1 资损防控介绍
得物提供大量商品买卖等服务,资金流转量大,任何由于设计缺陷、系统缺陷、系统故障、人为操作、安全漏洞等因素都会引发直接或间接资金损失。资损防控就是在项目全生命周期内,引入多种资金分析和控制手段,预防资损故障或控制资损故障影响范围。
那么在日常工作中,具体如何开展呢?主要可以从以下三个方面来做:
1.1机制流程建设
在业务项目开始时,我们应该评定项目资金风险等级,比如高风险需要重点关注&投入,中风险需要投入多少资源,低风险又如何保障。
在项目资金风险评定后,产品架构设计时需要包括技术风险设计,比如幂等、分布式数据一致性、异地多活等。
然后对于高资金风险项目,我们需要出专门的资金风险系分,在得物重点关注资金流、信息流以及物流的流转,比如业务的高保链路是怎么样的,有哪些资损风险点等。
接下来就是对输出的资损风险点进行布防,布防的形式主要是核对和监控,核对为主,监控作为兜底,因为前面输出的资损风险点可能会有遗漏,监控是业务异常的感知手段。日常我们也可以通过混沌工程进行风险挖掘&核对规则验证。
最后我们需对资损风险告警进行应急,拉起应急小组排查确认风险并修复。
1.2人员阵型建设
资损防控并不是靠某一个角色来承担,而是需要架构、研发、质量和SRE一起来防控并嵌入日常工作流程中,从组织架构视角,我们需要建立至少三道防线,即研发防线,质量防线和SRE防线,相互兜底,合并共举达到资损防控的目的。当然各角色在项目各个阶段各有侧重,比如SRE负责业务线上稳定性,那么线上的资损防控投入相对大一些。
1.3多体系防控
从发现资损风险时效视角来说,可以分为实时核对(T+0)、近实时核对(T+M)、离线核对(T+H, T+1),每种核对方式都有其适配的业务场景,并不存在替代之说,比如不落库的配置变更适用实时核对,业务定时任务适用离线核对等等。实际业务场景布防时需分析业务特点,然后再使用合适的核对体系工具。在组织分工方面,研发侧重离线核对,测试侧重近实时核对,SRE侧重实时核对,当然实际工作中并不必这么界线分明,自己看到的风险点,可以选用合适的工具体系。
从核对是否影响业务运行视角看,可以分为旁路核对和主路核对,旁路核对的结果对业务运行不构成影响,仅仅是风险揭示,而主路核对是有能力影响业务运行的,比如资损熔断用的就是主路核对技术,在核对告警报出后中断业务运行。目前公司已有的A、B平台都属于旁路核对体系。
在布防核对规则后,我们怎么检验布防的有效性,同时因为业务迭代发展,早前布防的核对规则需要调整核对逻辑来适配新的业务逻辑,也就是说我们如何保鲜核对规则?这就需要混沌工程资损演练来支撑了。资损演练又分为有损演练和无损演练,比如在线上搞有损演练时经常把金额数据加/减0.01,检验布防的核对规则是否发现,这样即使发生了实际资损也在演练预算可以覆盖的范围内,但在线上搞有损演练需谨慎评估影响范围。资损防控无损演练关键在于生产库的克隆,这样在演练时做数据篡改并不影响线上业务运行。
2 资损防控技术体系
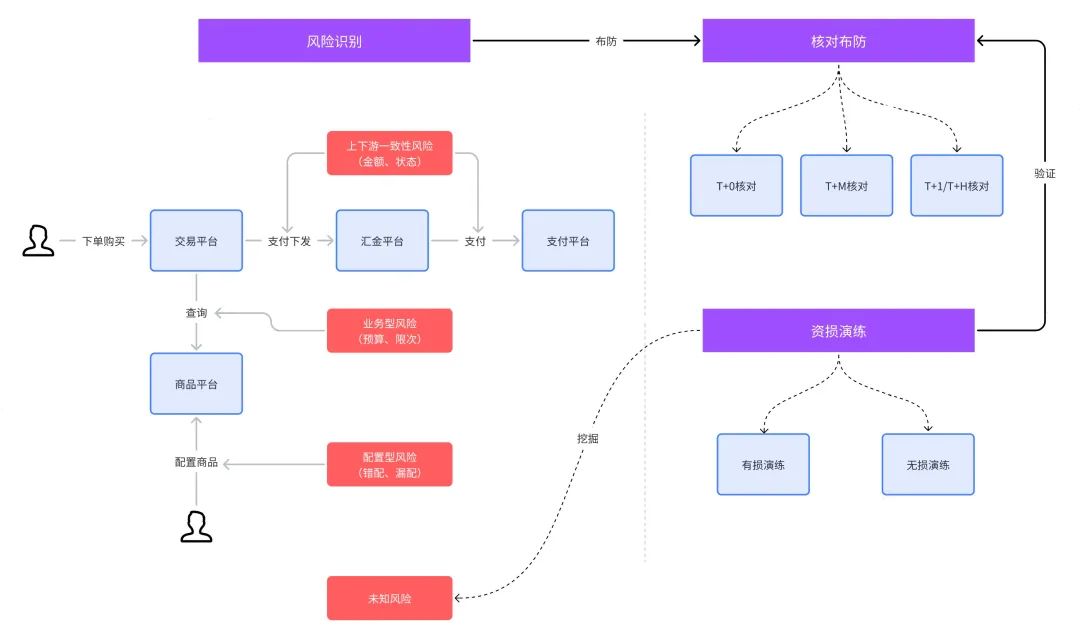
我们在做资损防控时,最重要的一步是风险识别,它是资损核对布防的源头,可以这么说,如果没有风险识别就没有接下来核对布防。风险识别可以通过人工分析和智能系统推导两种方式得到,从建设发展阶段来说,人工分析通常是最开始采用的方式,在这个基础上,再通过算法推导+专家经验发展出智能系统推导。下面依人工分析视角来展开,这里举例一个简化版得物系统的资损防控如何做。如下图所示,左边为商品交易业务链路,其中包括用户下单交易和运营配置商品:
![]()
因为交易平台落有订单交易的金额和状态,而汇金平台对接各支付渠道,是支付的实际执行者,这里就存在上下游订单金额、状态的一致性风险。
如用户购买的商品在参加营销活动,交易平台会查询商品运营平台具体活动逻辑,比如营销活动的预算、优惠券使用的限次逻辑,这里可能存在活动预算、优惠券使用的业务型风险。
运营人员配置某次营销活动,在圈品、价格等关键参数上出现错配、漏配等配置型风险。
上面所说的风险通常需要在分析PRD、技术实现文档或代码CR后才能识别出来,接下来看看我们如何进行布防。
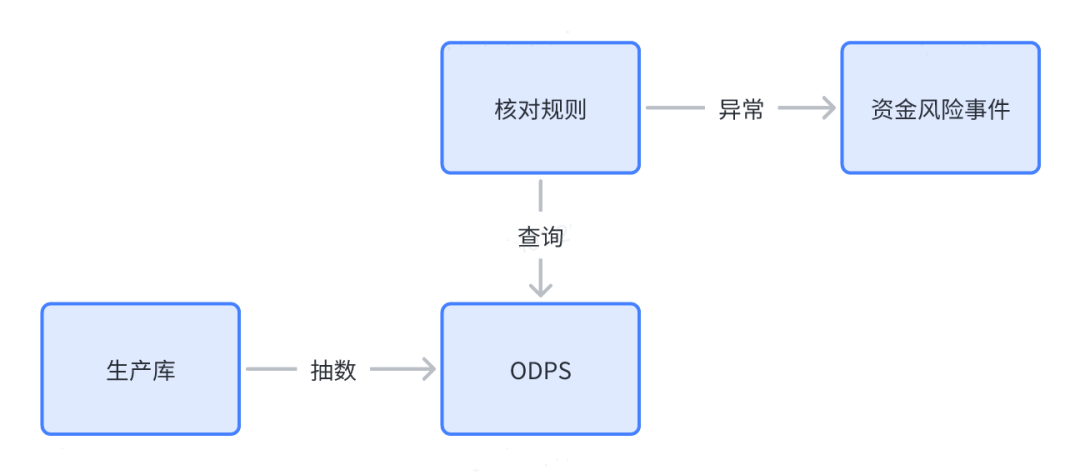
2.1 T+1/T+H核对
在整个资金防控体系的演进过程中,离线核对应该说是业界最先发展出来的核对手段,最初与很多银行一样,是靠人力做当前的金额跟全天总账的对账,之后通过自动的方式,将全量数据库表导出后做计算来进行核对。目前在得物主要是通过ODPS来实现T+1、T+H离线核对,它的优势是不影响业务生产库,并且因为是定时调度运行,所以对于业务定时任务等需较长时间数据回溯的场景比较适配。
![]()
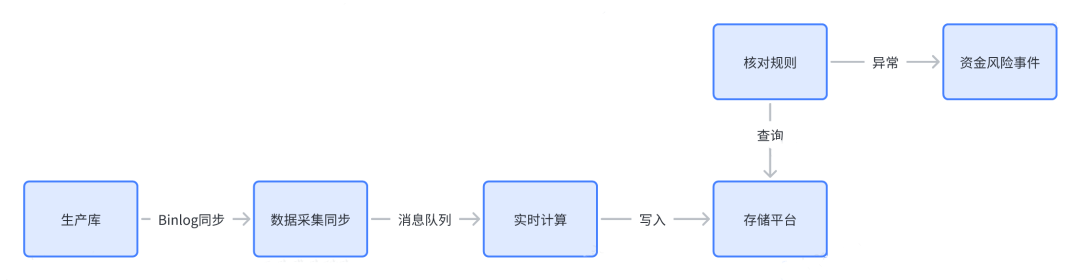
2.2 T+M核对
通过数据库Binlog可以实现分钟级的资损核对,这种核对方式对于业务上下游一致性风险有非常好的发现能力,日常配合混沌工程的无损演练能力,对于未覆盖到资损风险也可以很好的揭示出来,所以T+M核对适用于涉数据库字段的一致性风险、盖帽等业务场景。
![]()
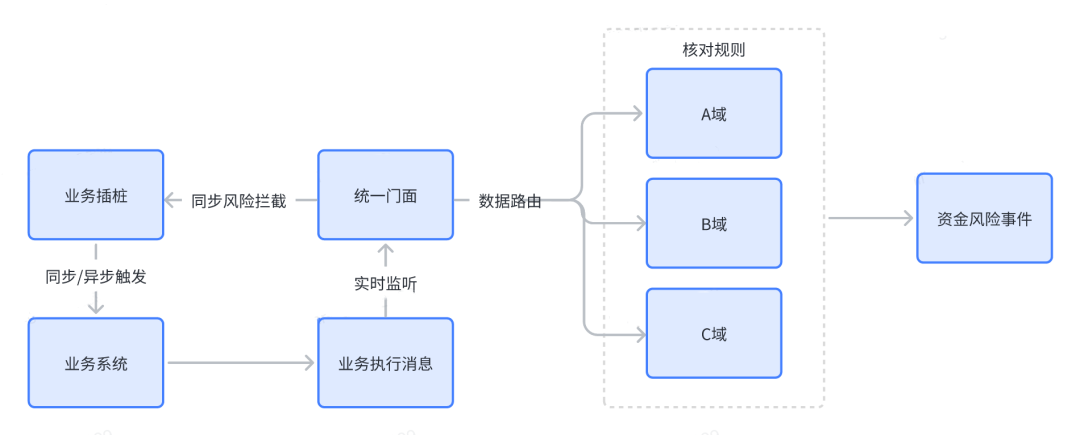
2.3 T+0核对
随着业务的发展,对于资损核对也提出更高要求,我们需要发展出实时核对能力。比如可以通过业务插桩的方式来实现同步/异步触发,同时实时监听业务执行消息,然后数据路由至具体业务域执行核对逻辑,这种核对方式属资损防控领域的重武器,适用于业务型风险、配置型风险,同时满足复杂业务核对场景。目前SRE已经在建设T+0实时核对系统。
![]()
2.4 资损演练
资损演练可以验证布防的核对规则有效性,又可以用来挖掘未覆盖到资损风险,所以资损演练是资损防控体系很重要的一环。资金无损演练有以下三个关键点:
资损防控落地的规则都是针对业务数据来执行的
资损防控无损演练的数据来自生产环境
无损演练数据与生产环境数据实质是隔离的
下图为初步的资金无损演练方案:
![]()
3 得物业务实践
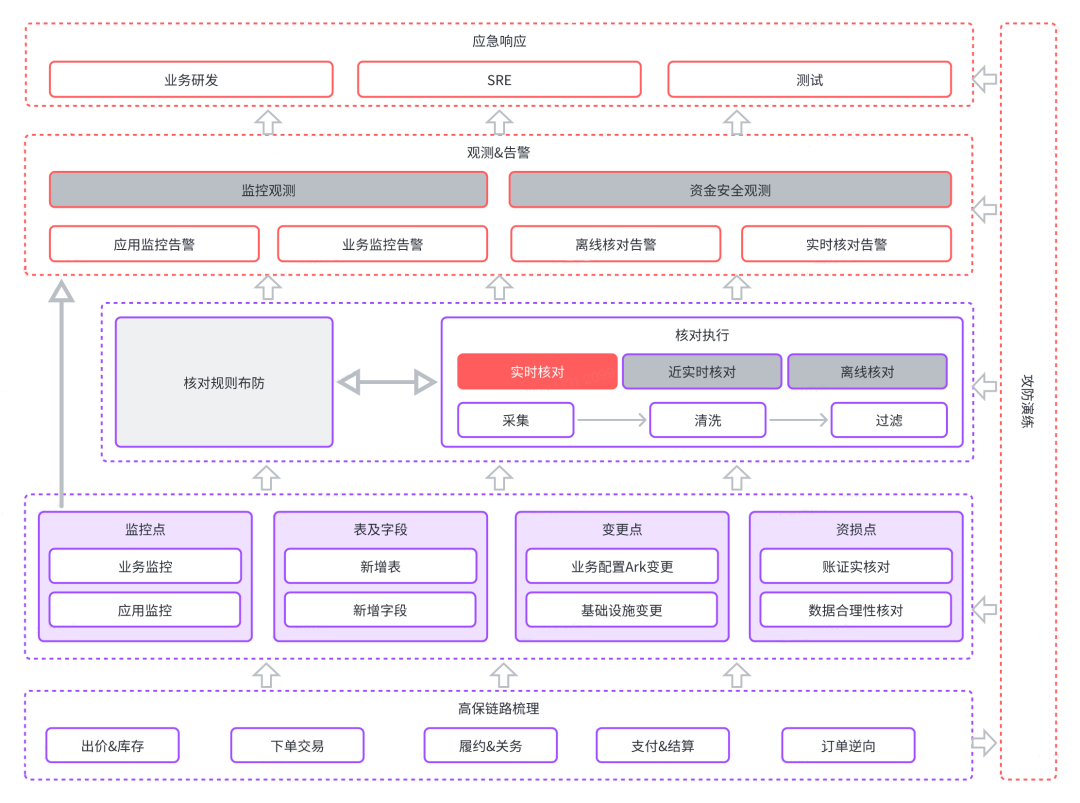
作为支持得物业务的SRE主导了得物履约资金安全保障工作,由于得物履约的业务链路长,风险敞口大,我们认真考虑了业务稳定性及其资损风险并实践了前述的相关资损防控理念。
![]()
3.1 高保链路梳理
出价、下单、支付、发货、结算、营销、逆向7个业务域定义出高保业务链路,输出资损点、变更点、新增表及字段以及相关监控点。
3.2 工具选型
依托现有工具平台进行布防,成本最优解。
![]()
3.3 规则布防
资损防控通过核对规则落地,同时业务监控配置告警规则,通过混沌工程演练验证规则有效性。
3.4 观测告警
a. 应急响应
b. 自动巡检
i. 每天自动巡检重要指标推送到对应的工作群
3.5 演练
a. 对相关规则进行保鲜
b. 未暴露风险挖掘
3.6 实时核对体系建设
a. 业务插桩先旁路核对,后可阻断核对。
4 总结&展望
在得物落地资损防控期间,作为SRE一直在宣导的理念:资损防控需要研发、测试、SRE三方相互协作,三道防线相互兜底,合并共举达到资损防控的目标。未来,资损防控我们重点关注以下3个方面:
风险分析--目前我们主要还是基于专家经验,后续我们将通过数据染色,血缘分析,做到自动化的风险输出。
多体系防控--完善资损防控体系建设,抽象通用防控能力与可扩展的精细化防控能力,做到核对工具体系与业务场景相适配。
资损演练--在大规模的业务体系之下,纯靠人去做攻击,其实是不太现实的,必须得靠智能化、数据化的方式去驱动。同一个故障,我们让它在成百上千个系统上面去重放,这样我们就可以非常高效地去实现大规模风险的挖掘,验证风险防控规则的有效性以及已布防规则的保鲜。
*文 / Yuerong
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!