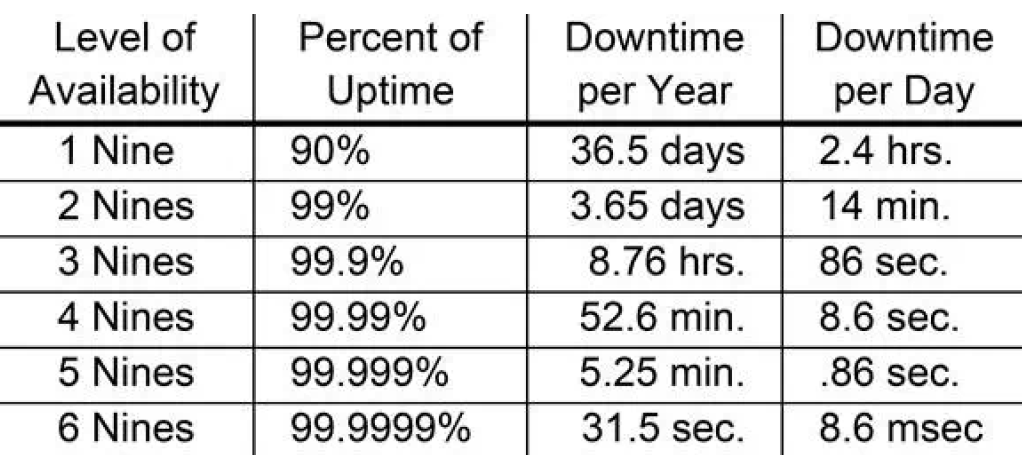
通常是“SLA是几个9”去衡量,对应下表:
![]()
④常见问题
问题:SLA应该按照哪个维度去定义?接口、应用、业务?
答:都可以,只要讲清楚是接口SLA,还是应用SLA,还是业务SLA就可以。但注意:提到应用SLA,应该等于核心接口的最差SLA;提到业务SLA应该等于黄金链路的最差SLA。
问题:SLA时间计算周期应该多少?
答:都可以,主要讲清楚计算周期就可以,一般以年为单位更具代表性。
4、常见误区
①不要认为“分布式环境是稳定的”
认为:网络是可靠的,带宽是无限的,网络的拓扑不会变,延时为0,传输开销为0
实际:网络会抖动,带宽有上限,存在down机导致的拓扑变化,存在响应超时的概率,等等。
②不要有“确定性思维”,要有“不确定思维”
认为:遵守经验法则,if x then y。举例:我见过天鹅是白色的,所以世界上所有天鹅都是白色的;这个系统一直运行良好,所以未来也不会有问题。
应该:世界是不确定的,if x then maybe y。举例:天鹅还有黑色的。
③不要“甩锅”,要有“主人翁精神”
认为:故障是因为他们系统挂了,我们只需要打电话通知一下,慢慢等着恢复就行。
应该:提前思考依赖系统故障了,我们如何让我们用户尽可能的正常运行;故障出现了,共同想办法解决问题。
二、业界现状
1、技术现状
互联网的发展,带来越来越大的流量,为了支撑越来越大的流量,架构也一直在演进:单体应用架构 -> 垂直应用架构 -> 分布式架构 -> SOA架构 -> 微服务架构 -> 服务网格。当前流行的微服务架构中,在应用层面、基建层面上都会有一些保障稳定性的机制:
以SpringCloud全家桶为例,提供了很多组件,帮助我们保障系统稳定性,如下图:
![]()
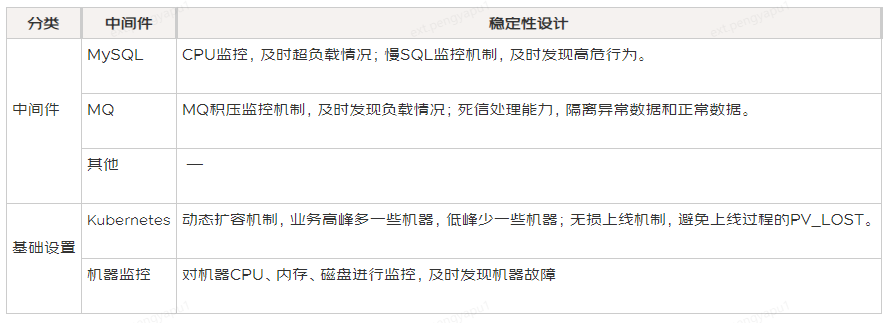
基建层面上,也会有一些稳定性保障机制,如下表:
![]()
2、落地现状
根据所见所闻,当前技术团队做稳定性治理一般采用如下2种方法:
当线上故障频发,通常会搞个“稳定性治理专项”,定义一些治理点,并给出方案,然后运动式的搞一波。一般经过治理后,稳定性会明显好转,但是由于是运动式的搞,随着业务不断迭代,根据“熵增定律”, 稳定性又变差。
缺点:不能闭环的搞,治理时稳定性好转,不治理时稳定性变差,给人感觉技术团队一直出问题。
比如搞个“慢SQL治理专项”,通过监控平台发现慢SQL,给研发发工单,并考核时效;比如搞个“限流治理专项”,让所有接口配置限流参数,配置限流告警策略。
缺点:研发会感觉稳定性专项很多,也不清楚价值,有时候会应付了事,达不到稳定性治理的目标。
三、稳定系治理应该如何开展
将稳定性建设分为3个阶段:事前预防,事中止损,事后复盘,针对这3个阶段,建设思路分别是:
1、事前预防
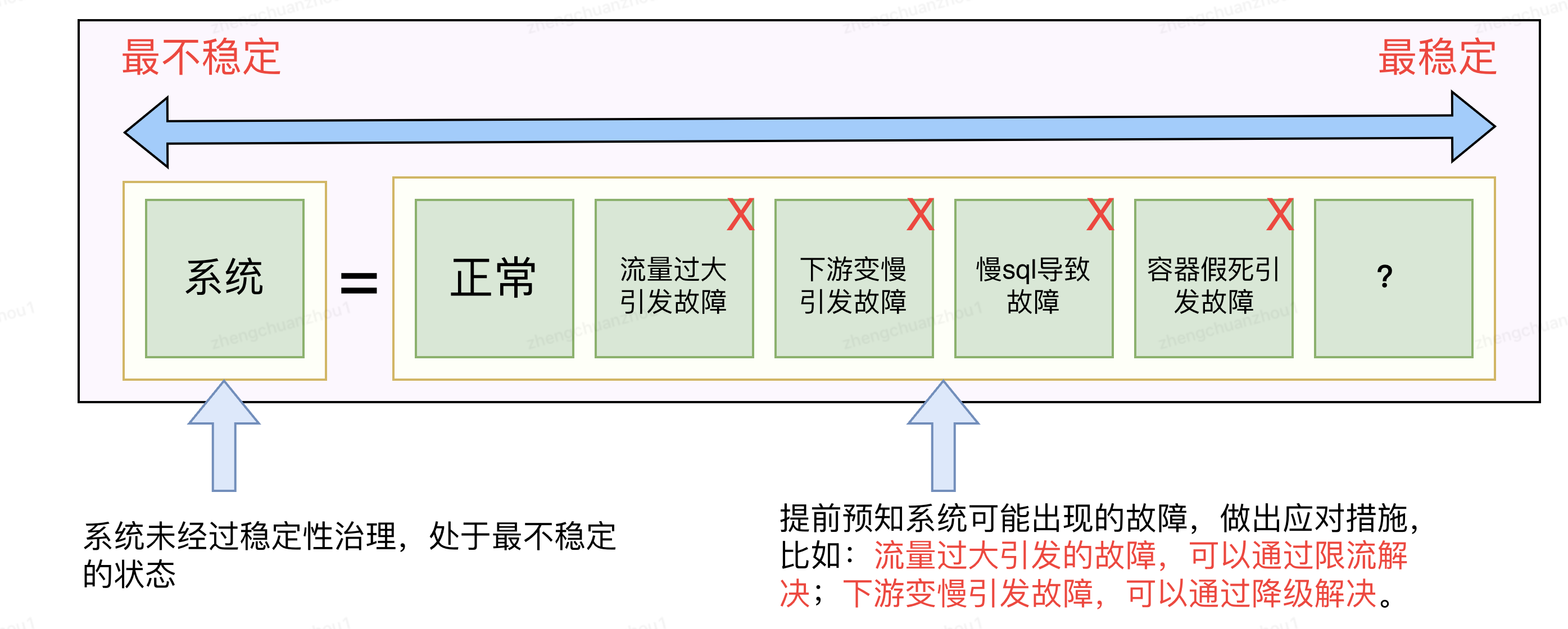
稳定性建设本质上是对抗熵增原理的过程,具体是通过一些技术手段(比如超时治理、限流治理、降级治理、慢SQL等),提前对系统可能出现的故障,建设应对措施,从而让系统按照设计目标去运行。
注意:稳定性治理的手段很多,每落实一种治理手段,稳定性就能提升一点,可以列出所有已知的治理手段,然后按照优先级逐个治理。
![]()
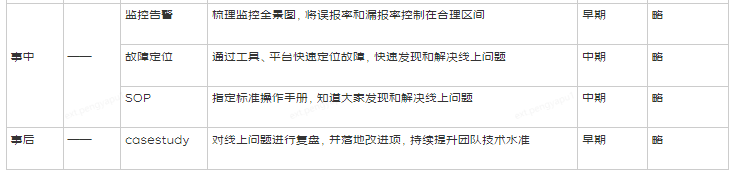
2、事中止损
按照稳定性衡量公式(如下图),降低T2或T3可以提升SLA,因此,出现故障后,应该尽可能的降低T2和T3。降低T2的方法是尽快发现系统出现故障,需要依赖监控和告警能力;降低T3的方法是尽快解决问题,需要先止损后找原因,需要一套明确的SOP提高效率。
![]()
3、事后复盘
复盘的目标不是定责,而是为避免再犯,因此,在复盘过程中要追到直接原因和根本原因,这2者有很大区别:直接原因指的是因果关系,表达“因为干了什么,所以导致什么”;根本原因是流程规范、认知迭代层面的问题,比如“因为分支规范不是master上线,导致上丢代码,如果改用gitflow则能够能够完全避免上丢代码的问题”。
关于直接原因和根本原因的举例:陈胜吴广起义,直接原因是:下大雨,可能会迟到,迟到要杀头,所以造反了;根本原因是:秦朝严苛的制度,即使没有那场雨,即使没有陈胜吴广,也会有下一场雨,下一个张胜某广,因为别的原因进行起义。
四、稳定系治理框架
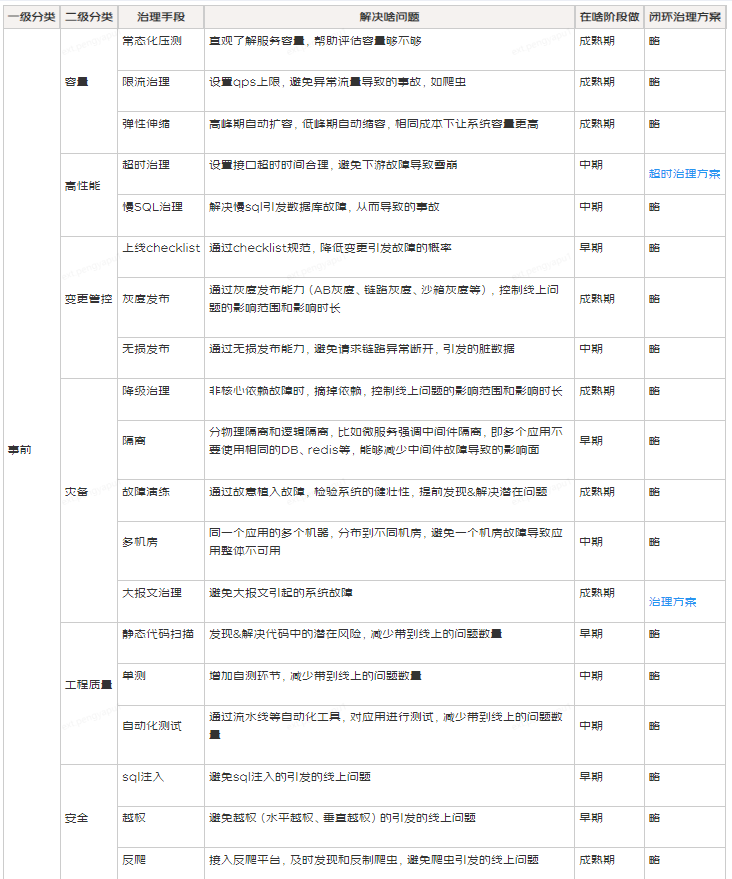
如上一章节所述,当我们从“事前预防,事中止损,事后复盘”的角度去挖掘稳定性治理手段,会发现有很多业界流行的手段,比如超时治理、限流治理、系统隔离、常态化压测、慢SQL治理等等。
然而技术资源永远有限,能够拿出15%的比例做稳定性治理,已经很不错了;另外,业务的不同发展阶段需要的稳定性手段不一样,不同稳定性治理手段的ROI也不一样,因此,我们需要回答一个问题:在有限的研发资源下,如何去按部就班的去搞稳定性治理。
最佳实践是:搭建一个稳定性治理的框架,把稳定性治理手段填充进去,根据业务所处阶段,选择适合当下的稳定性治理手段,可以通过如下的表格进行管理:
![]()
![]()
备注:稳定性治理框架建起来后,治理手段可以随时增加、减少,框架的价值是给我们一个全景图,让我们知道该干什么、在干什么,而不是瞎干。
五、具体治理方案
根据上一章节的稳定性治理框架,接下来要做的就是针对某个治理手段,出具体的治理方案,要求具体方案能够形成闭环,并融入到研发过程中去,比如:
- 定义慢SQL的标准,即执行时间超过多少ms算慢SQL
- 通过监控平台发现慢SQL
- 给研发负责人发治理工单
- 验收治理效果
- 为每个接口定义合适的超时时间
- 每周巡检一次接口,发现超时时间不合理的接口
- 修正超时时间
六、写在最后
稳定性治理是一个长期的过程,要把稳定性的工作融入到研发过程中,一方面要有意识尽量别埋坑,比如微服务强调中间件隔离,我们就不要混用中间件了,另一方面稳定性问题要一步到位,比如治理超时时间,要有个完整规范定义超时时间,并在研发过程中对新增接口、历史接口都配置合理,且能够动态更新。
作者:京东物流 郑传洲
来源:京东云开发者社区 自猿其说Tech 转载请注明来源