摘要
随着大数据时代的到来,数据分析已经成为企业和组织的核心竞争力。然而,传统的数据分析方法往往无法满足日益增长的数据分析需求的数量和复杂性。在这种背景下,ChatGPT-4作为一种先进的自然语言处理技术,为数据分析带来了革命性的提升,助力企业和组织更高效地挖掘数据价值。本文将探讨ChatGPT-4在数据分析中的应用,以及如何通过该技术提高数据分析的效率和洞察力。
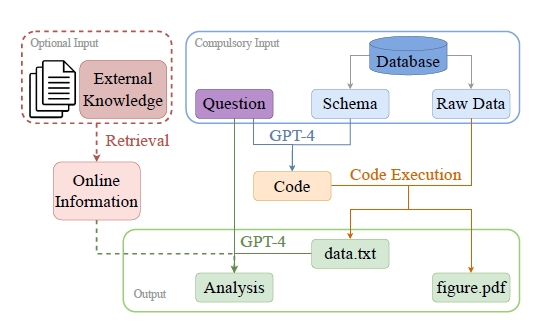
![]()
注:此图片选自阿里巴巴集团达摩院和新加坡南洋理工大学合作论文《Is GPT-4 a Good Data Analyst》
1. 引言
随着互联网和移动设备的普及,数据的产生和传播速度不断加快,企业和组织需要更高效的方法来处理和分析这些数据。传统的数据分析方法往往依赖于人工处理和分析,在需求量大的时候容易出现效率低的问题。因此,如何利用先进的技术提高数据分析的效率和准确性成为了一个迫切的问题。ChatGPT-4作为一种基于深度学习的自然语言处理技术,为解决这一问题提供了新的思路。
2. ChatGPT-4技术概述
ChatGPT-4是一种基于深度学习的自然语言处理(NLP)技术,能够理解和生成人类语言。通过大量的训练数据和复杂的神经网络模型,ChatGPT-4可以实现对文本数据的高效处理,从而提高数据分析的效率和准确性。
3. ChatGPT-4在数据分析中的应用
本文将从以下几个场景来探讨ChatGPT-4在数据分析中的应用:
3.1 使用ChatGPT-4生成实验所需用到的HIVE库表
Prompt word:
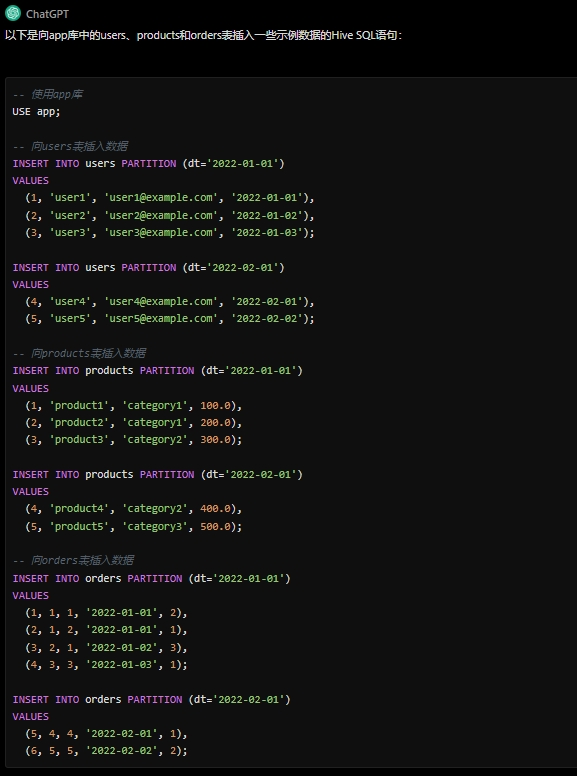
现在请创建一个名为"app"的Hive库,并且包含有如下表:
- users:存储用户信息 user_id (INT):用户ID username (STRING):用户名 email (STRING):用户邮箱 registration_date (DATE):注册日期
- products:存储产品信息 product_id (INT):产品ID product_name (STRING):产品名称 category (STRING):产品类别 price (FLOAT):产品价格
- orders:存储订单信息 order_id (INT):订单ID user_id (INT):用户ID product_id (INT):产品ID order_date (DATE):订单日期 quantity (INT):购买数量
每个表格式都为 ORC格式,每个都有一个 dt 也即是每天加工日期命名的分区字段,建表的时候表和字段都要有中文注释。
![]()
3.2 使用ChatGPT-4往HIVE库表中插入一些样例数据:
Prompt word:
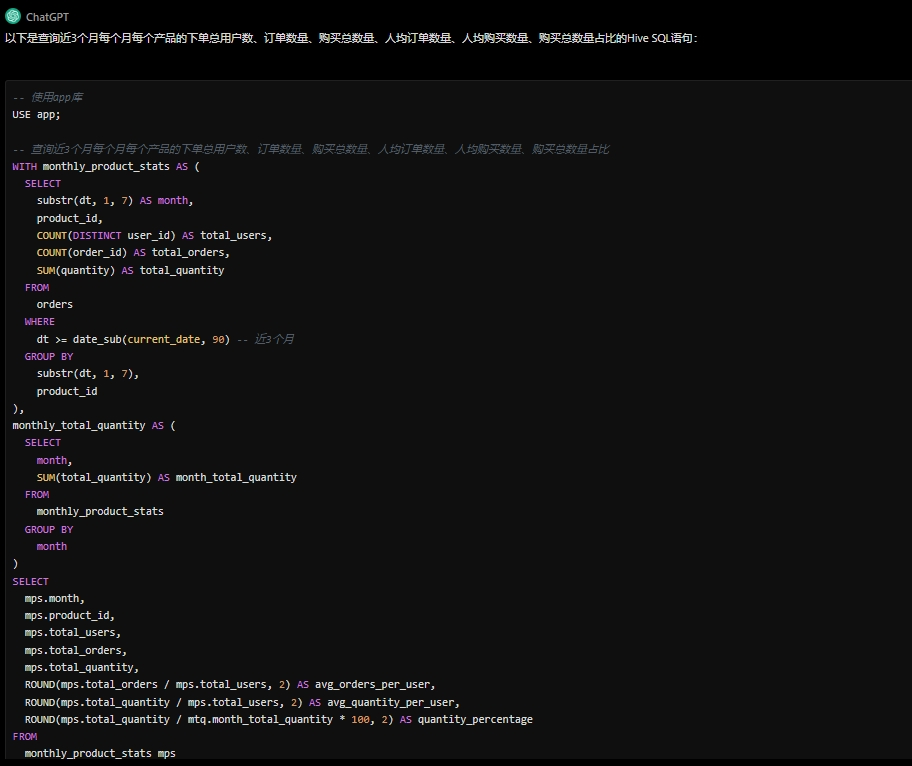
现在请往上述app库中的表各插入一些样例数据。
![]()
3.3 HIVE单表数据分析场景:
Prompt word:
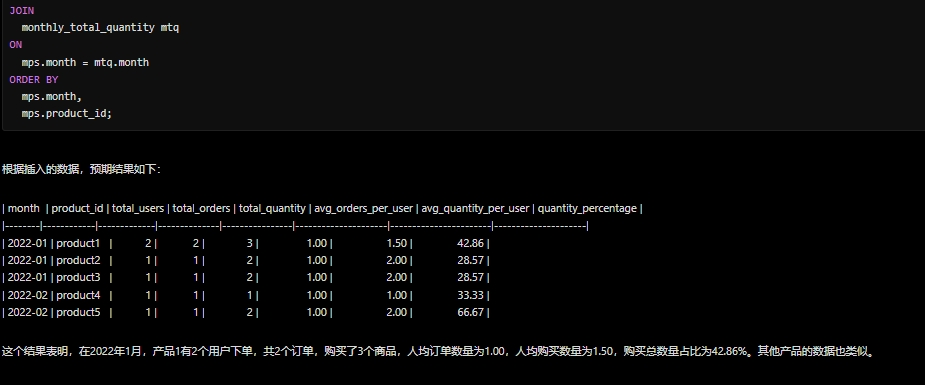
现在需要在上述插入数据后的app库中,查询近3个月每个月每个产品的下单总用户数、订单数量、购买总数量、人均订单数量、人均购买数量 、购买总数量占比(精确到小数点后两位),请给出HIVESQL,并给出执行结果。
![]()
![]()
Prompt word:
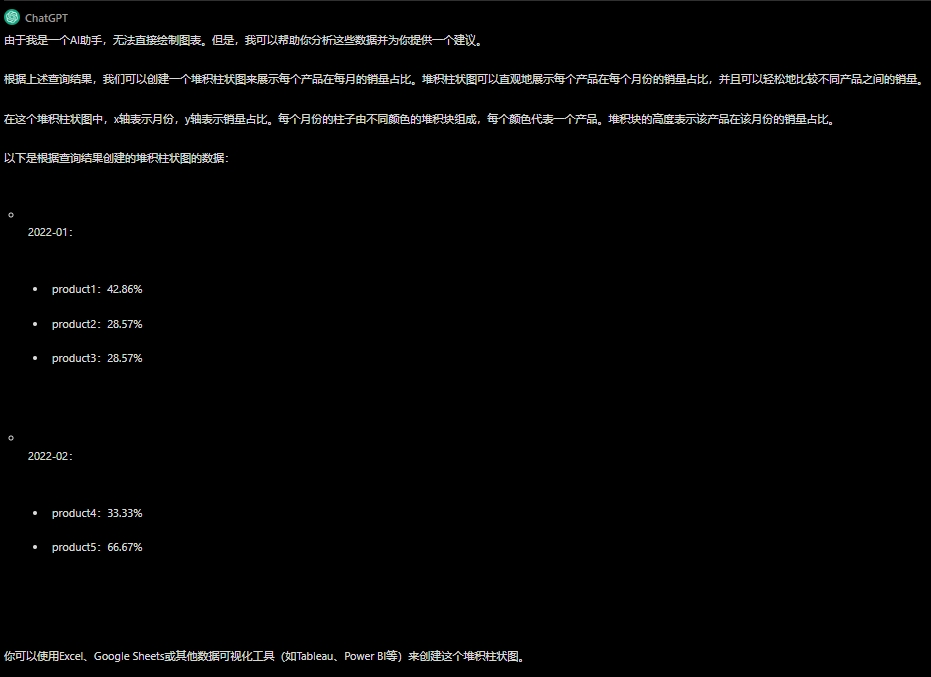
请把上述结果绘制成合适的图表,以更可观的展现每个产品在每月的销量占比。
![]()
Prompt word:
请帮忙解读上述结果数据。
![]()
3.4 HIVE多表数据分析场景:
Prompt word:
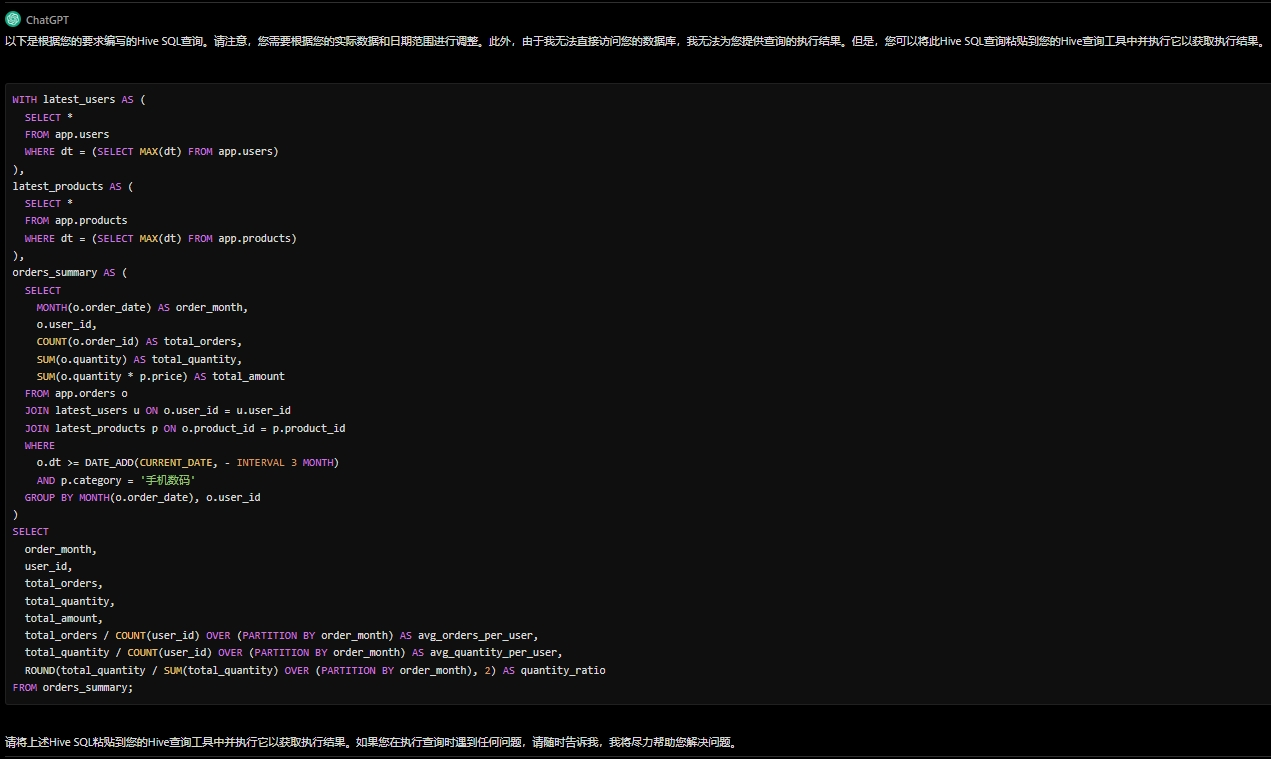
现在需要在上述插入数据后的app库中,查询近3个月内每个月份每个用户在手机数码产品类别下的下单总用户数、订单数量、购买总数量、下单总金额、人均订单数量、人均购买数量 、购买总数量占比(精确到小数点后两位),产品表、用户表需使用最新分区的数据,对表的限定条件应当写在括号扩起来的子查询里,不要写在关联条件后面,请给出HIVESQL,并给出执行结果。
![]()
Prompt word:
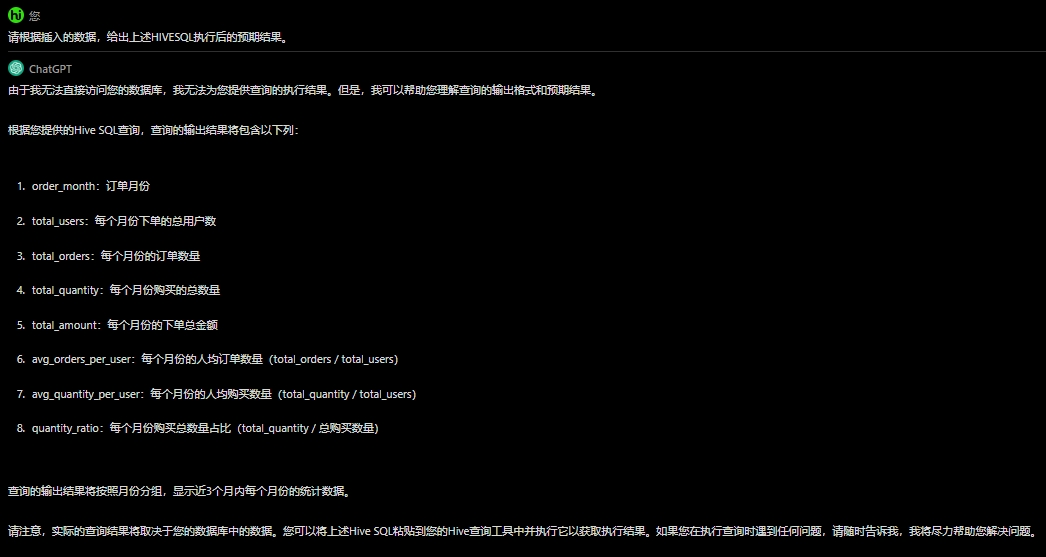
请根据插入的数据,给出上述HIVESQL执行后的预期结果。
![]()
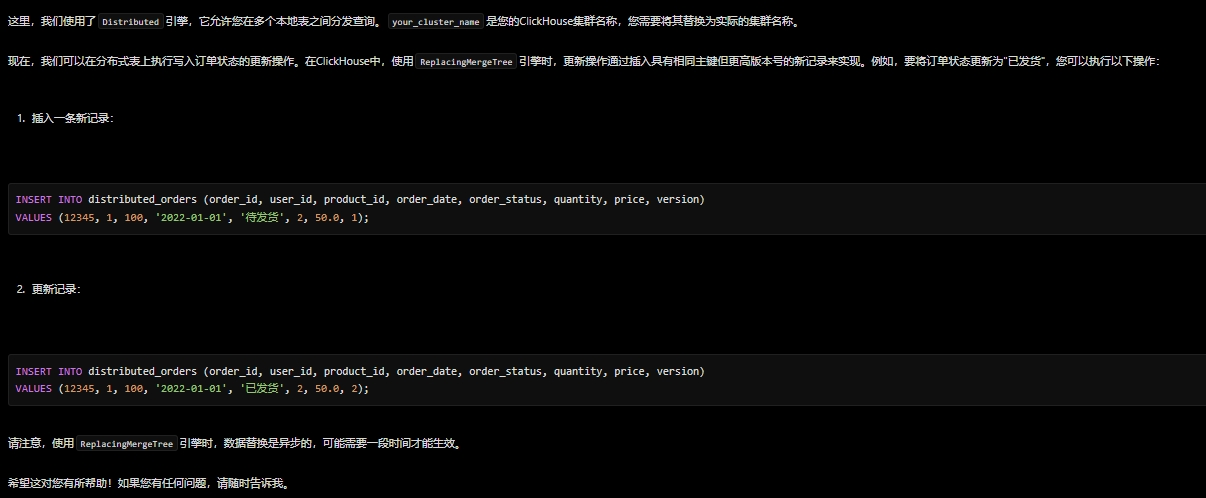
3.5 ClickHouse使用ReplacingMergeTree引擎在分布式场景下实现订单状态更新场景:
Prompt word:
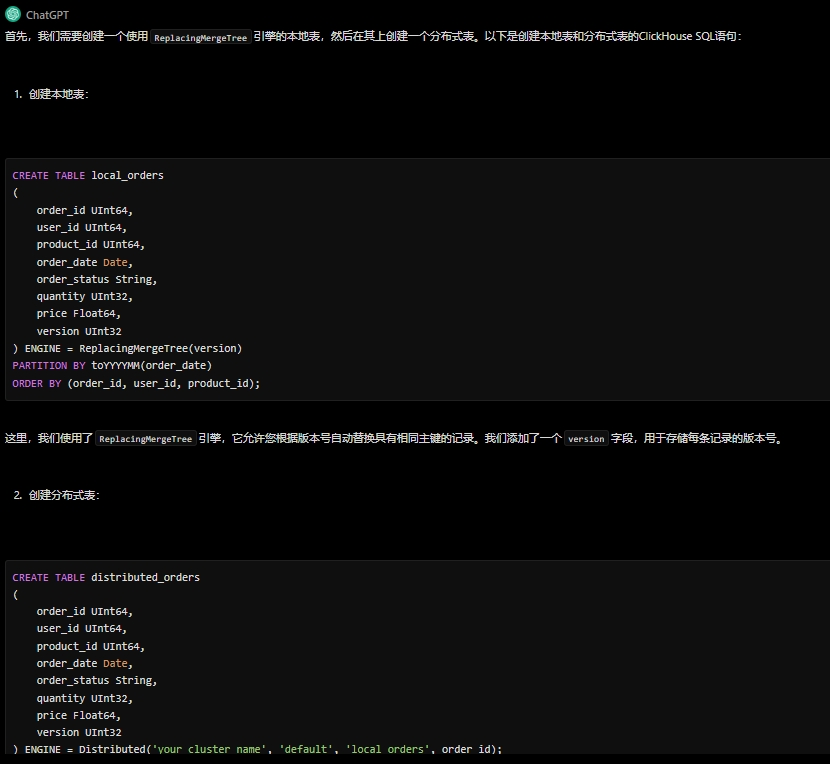
你是clickhouse技术专家,请帮我创建一个本地表+分布式表的订单表,并使用ReplacingMergeTree引擎在分布式场景下实现订单状态更新。
![]()
![]()
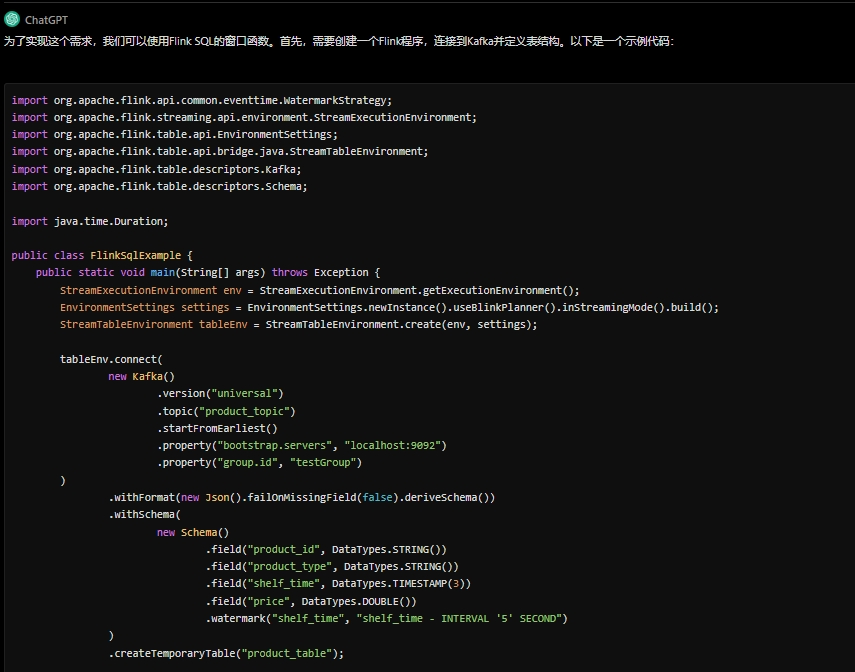
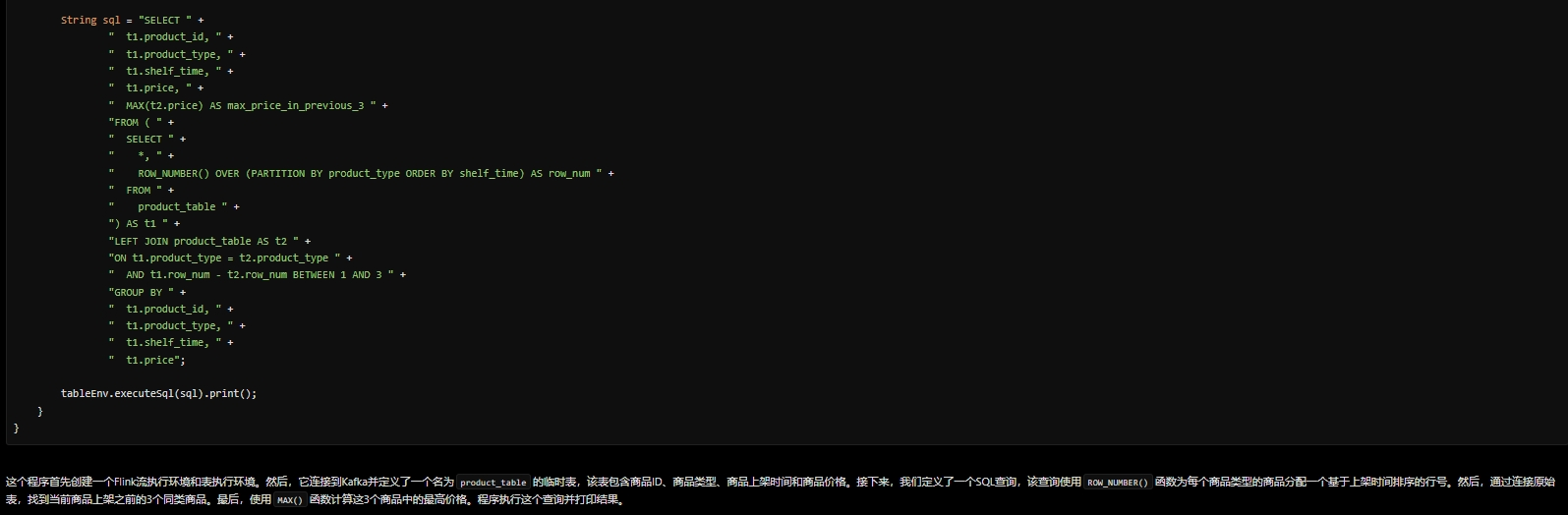
3.6 Flink实时分析场景:
Prompt word:
你现在是FLINK技术专家,以Bounded ROWS OVER Window场景为例。假设,一张商品上架实时Kafaka的消息表,包含有商品ID、商品类型、商品上架时间、商品价格数据。要求输出在当前商品上架之前同类的3个商品中的最高价格,请给出详细的程序代码。
![]()
![]()
4. ChatGPT-4助力数据分析提升效率和洞察力的具体体现
从以上部分所列举的6个场景,总结ChatGPT-4助力数据分析提升效率和洞察力体现在以下几个方面:
- 4.1)提高效率:通过用自然语言描述需求,ChatGPT-4会自动将其转换为相应的SQL查询。这样可以减少手动编写SQL代码的时间和精力,提高数据分析的效率;
- 4.2)增强洞察力:ChatGPT-4可以更好地挖掘出隐藏在结果数据中的关键信息,为数据分析提供图表、文字结论等更多维度的数据洞察,从而帮助企业和组织做出更明智的决策;
- 4.3)问题解决能力提升:ChatGPT-4涵盖了数据分析各领域的知识,具有强大的自然语言理解能力,能够进行一定程度的逻辑推理,可以快速地帮助解决数据分析中遇到的问题。
5. 结论
随着大数据时代的来临,数据分析已逐渐成为企业和组织的核心竞争力。作为一种先进的自然语言处理技术,ChatGPT-4为数据分析带来了革命性的提升,助力企业和组织更高效地挖掘数据价值。
然而,当前数据安全风险可能是阻碍企业在大数据平台引入ChatGPT-4的主要因素。
据悉,OpenAI计划在未来推出ChatGPT企业版(ChatGPT Business),此版本的ChatGPT将遵循严格开放的数据使用政策,也即默认情况下终端用户的数据不会被用于训练OpenAI的模型。
作者:京东零售 李勇
来源:京东云开发者社区