开篇
近日,由阿里云计算平台大数据基础工程技术团队主导,与计算平台MaxCompute团队、华东师范大学数据科学与工程学院、达摩院合作,基于预测的云计算平台资源弹性伸缩框架论文《MagicScaler: Uncertainty-aware, Predictive Autoscaling 》被数据库领域顶会VLDB 2023接收。
MagicScaler论文提出了一种创新的基于预测的云资源主动弹性伸缩框架 MagicScaler,该框架主要包含一个基于多尺度注意力高斯过程的预测模型和一个考虑需求不确定性的弹性伸缩优化决策器。论文在阿里云云原生大数据计算服务MaxCompute 3个集群的真实数据集上进行了实验,综合成本和QoS两个层面,MagicScaler要显著优于其他经典的弹性伸缩算法,实现了“高QoS(Quality of Service),低成本”的双丰收。
背景
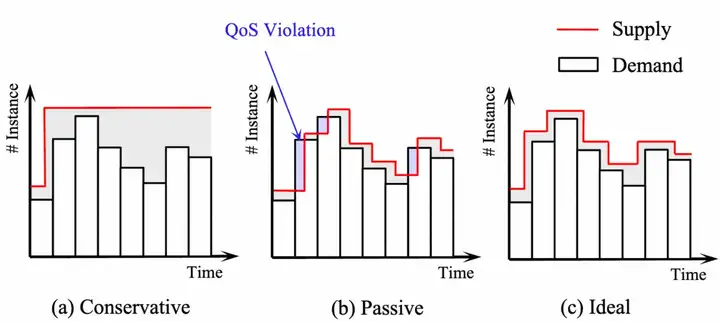
云计算需求的日益发展,基于用户需求合理地进行云资源分配是保障稳定性和控制成本的重要因素。图1所示是三种易于理解的扩缩容策略,保守(Conservative)策略会提供“保守、虚高”的 ECS 供应量,但会造成较高的资源浪费;被动(Passive)策略是用户的需求到达后才执行扩缩容决策,会由于资源“冷启动”问题导致 QoS 违约的风险;为集成这两种策略的优点,预测式自动扩缩容(Predictive Autoscaling)策略可以理解为“提前知道用户需求”后执行扩缩容决策,这将最有可能作为实现图 1 中理想境况的途径。
![]()
图 1:三种易于理解的 AutoScaling 策略:a) 保守策略:高成本,低 QoS 风险;b) 被动策略:较低成本,高 QoS 风险;c) 理想策略:低成本,低 QoS 风险。
现有的自动扩缩框架主要基于控制理论、强化学习、排队理论或基于规则生成扩所容决策,这些方法要么仅使用了较为简单的预测算法,如历史一段时间的平均需求,并未考虑需求可能存在的周期性以及需求的不确定性,使得预测精度不高,且难以应对需求的多变性。部分现有研究仅以启发式方法处理需求的不确定性,难以得到稳健的扩缩容决策。理想的扩缩容框架需要在预测和扩缩容决策阶段都充分考虑需求的不确定性。此外,现有的自动扩缩容框架并未考虑云资源弹性伸缩场景中的一些业务属性和真实约束,例如弹性资源在扩缩容阶段会经历的冷启动、退回成本,云平台场景下QoS和成本之间的权衡约束等,因此现有的这些自动扩缩容框架难以直接应用于阿里云计算平台的弹性伸缩场景中。
挑战
云计算需求的日益发展,基于用户需求合理地进行云资源分配是保障稳定性和控制成本的重要因素。图2展示了阿里云云原生大数据计算服务某个集群在不同数据粒度下的资源请求情况(数据已作脱敏处理),可以看出云上用户需求往往具有高度复杂性、不确定性和粒度敏感的时间依赖性,这给未来需求的准确预测带来了一定困难,也使得主动弹性伸缩更具挑战性。一个好的主动弹性伸缩策略需要在考虑需求不确定性的同时,保持云平台低运行成本和高QoS之间的合理平衡。
![]()
图2 某集群不同数据粒度下的资源请求情况
破局
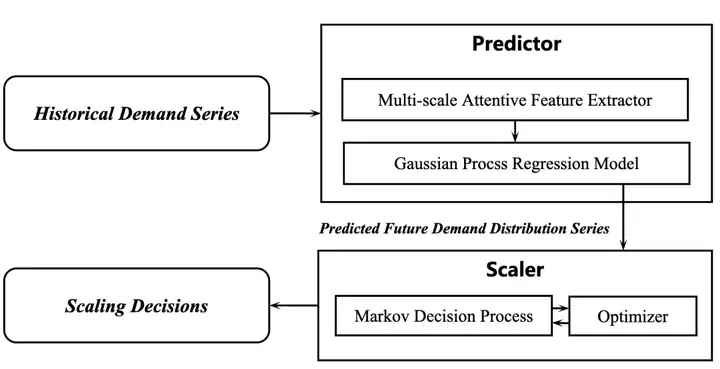
本文提出了一种创新的基于预测的云资源弹性伸缩框架 MagicScaler。该框架主要包含一个基于多尺度注意力高斯过程的预测模型和一个考虑需求不确定性的弹性扩缩容优化决策器,以实现“高QoS(Quality of Service),低成本”双丰收的目标。图3描述了 MagicScaler 的整体框架,包含预测器和调度器两部分。
![]()
图3 MagicScaler整体框架
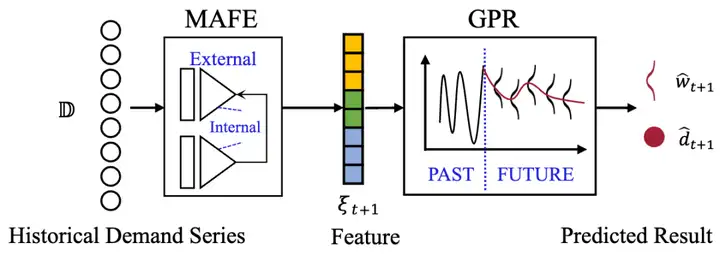
(1)预测器:预测器部分主要构建了基于多尺度注意力机制的高斯回归预测模型。该预测模型设计有机融合了两种高效的预测策略:一是多尺度注意力机制,能够捕捉复杂的多尺度特征;二是随机过程回归,以量化预测结果不确定性。这使得预测模型可以实现精确的需求预测,结合量化的不确定性为后续的弹性伸缩打下基础。图4描述了预测器的整体框架,预测器的输入为 ![t]() 时刻回看的历史需求序列
时刻回看的历史需求序列 ![D_{t}]() 。通过 MAFE(多尺度特征提取)组件提取这个时间序列特征,记为
。通过 MAFE(多尺度特征提取)组件提取这个时间序列特征,记为 ![\xi_{t+1}]() 。将
。将 ![\xi_{t+1}]() 输入至 GPR(高斯过程回归)模型,并以此预测未来
输入至 GPR(高斯过程回归)模型,并以此预测未来 ![F]() 步时间的需求量。
步时间的需求量。
![]()
图4 预测器流程
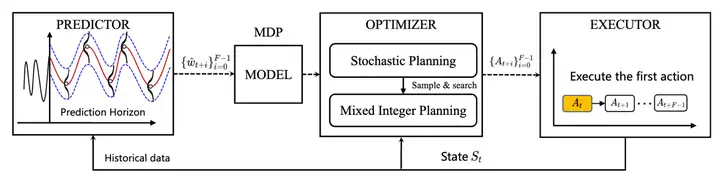
(2)调度器:调度器部分设计了基于预测结果和量化不确定性的弹性扩缩容优化决策器。将复杂业务场景建模为马尔可夫决策(MDP)过程,并利用滚动时域优化的方法近似求解最优策略,实现了资源成本与 QoS 违规风险之间的灵活平衡。图5展示了调度器流程,包括马尔可夫决策过程(MDP)、优化器和弹性伸缩决策执行器。我们的弹性伸缩器以概率需求预测分布作为输入,将弹性伸缩问题建模为马尔可夫决策过程。因为考虑到MDP优化是一个无限域贝尔曼方程优化问题,我们使用滚动时域优化策略,将贝尔曼方程在无限时域内的求解转换为有限时域内的随机规划,从而使得能够找到最佳策略来近似贝尔曼方程的最优解。
![]()
图5 调度器流程
论文在阿里云云原生大数据计算服务MaxCompute 3个集群的真实数据集上进行了实验,综合成本和QoS两个层面,MagicScaler要显著优于其他经典的弹性伸缩算法,更多实验结果请参阅我们的论文原文。
应用
后续将进一步研究如何将MagicScaler技术与MaxCompute现有调度策略结合。
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。

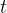 时刻回看的历史需求序列
时刻回看的历史需求序列 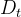 。通过 MAFE(多尺度特征提取)组件提取这个时间序列特征,记为
。通过 MAFE(多尺度特征提取)组件提取这个时间序列特征,记为 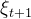 。将
。将 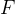 步时间的需求量。
步时间的需求量。