@[toc] 以下内容基于 Spring6.0.4。
关于 Spring 循环依赖,松哥已经连着发了三篇文章了,本篇文章松哥从源码的角度来和小伙伴们捋一捋 Spring 循环依赖到底是如何解决了。如果没看过前面的文章建议先看一下,大家在面试中如果遇到循环依赖相关的问题,其实看前面三篇文章就可以答出来了,本文主要是从源码角度来验证一下我们前面文章所讲的内容是无误的。
前三篇传送门:
- 如何通过三级缓存解决 Spring 循环依赖
- Spring 能解决所有循环依赖吗?
- [@Lazy 注解为啥就能破解死循环?](https://mp.weixin.qq.com/s/GjI4xPGXscCGQtcalwnJKQ)
小伙伴们一定要先熟悉前面文章的内容,否则今天的源码可能会看起来有些吃力。
接下来我通过一个简单的循环依赖的案例,来和大家梳理一下完整的 Bean 循环依赖处理流程。
1. 案例设计
假设我有如下 Bean:
@Service
public class A {
@Autowired
B b;
}
@Service
public class B {
@Autowired
A a;
}
就这样一个简单的循环依赖,默认情况下,A 会被先加载,然后在 A 中做属性填充的时候,去创建了 B,创建 B 的时候又需要 A,就会从缓存中拿到 A,大致流程如此,接下来我们结合源码来验证一下这个流程。
2. 源码分析
首先我们来看获取 Bean 的时候,如何利用这三级缓存。
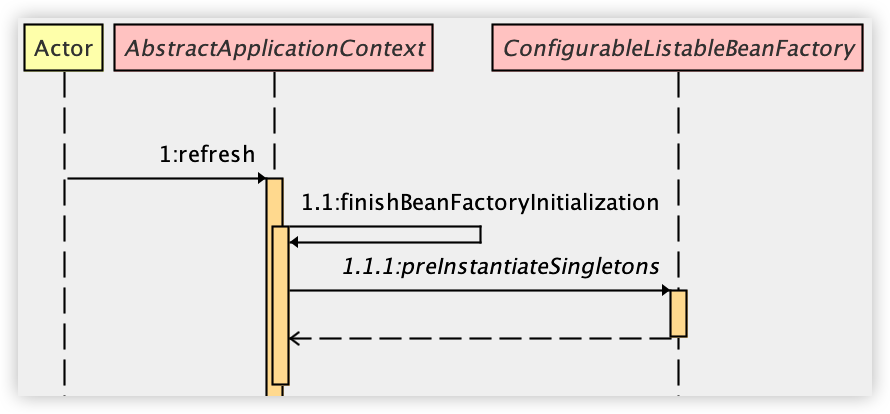
小伙伴们知道,获取 Bean 涉及到的就是 getBean 方法,像我们上面这个案例,由于都是单例的形式,所以 Bean 的初始化其实在容器创建的时候就完成了。
![]()
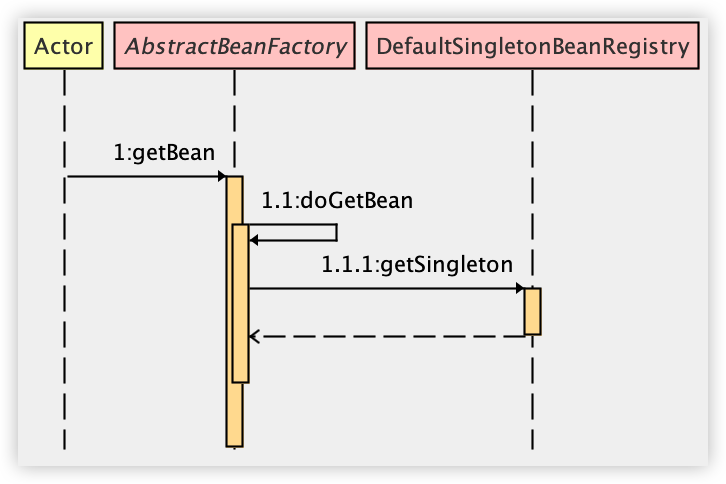
在 preInstantiateSingletons 方法中,又调用到 AbstractBeanFactory#getBean 方法,进而调用到 AbstractBeanFactory#doGetBean 方法。
![]()
Bean 的初始化就是从这里开始的,我们就从这里来开始看起吧。
2.1 doGetBean
AbstractBeanFactory#doGetBean(方法较长,节选部分关键内容):
protected <t> T doGetBean(
String name, @Nullable Class<t> requiredType, @Nullable Object[] args, boolean typeCheckOnly)
throws BeansException {
String beanName = transformedBeanName(name);
Object beanInstance;
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// Check if bean definition exists in this factory.
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory abf) {
return abf.doGetBean(nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
StartupStep beanCreation = this.applicationStartup.start("spring.beans.instantiate")
.tag("beanName", name);
try {
if (requiredType != null) {
beanCreation.tag("beanType", requiredType::toString);
}
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
try {
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// Create bean instance.
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
}
}
return adaptBeanInstance(name, beanInstance, requiredType);
}
这个方法比较长,我来和大家说几个关键的点:
- 首先这个方法一开始就调用了 getSingleton 方法,这个是尝试从三级缓存中获取到想要的 Bean,但是,当我们第一次初始化 A 的时候,很显然这一步是无法获取到 A 的实例的,所以这一步会返回 null。
- 如果第一步拿到了 Bean,那么接下来就进入到 if 分支中,直接获取到想要的 beanInstance 实例;否则进入到第三步。
- 如果第一步没有从三级缓存中拿到 Bean,那么接下来就要检查是否是循环依赖了,首先调用 isPrototypeCurrentlyInCreation 方法判断当前 Bean 是否已经在创建了,如果已经在创建了,那么显然要抛异常出去了(BeanCurrentlyInCreationException)。接下来就去 parent 容器中各种查找,看能否找到需要的 Bean,Spring 中的父子容器问题松哥在之前的文章中也已经讲过了,小伙伴们可以参考:Spring 中的父子容器是咋回事?。
- 如果从父容器中也没找到 Bean,那么接下来就会调用 markBeanAsCreated 方法来标记当前 Bean 已经创建或者正准备创建。
- 接下来会去标记一下创建步骤,同时检查一下 Bean 的 dependsOn 属性是否存在循环关系,这些跟我们本文关系都不大,我就不去展开了。
- 关键点来了,接下来判断如果我们当前 Bean 是单例的,那么就调用 getSingleton 方法去获取一个实例,该方法的第二个参数一个 Lambda 表达式,表达式的核心内容就是调用 createBean 方法去创建一个 Bean 实例,该方法将不负众望,拿到最终想要的 Bean。
以上就是 doGetBean 方法中几个比较重要的点。
其中有两个方法我们需要展开讲一下,第一个方法就是去三级缓存中查询 Bean 的 getSingleton 方法(步骤一),第二个方法则是去获取到 Bean 实例的 getSingleton 方法(步骤六),这是两个重载方法。
接下来我们就来分析一下这两个方法。
2.2 查询三级缓存
DefaultSingletonBeanRegistry#getSingleton:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<!--?--> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
- 首先去 singletonObjects 中查找,这就是所谓的一级缓存,如果这里能直接找到想要的对象,那么直接返回即可。
- 如果一级缓存中不存在想要的 Bean,那么接下来就该去二级缓存 earlySingletonObjects 中查找了,二级缓存要是有我们想要的 Bean,那么也是直接返回即可。
- 二级缓存中如果也不存在,那么就是加锁然后去三级缓存中查找了,三级缓存是 singletonFactories,我们从 singletonFactories 中获取到的是一个 ObjectFactory 对象,这是一个 Lambda 表达式,调用这里的 getObject 方法最终有可能会促成提前 AOP,至于这个 Lambda 表达式的内容,松哥在前面的文章中已经和小伙伴们介绍过了,这里先不啰嗦(如何通过三级缓存解决 Spring 循环依赖)。
- 如果走到三级缓存这一步了,从三级缓存中拿到了想要的数据,那么就把数据存入到二级缓存 earlySingletonObjects 中,以备下次使用。同时,移除三级缓存中对应的数据。
当我们第一次创建 A 对象的时候,很显然三级缓存中都不可能有数据,所以这个方法最终返回 null。
2.3 获取 Bean 实例
接下来看 2.1 小节步骤六的获取 Bean 的方法。
DefaultSingletonBeanRegistry#getSingleton(方法较长,节选部分关键内容):
public Object getSingleton(String beanName, ObjectFactory<!--?--> singletonFactory) {
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
- 这个方法首先也是尝试从一级缓存中获取到想要的 Bean,如果 Bean 为 null,就开始施法了。
- 首先会去判断一下,如果这个工厂的单例正在销毁,那么这个 Bean 的创建就不被允许。
- 接下来会有一堆准备工作,关键点在
singletonFactory.getObject(); 地方,这个就是方法第二个参数传进来的回调函数,将来在回调函数中,会调用到 createBean 方法,真正开始 A 这个 Bean 的创建。将 A 对象创建成功之后,会把 newSingleton 设置为 true,第 4 步会用到。
- 现在调用 addSingleton 方法,把创建成功的 Bean 添加到缓存中。
我们来看下 addSingleton 方法:
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
小伙伴们看一下,一级缓存中存入 Bean,二级缓存和三级缓存移除该 Bean,同时在 registeredSingletons 集合中记录一下当前 Bean 已经创建。
所以现在的重点其实又回到了 createBean 方法了。
2.4 createBean
createBean 方法其实就到了 Bean 的创建流程了。bean 的创建流程在前面几篇 Spring 源码相关的文章中也都有所涉猎,所以今天我就光说一些跟本文主题相关的几个点。
createBean 方法最终会调用到 AbstractAutowireCapableBeanFactory#doCreateBean 方法,这个方法也是比较长的,而我是关心如下几个地方:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
return exposedObject;
}
这里我比较在意的有两个地方,一个是调用 addSingletonFactory 方法向三级缓存中添加回调函数,回调函数是 getEarlyBeanReference,如果有需要,将来会通过这个回调提前进行 AOP,即使没有 AOP,就是普通的循环依赖,三级缓存也是会被调用的,这个大家继续往后看就知道了,另外还有一个比较重要的地方,在本方法一开始的时候,就已经创建出来 A 对象了,这个时候的 A 对象是一个原始 Bean,即单纯的只是通过反射把对象创建出来了,Bean 还没有经历过完整的生命周期,这里 getEarlyBeanReference 方法的第三个参数就是该 Bean,这个也非常重要,牢记,后面会用到。
第二个地方就是 populateBean 方法,当执行到这个方法的时候,A 对象已经创建出来了,这个方法是给 A 对象填充属性用的,因为接下来要注入 B 对象,就在这个方法中完成的。
由于我们第 1 小节是通过 @Autowired 来注入 Bean 的,所以现在在 populateBean 方法也主要是处理 @Autowired 注入的情况,那么这个松哥之前写过文章,小伙伴们参考@Autowired 到底是怎么把变量注入进来的?,具体的注入细节我这里就不重复了,单说在注入的过程中,会经过一个 DefaultListableBeanFactory#doResolveDependency 方法,这个方法就是用来解析 B 对象的(至于如何到达 doResolveDependency 方法的,小伙伴们参考 @Autowired 到底是怎么把变量注入进来的?一文)。
doResolveDependency 方法也是比较长,我这里贴出来和本文相关的几个关键地方:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<string> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
//...
Map<string, object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<string, object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
//...
}
- 在这个方法中,首先调用 findAutowireCandidates 方法,以类型为依据,找到所有满足条件的 Class 并组成一个 Map 返回。例如第一小节的案例,这里就会找到所有 B 类型的 Class,通过一个 Map 返回。
- 如果第一步返回的 Map 存在多条记录,那么就必须从中挑选一个出来,这就是
matchingBeans.size() > 1 的情况。
- 如果第一步返回的 Map 只有一条记录,那么就从 Map 中提取出来 key 和 value,此时的 value 是一个 Class,所以接下来还要调用
descriptor.resolveCandidate 去完成 Class 到对象的转变。
而 descriptor.resolveCandidate 方法又开启了新一轮的 Bean 初始化,只不过这次初始化的 B 对象,如下:
public Object resolveCandidate(String beanName, Class<!--?--> requiredType, BeanFactory beanFactory)
throws BeansException {
return beanFactory.getBean(beanName);
}
2.5 后续流程
后续流程其实就是上面的步骤,我就直接来跟大家说一说,就不贴代码了。
现在系统调用 beanFactory.getBean 方法去查找 B 对象,结果又是走一遍本文第二小节的所有流程,当 B 创建出来之后,也要去做属性填充,此时需要在 B 中注入 A,那么又来到本文的 2.4 小节,最终又是调用到 resolveCandidate 方法去获取 A 对象。
此时,在获取 A 对象的过程中,又会调用到 doGetBean 这个方法,在这个方法中调用 getSingleton 的时候(2.1 小节的第一步),这个时候的执行逻辑就跟前面不一样了,我们再来看下这个方法的源码:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<!--?--> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
现在还是尝试从三级缓存中获取 A,此时一二级缓存中还是没有 A,但是三级缓存中有一个回调函数,当执行 singletonFactory.getObject() 方法的时候,就会触发该回调函数,这个回调函数就是我们前面 2.4 小节提到的 getEarlyBeanReference 方法,我们现在来看下这个方法:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
这个方法有一个参数 Bean,这个参数 Bean 会经过一些后置处理器处理之后返回,后置处理器主要是看一下这个 Bean 是否需要 AOP,如果需要就进行 AOP 处理,如果不需要,直接就把这个参数 Bean 返回就行了。至于这个参数是哪来的,我在 2.4 小节中已经加黑标记出来了,这个参数 Bean 其实就是原始的 A 对象!
好了,现在 B 对象就从缓存池中拿到了原始的 A 对象,B 对象属性注入完毕,对象创建成功,进而导致 A 对象也创建成功。
大功告成。
3. 小结
老实说,如果小伙伴们认认真真看过松哥最近发的 Spring 源码文章,今天的内容很好懂~至此,Spring 循环依赖,从思路到源码,都和大家分析完毕了~感兴趣的小伙伴可以 DEBUG 走一遍哦~</string,></string,></string></t></t>