本文分享自华为云社区《GaussDB(DWS)现网案例之超大结果集接收异常》,作者:你是猴子请来的救兵吗 。
问题背景
内核版本 GaussDB 8.1.3
问题描述 用户使用数据库客户端工具如navicat、dbeaver等执行查询语句异常中断,中断信息"Last read message sequence %d is not equal to the max written message sequence %d"
问题定位
客户端异常中断后有些错误信息时不感知的,此时topsql就派上了用场。历史topsql记录了查询作业运行结束时的资源使用情况(包括内存、下盘、CPU时间等)和运行状态信息(包括报错、终止、异常等)以及性能告警信息。而对于由于FATAL、PANIC错误导致查询异常结束时,状态信息列只显示aborted,无法记录详细异常信息。
1,此时我们通过历史topsql查询视图查询语句执行情况
--当前CN
select * from GS_WLM_SESSION_HISTORY;
--所有CN
select * from PGXC_WLM_SESSION_HISTORY;
![cke_124.png]()
根据topsql记录结果发现语句存在abort_info为
Last read message sequence %d is not equal to the max written message sequence %d
可知,查询执行遇到FATAL、PANIC错误导致查询异常结束
2,接着确认日志信息,通过线程ID查看当时语句执行情况,发现客户端存在异常中断
![cke_125.png]()
根因分析
前提:
cn_retry开启+查询语句+max_cn_temp_file_size临时文件开启
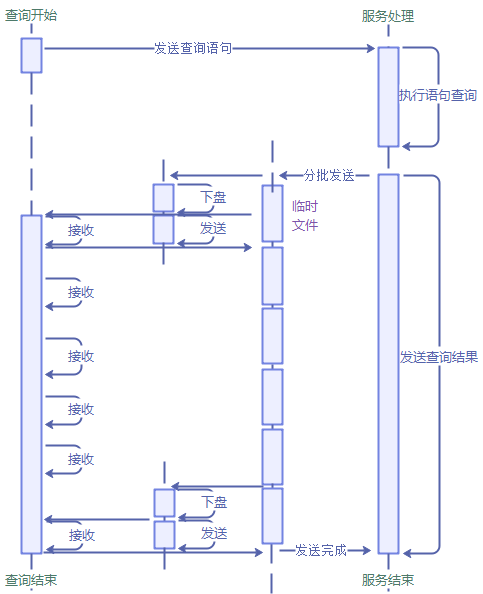
发送逻辑:
服务端执行查询之后,会通过发送缓冲区往客户端发送数据;当查询结果集过大,则发送缓冲区满了之后,会往临时文件写数据;当临时文件超出max_cn_temp_file_size指定的最大值时(此时会禁用cn_retry),需要分批发送,此时会先将已写入临时文件的数据发送至客户端;然后继续将剩余数据写入新的临时文件发送,以此循环,直到所有数据发送完成。
![cke_126.png]()
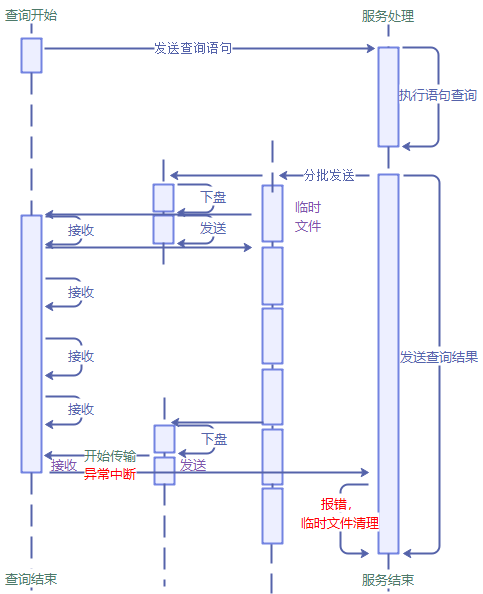
问题场景:
当临时文件超出最大值时,先将其发送至客户端,此时客户端断连(如产生oom),数据发送中断,此时已发送数据量与已写入临时文件的数据量不一致,因此产生报错
Last read message sequence %d is not equal to the max written message sequence %d
此报错代表已写入临时文件的数据与已发送到客户端的数据量不一致,实际场景为客户端异常导致的发送数据中断,因此报错内容符合预期。
![cke_127.png]()
相关知识
相关guc参数:
1,cn_send_buffer_size:指定CN端数据发送数据缓存区的大小。整型,8~128, 单位为KB。默认8KB
2,max_cn_temp_file_size:指定SQL语句出错自动重试功能中CN端使用临时文件的最大值,设定为0表示不使用临时文件。默认5G
相关日志记录:
1,临时文件超出max_cn_temp_file_size,记录" %s temp file exceeded, max temp file size : %d KB, current result size : %ld KB"
2,客户端异常导致数据发送失败,记录"could not send data to client [ Remote IP: %s PORT: %s]. detail:%s"
3,数据发送中断或结束,当已发送数据和已写入临时文件的数据量不一致时,记录"Last read message sequence %d is not equal to the max written message sequence %d"
场景复现
创建普通表即可,导入一定量的数据,执行简单查询使其返回较大的结果集,如
select * from store_sales;
为了方便场景复现,临时将允许的临时文件最大值调整为500M,便于触发分批发送。
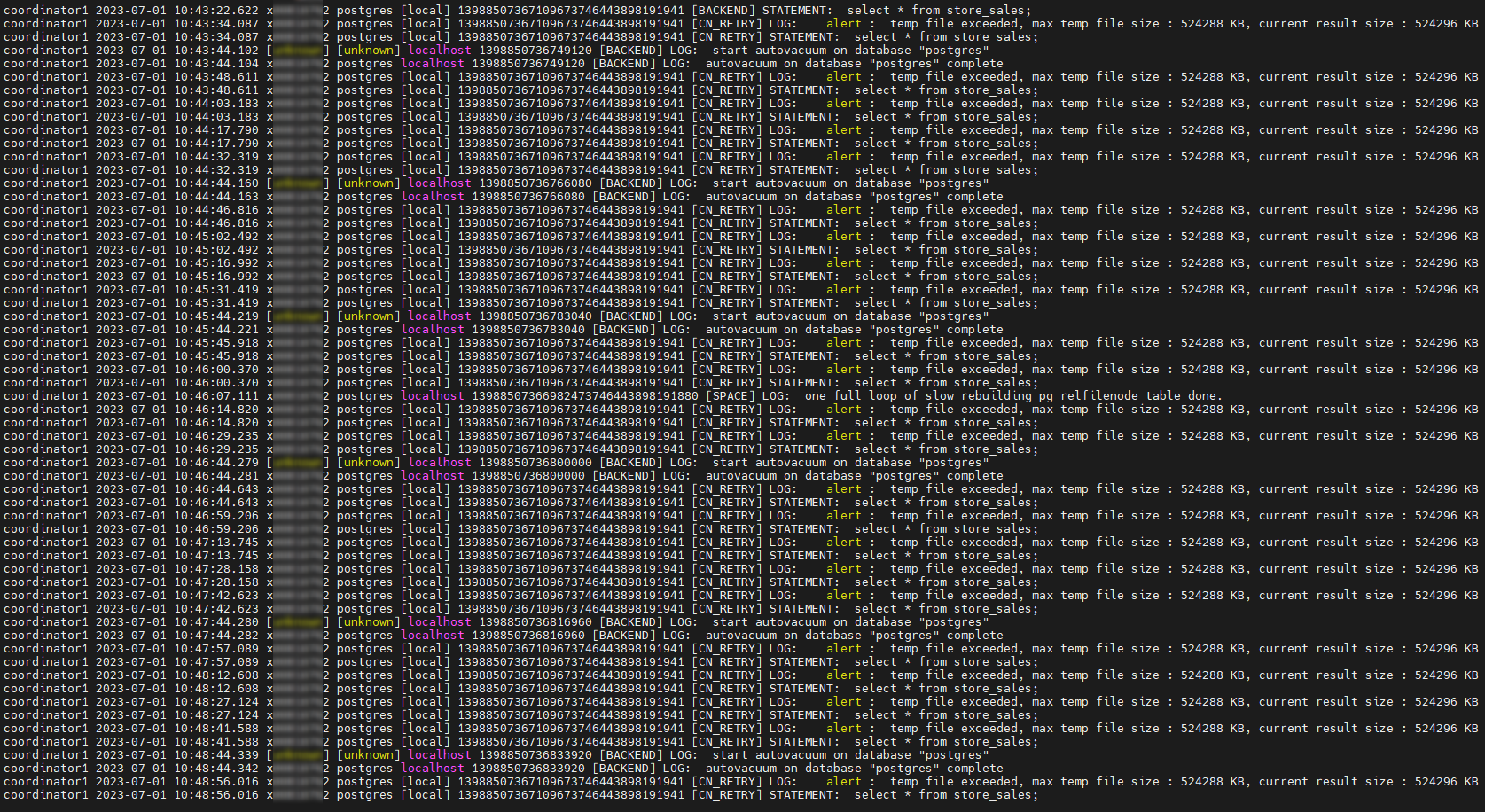
1,正常接收场景
此时客户端环境内存足够,可正常接收数据,超大结果集将通过临时文件下盘的方法分批发送,直到所有数据发送完成。
![cke_128.png]()
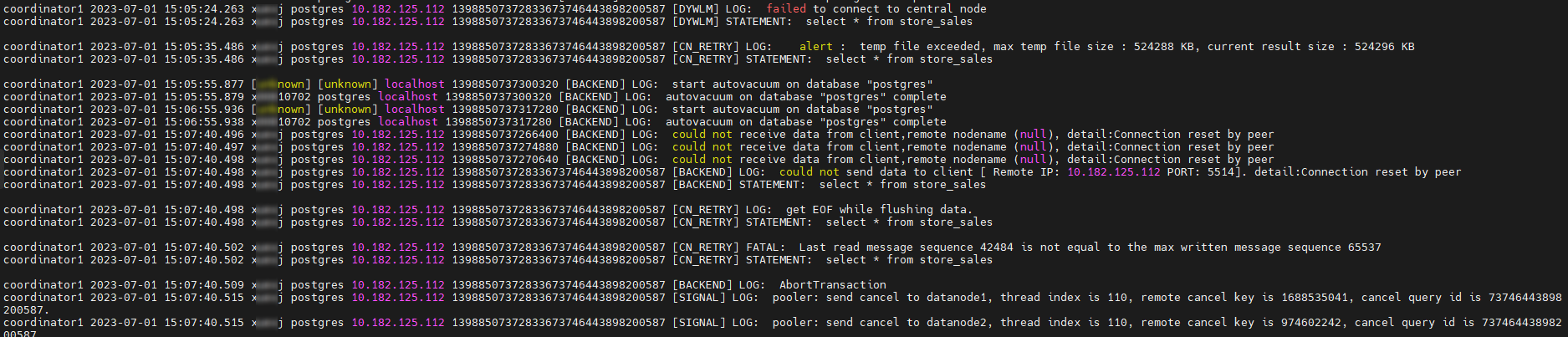
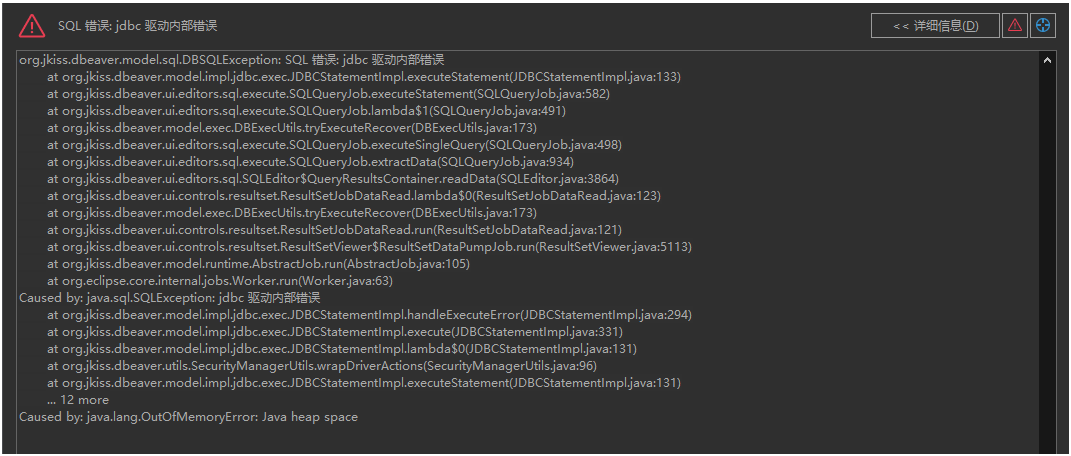
2,异常中断场景
此时客户端环境允许的数据量优先,超大结果集将分批发送的过程中,客户端触发OOM异常中断,服务端会记录客户端异常发送失败信息以及已发送数据不一致的错误信息。
![cke_129.png]()
![cke_130.png]()
改善办法
1,避免超大结果集的查询,如果无法避免,则通过分页或游标多次查询
2,增大客户端支持的运行内存,防止内存不足
知识小结
1,报错Last read message sequence %d is not equal to the max written message sequence %d为超大结果集返回异常中断时的报错,符合预期,需通过业务语句的改写或客户端环境的改善来解决。
2,TopSQL查询监控的原理和适用方法可参考:GaussDB for DWS 资源监控核心技术解密: TopSQL查询监控解密
点击关注,第一时间了解华为云新鲜技术~