![]()
![]()
设计:小艾
审核:丁奇、宇亭
编辑:宇亭
作者一:徐鑫强(花名:无花果)
电子科技大学-计算机技术-在读硕士、StoneDB 内核研发实习生
作者二:柳湛宇(花名:乌淄)
浙江大学-软件工程-在读硕士、StoneDB 内核研发实习生
一、MySQL 连接方式简介
MySQL 支持自然连接、等值连接(内连接)、左连接、右连接、交叉连接五种连接方式,不支持全外连接,全外连接可以通过 Union 并集操作实现。连接算法:简单嵌套循环、索引嵌套循环、块嵌套循环以及哈希连接。
简单嵌套循环(Simple Nested-Loop Join,SNLJ)
驱动表中的每一条记录与被驱动表中的所有记录依次比较判断,驱动表遍历一次,被驱动表遍历多次。此算法开销非常大,假设驱动表的行数为 M,被驱动表的行数为 N,则算法时间复杂度为 O(M*N)。实际上,MySQL 并不会使用此算法。
![]()
基于索引的嵌套循环(Indexed Nested-Loop Join,INLJ)
通过在被驱动表建立索引,减少被驱动表的扫描次数。一般 B+树的高度为 3~4 层,也就是说匹配一次的 I/O 消耗也就 3~4 次,因此索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为驱动表。在有索引的情况下,MySQL 会尝试使用此算法。整个过程如下图所示:
![]()
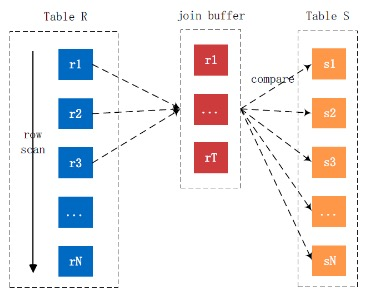
基于块的嵌套循环(Block Nested-Loop Join,BNLJ)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后在内存中比较匹配条件是否满足。但内存里可能并不能完全存放的下表中所有的记录。为了减少访问被驱动表的次数,我们可以首先将驱动表的数据批量加载到 Join Buffer(连接缓冲),然后当加载被驱动表的记录到内存时,就可以一次性和多条驱动表中的记录做匹配,这样可大大减少被驱动表的扫描次数,这就是 BNL 算法的思想。当被驱动表上没有建立索引时,MySQL 会尝试使用此算法。整体效率比较:INLJ > BNLJ > SNLJ。整个过程如下图所示:
![]()
哈希连接(Hash Join)
嵌套循环连接对于被连接的数据集较小的情况是较好的选择,而对于大数据集 Hash Join 是更好的方式。优化器使用两个表中的较小表在内存中依据 Join Key 建立哈希表,然后依次扫描较大表并探测哈希表,找出能与哈希表匹配的行。Hash Join 会破坏表数据的有序性和局部性,因此它只能应用于等值连接。
二、哈希连接的优化方向简述
随着 MySQL 8.0 对 Hash Join 支持,在内外表均无索引或大表驱动小表的情况下,Hash Join 显然是比 BNLJ 更好的选择,而在 AP 场景下,大量数据多表 Join 的刚需也使得 Hash Join 有了多种方向的优化路径。本章简要介绍一部分对 Hash Join 优化的方向和思路。
一个关键的前提是,前述介绍提到了 Hash Join 不适用于非等值连接,因此当表连接语句语句中未使用ON <attr1>=<attr2>样式的等值连接方法或默认的自然等值连接时,MySQL 不会使用 Hash Join。
首先应当明确 Hash Join 的工作流程,以 MySQL 为例 [1] ,MySQL 就使用了经典的单线程 Hash Join 实现,它有建表(build)和探测(probe)生成结果两个步骤。
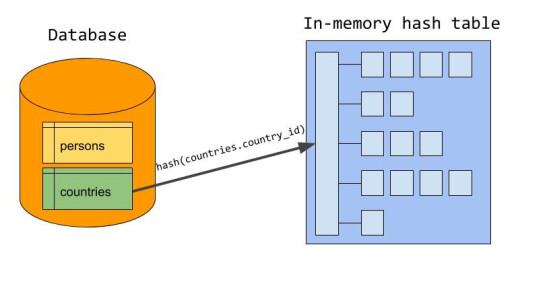
-
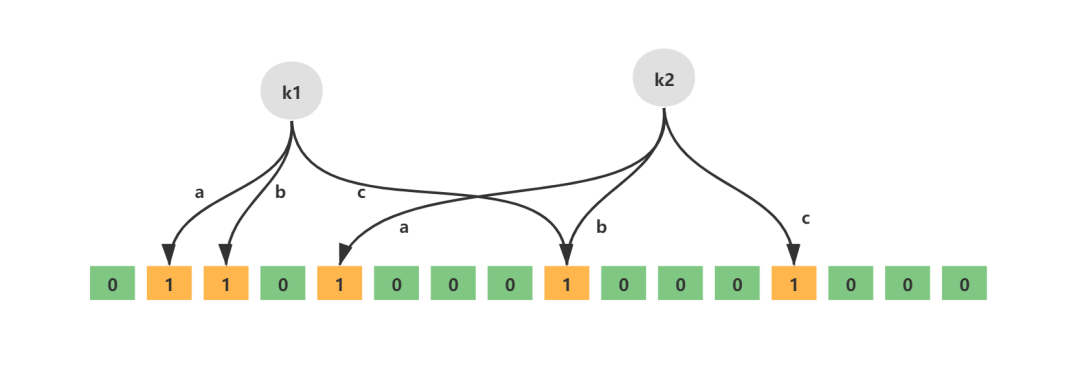
「建表」:如下图所示,建表就是遍历 OuterTable,将其等值连接键计算哈希值并根据结构构建为一个哈希表:
![]()
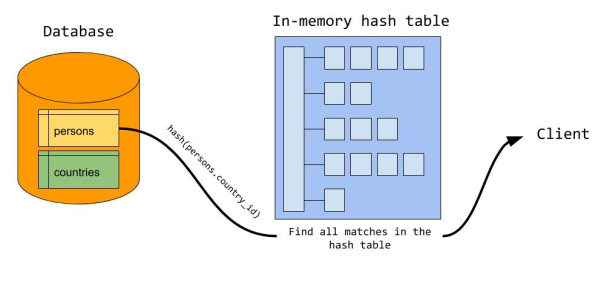
-
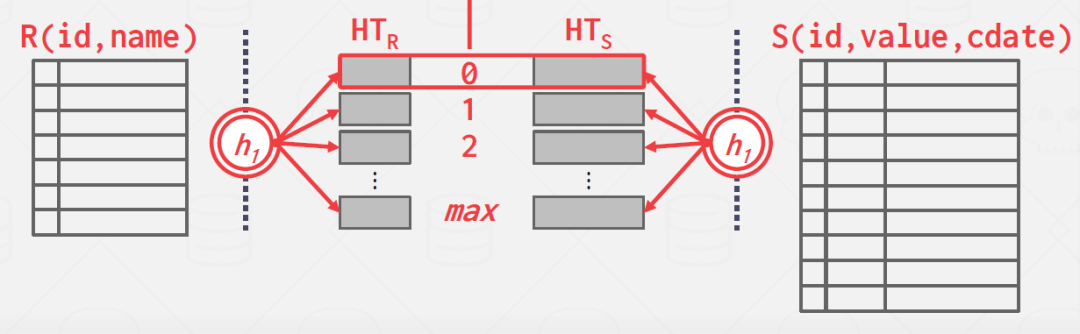
「探测」:如下图所示,探测步骤就是遍历 InnerTable,计算每个 tuple 的值连接键的哈希值并从哈希表中找到对应的桶(bucket),并通过对比决定是否能进行哈希连接,进而完成整个 Hash Join 过程 [2] 。
![]()
2.1 哈希算法的选取
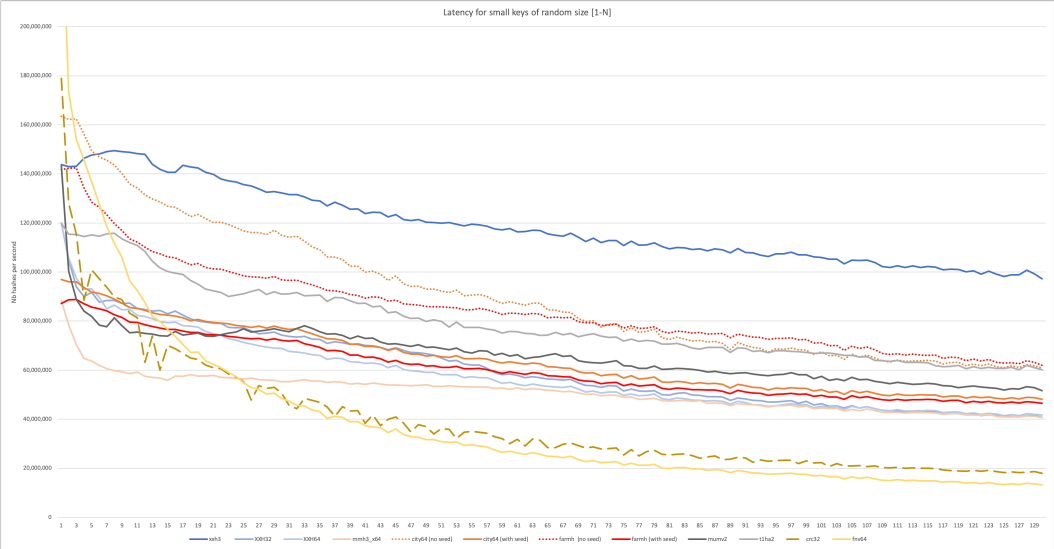
哈希算法是 Hash Join 的基础,好的哈希算法可以极大提升依赖哈希操作的程序的效率。优秀的哈希函数会在随机性(体现发生哈希冲突的概率)和计算效率(单词计算哈希的速度)之间做 trade-off,因此不同侧重方向的数据库也应当选择合适的哈希函数,如 Apache Doris[3]选择了 CRC32 这一计算速度很快且可以通过 SIMD 加速的哈希函数,而 DuckDB 选择了随机性更高的 MurmurHash[4]。
但时至今日,随着 XXhash[5]的问世,哈希函数的选取似乎真正拥有了银弹。对于绝大多数的 HashTable 这种哈希长度相对较小的场景,XXHash 的不同长度变种似乎都是最佳选择:
![]()
2.2 哈希表的基础结构设计
哈希表基础结构设计的一个基础点就是其处理冲突的方法,经典的处理方法有开放寻址法(即在哈希冲突时使用线性探测、平方探测、重哈希等方法继续在哈希表中搜索)和拉链法(在 bucket 中存储链表或平衡二叉树代表的冲突子项)。拉链法是更直观和更低哈希冲突率的做法,因此其多见于 Java/Go 等编程语言的哈希表实现。然而对于数据库内核中的哈希表,应用大数据量、控制内存使用量和 Cache Miss 率等都是优先级更高的需求,因此线性探测等开放寻址的冲突处理方法是构架哈希表的更优解。
另一个关键的基础结构设计是哈希表扩容的机制,大部分哈希表的扩容机制是在当已有元素站总容量比例超过一定阈值(对于 DuckDB,这个阈值是默认是 50%,对于 Java 的 HashMap,这个阈值默认是 75%)后进行扩容。但是显然对于线性探测的冲突处理方法,哈希冲突的概率由于哈希聚集(hash clustering)的原因会随占用率提高而迅速增加,因此一般线性探测的冲突处理方法设定的阈值较低,这也导致了内存的浪费。因此有一系列的工作[6] 通过 rehash 或维护细粒度数据结构等方法改善这一情况。
对于数据库内核这一领域,内核的优化器可以为哈希表提供可用的结构优化和先验知识。如对于列式存储数据库,可以通过 build 过程下推,直接以内核中读取的压缩后的键进行哈希表的构建合并,减少序列化和反序列化开销并减小 hash key 长度。此外,可以通过优化器的统计数据,将需要建表的数据剪去前缀,这也能进一步地减少 hash key 长度,进而加速哈希函数计算速度。
2.3 对探测过程的优化
由上节可以看出,对于线性探测方法构建的哈希表,哈希冲突是探测操作是的性能瓶颈,因此可以引入一层过滤层,尽早过滤掉不在哈希表中的探测键值,从而减少探测的次数,这一过滤层最经典的实现就是如下图所示的布隆过滤器[7]。
![]()
本文不再深入阐述布隆过滤器的算法原理和优化方法,读者只需要知道,布隆过滤器可以通过若干个哈希函数(实践上,它们由一个基础哈希函数和位移、累加操作得到)操作一个 bitmap,通过对 OuterTable 的等值键遍历进行构建并由 Inner Table 探测。其特点是存在假阳性(False Positive),但不存在假阴性(False Negative),即通过布隆过滤器的记录并不一定真的能够匹配(可能存在哈希冲突),但被过滤掉的记录一定不匹配。
在布隆过滤器的基础上,还有一系列的概率数据结构变种,如 Block Bloom Filter,Cuckoo Filter[8]等 。不过对于不需要删除,操作相对固定的 Hash Join 场景,实现简单,占用内存少的布隆过滤器是大部分情况下的最佳选择。
2.4 对 Cache Miss 的优化
哈希表访存的随机性不可避免地会提升 cache miss 率而不得不通过页表访问内存,这会使得 Hash Join 遭遇性能瓶颈。现代计算机处理器的最大缓存粒度是 LLC(Last Layer Cache,在广泛应用的 Intel/AMD 处理器上,它是 L3 缓存),因此以 LLC 大小为单元的内存区域操作是对 Cache Miss 率优化的出发点。一个简单的方法是条件化预读取(Conditional Pre-fetching):哈希表可以维护关于哈希冲突数量、占有率以及哈希冲突热点区域的元数据,并根据这些元数据判断一次 probe 是否可能产生大量的哈希冲突,并在可能产生冲突时以 LLC 大小为单位预读取若干个 bucket 到内存,这样线性探测方法将可以减少 cache miss 数量。
更复杂的方法则是按如下图的方式构建分区哈希表(Partitioned Hash Table),即按照一定的标准(这个标准可以参考优化器提供的统计数据)将 Outer Table 在建表时放入不同的子哈希表(称为 Partition),而遍历 Inner Table 时,可以使用同样的标准将比较的 key 路由到对应的 Partition 中进行哈希查找和比对。这样做意义有三点
-
首先就是通过让每个 Partition 能够被装入 LLC,使得处理一个 Partition 的构建和探测任务时大大降低 Cache Miss 率;
-
可以更细粒度地管理哈希表的内存使用,哈希表可以不以 2 的幂的形式分配内存(以 Partition 为基本分配单位),同时在极限情况下也可以释放部分空的 Partition 以移作他用;
-
使得并行构建哈希表成为可能,这部分由 2.5 节阐述。
![]()
接下来的问题是,如果快速且有效地将整个哈希表且分为若干分区表,为了保证这一过程的效率,Radix Hash Join[9]的流程被提出。
2.5 多线程哈希连接的优化
MySQL 的 Hash Join 是单线程执行的。但通过例如上述构建布隆过滤器和分区哈希表的方法,我们可以实现多线程执行。
布隆过滤器本身的构建和探测类似于哈希表的构建和探测,因此二者可以类比分析。布隆过滤器的变种 Blocked Bloom Filter 通过数学证明可以与布隆过滤器有类似的效能,但可以通过开多线程并行构建每个 Block,并空值 Block 大小适配 CPU 核的缓存,并通过 SIMD 加速探测操作。Hash Join 的探测操作类似,将 Inner Table 的记录切为若干个线程并发处理的任务段后,并行地对哈希表进行探测,并在需要时将最后的结果进行 Merge 操作以保证数据有序性,这一点类似于排序-归并连接的算法。
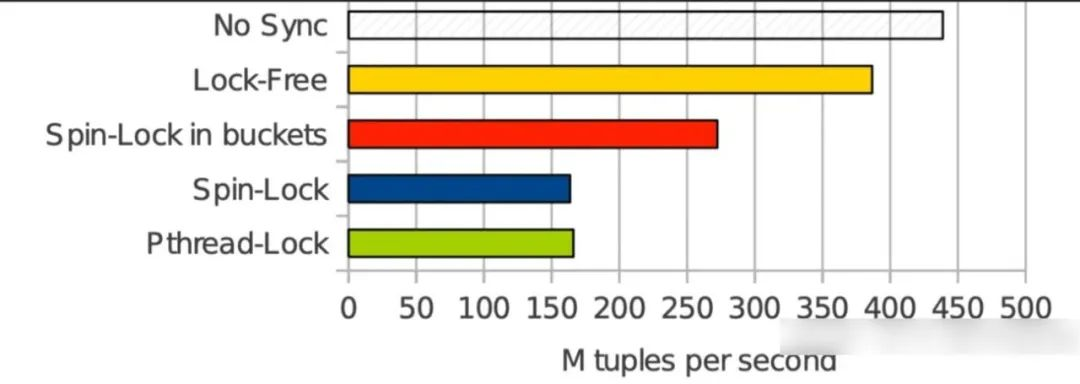
而构建操作则先得到更加复杂,因为它存在写操作写操作,即使是对 Partitioned Hash Table,仍然要进行 Partition-wise 或 Bucket-wise 的加锁-解锁操作才能并行执行。因此需要同步措施来保证线程之间数据的一致性和正确性,在目前的工业实践上,通过被大部分主流处理器支持的cmpxchg指令实现的 CAS(Compare And Swap)操作是 CPU 密集操作的最佳实践:
![]()
本图引用自互联网,侵权联系删除