Taier 作为袋鼠云的开源项目之一,是一个分布式可视化的 DAG 任务调度系统。旨在降低 ETL 开发成本,提高大数据平台稳定性,让大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
本文将从 Taier 的流程简述、结构分析以及可扩展点三个方面对 Taier 的整体流程进行分析探讨。
Taier 流程简述
Taier 主从划分
Taier 是一个单独的应用,进程无主从划分,多实例运行时通过 ZK 实现主从划分。基于 LeaderLatch 进行实现,启动时抢到锁的节点即为主(Master),没有抢到锁的即为从( Worker),会出现一主多从的情况。
如果其他的 Worker 在 ZK 中监听到 Master 已经挂掉,那么 Worker 会再次进行锁的争夺,抢到锁的成为主。
在 Taier 中,作为主的主要职责包括周期实例生成、实例预分发、Worker 节点任务容灾、实例提交等,作为从则主要负责实例提交即可。
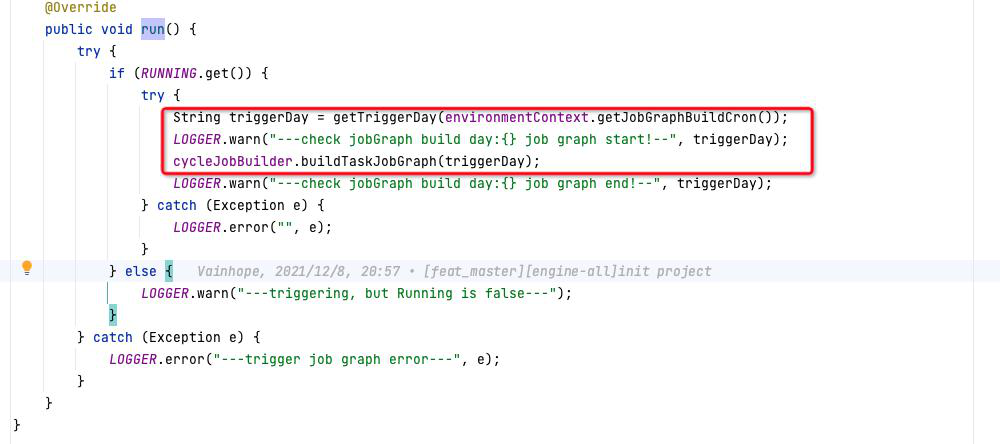
Taier 周期实例(T+1)
周期实例是 Taier 的专属名词,指的是任务按照配置的调度时间运行一次即为一个实例,现在周期实例的机制为 T+1 的方式。
今日会预生成明天所有任务对应的周期实例,即今日的周期实例由昨天生成。Taier 默认22:00生成第二天周期实例,如果在22:00之后再将任务提交到调度系统,这个任务则不会进行周期实例生成的动作。
配置项为 job.graph.build.cron=22:00:00,时间可以自己调整。
![file]()
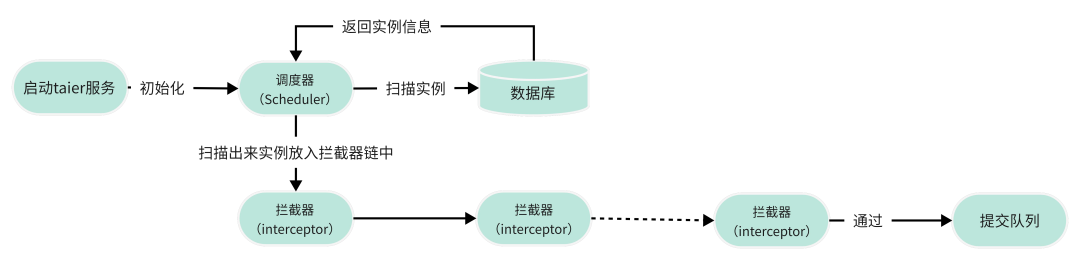
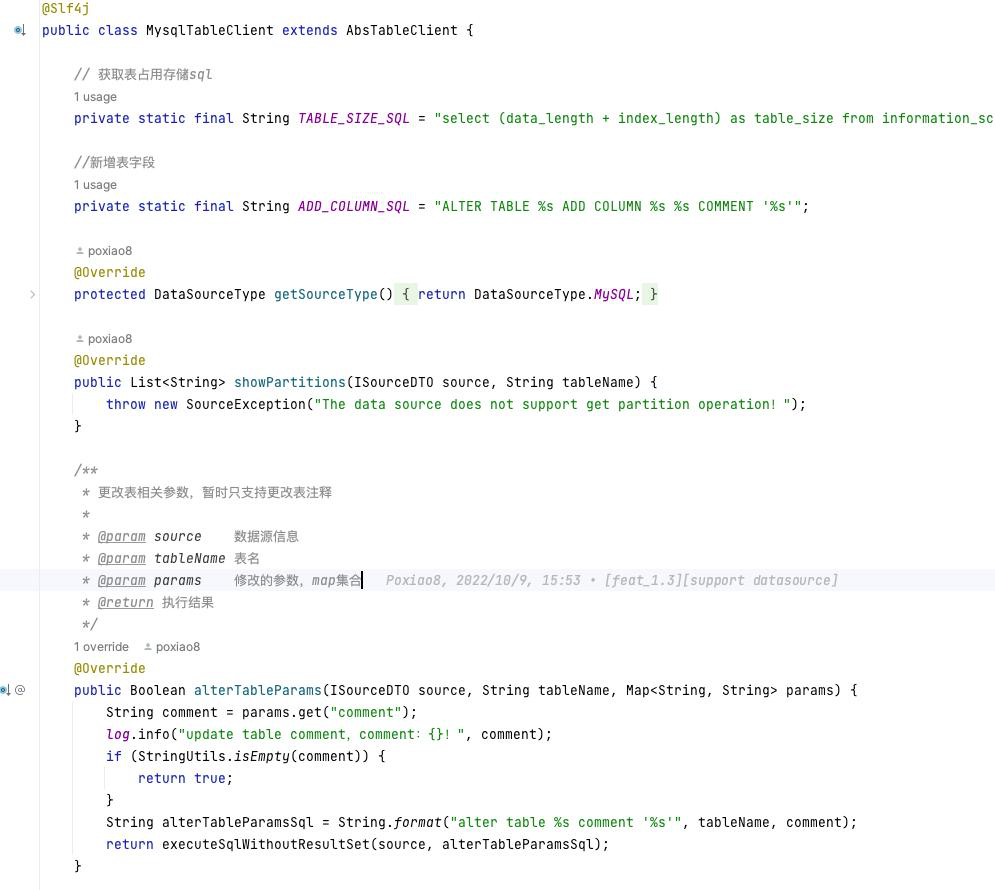
Taier 任务提交
Taier 任务提交的具体流程图如下:
![file]()
任务流程提交前置判断主要分为两个部分,一为任务上下游的依赖校验,会判断周期实例的上游是否已经运行完成,如果上游运行失败,那么这个任务就是不准备提交的;二为资源校验,因为任务都是运行在集群上,非常占资源,所以会进行提交前的校验,判断当前集群的资源是否充足,如果资源不足,会进行延迟提交的动作。
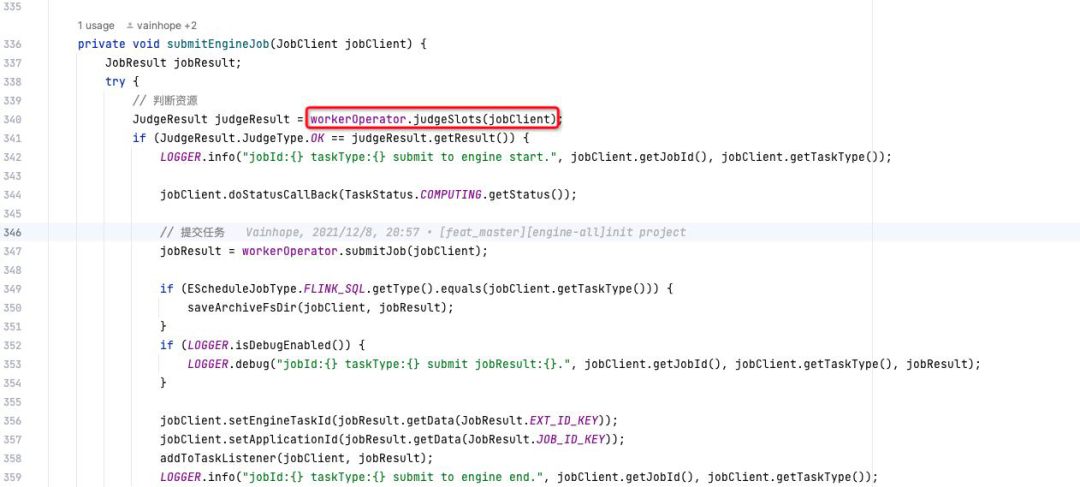
Taier 任务提交的具体代码如下:
![file]()
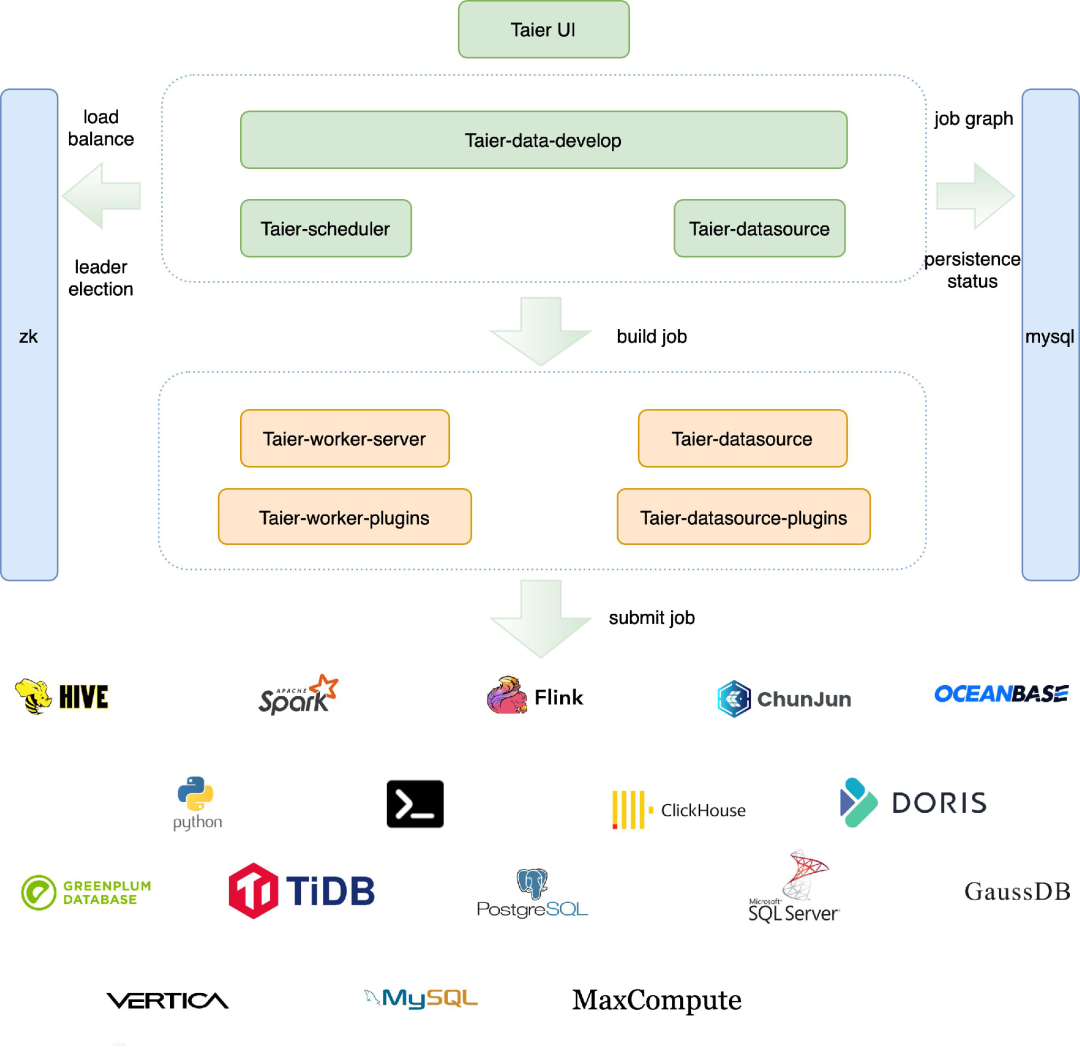
Taier 结构分析
Taier 的结构主要分为 UI、应用层和插件三个部分,在插件中,Taier worker-plugin 和 Taier datasource-plugin 又是其中最为重要的两个插件。
![file]()
Taier worker-plugin
Taier worker-plugin 的主要用途包括:
· 任务资源判断
· 任务提交
· 任务状态获取
· 任务日志获取
· Kill 任务
具体代码如下:
![file]()
![file]()
相关的类包括:
· com.dtstack.taier.common.client.ClientFactory
· com.dtstack.taier.common.client.ClientProxy
· com.dtstack.taier.common.client.ClientCache
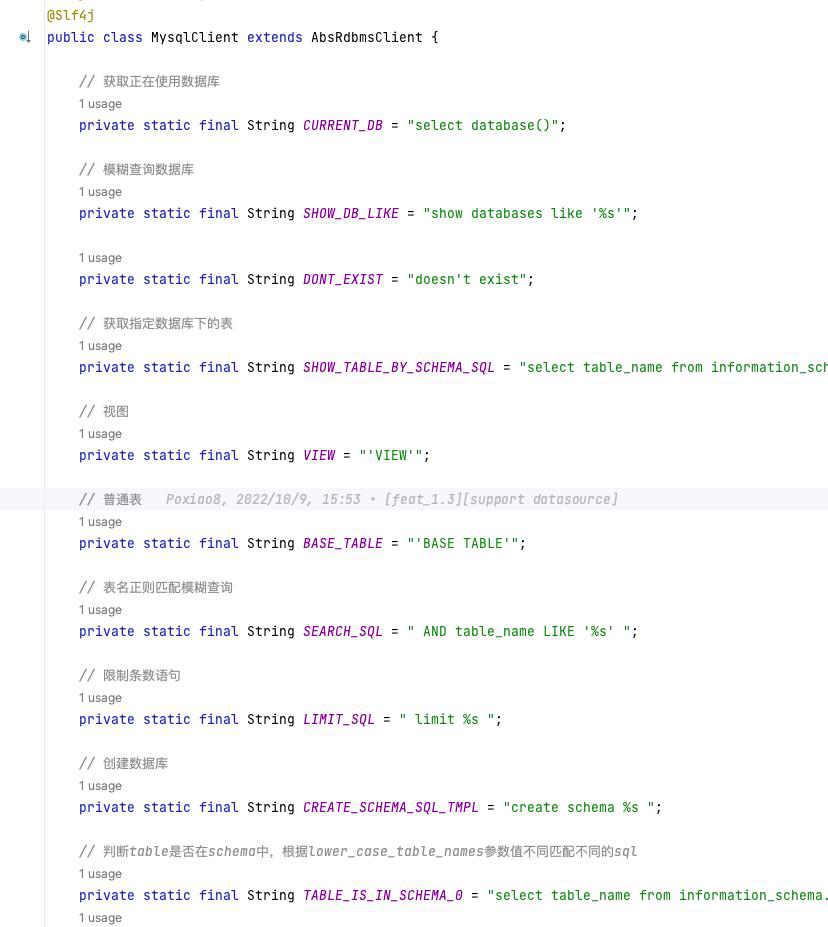
Taier datasource-plugin
Taier datasource-plugin 的主要用途包括:
· 连通性检查
· 执行 SQL
· 获取 Schema 信息
· 获取 Table 列表
· 获取表元数据
· 下载数据
· 下载日志
具体代码如下:
![file]()
![file]()
![file]()
![file]()
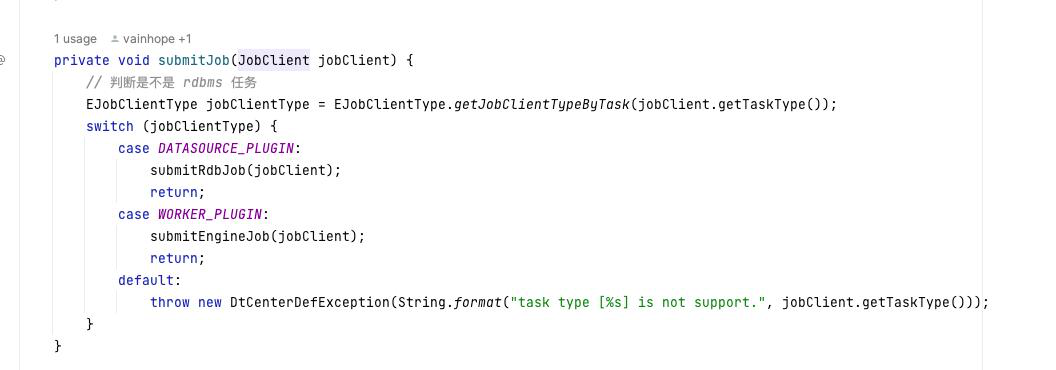
Taier 任务提交插件
参考代码:
com.dtstack.taier.scheduler.jobdealer.JobSubmitDealer#submitJob
![file]()
Taier 可扩展点
Taier 目前就核心功能进行了开源,其他功能开发者可以自行进行扩展,包括:
· 任务立即生成实例
· ChunJun 向导模式扩展
· DataX 支持向导模式配置
· 数据源插件版本扩展
· 计算引擎新增
· Hadoop 多集群版本支持
· 实例分发策略增加
视频课程&PPT获取
视频课程:
https://www.bilibili.com/video/BV1wP411z7rf/?spm_id_from=333.999.0.0
课件获取:
https://www.dtstack.com/resources/1047
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack