![]()
本期将由 KaiwuDB 高级研发工程师孙路明博士为大家介绍《SUFS: 存储资源使用量预测服务》,本文将发布于 ICDE 2023。
点击链接,回看本次直播>>
https://www.bilibili.com/video/BV1vV411g7JH/?spm_id_from=333.999.0.0&vd_source=700806cd73b4ea3118fa9731a4008731
一、背景介绍
1. 存储资源使用量预测的意义
在典型的 IT 服务或应用中,计算、网络、存储是支撑上层应用服务的三个基础,保证存储系统的可用性对服务和应用的稳定运行有重要意义。存储系统可用性的一个重要方面就是有足够的容量,可以满足写入、存储的需求,所以合理规划存储系统的空间资源就非常重要。为了规划存储系统资源,就需要对资源的使用量进行预测,在预测的基础上进行资源的规划、扩缩容等操作。
由于目前很多存储是以云服务的形式提供的,对存储资源进行预测对于服务的提供商和使用者都很重要。对服务商来说,准确的预测资源使用量可以帮助他们在保证服务的 SLA 同时避免额外的开销;对用户来说,可以在满足自己业务需求的情况下更合理的申请配额(Quota)或者购买资源。
本文关注的存储系统范围比较广泛,包括传统的文件存储、各式各样的分布式存储系统,比如最典型的 HDFS,也包括各种数据库系统,比如 MySQL 这类关系型数据库或者各类的 NoSQL 数据库等等。
2 存储资源使用量预测的现状和挑战
现在一些存储系统的容量规划比较依赖启发式规则或者人的经验知识,对未来的使用量预测的不准,这种不准确又可以分为高估( overestimation)和低估(underestimation),这两种不准确也会产生不同的影响。
如果高估了未来的资源用量,那就会过多的配置存储资源,导致空间浪费和不必要的开销;如果预测的偏低,那可能会造成存储资源不足,严重的话会导致数据无法写入和数据丢失的风险,影响系统的可用性。
如下图所示,造成启发式规则或传统时序预测模型在存储资源使用量预测任务中无法提供准确预测的原因主要有两个:
![]()
因此,本文提出了一种增强的 LSTM 神经网络应对存储资源使用量时序数据中的突增突降问题,提出了自适应的模型集成方案解决不同系统、同一系统内不同用户存储资源使用量模式差异大的挑战。
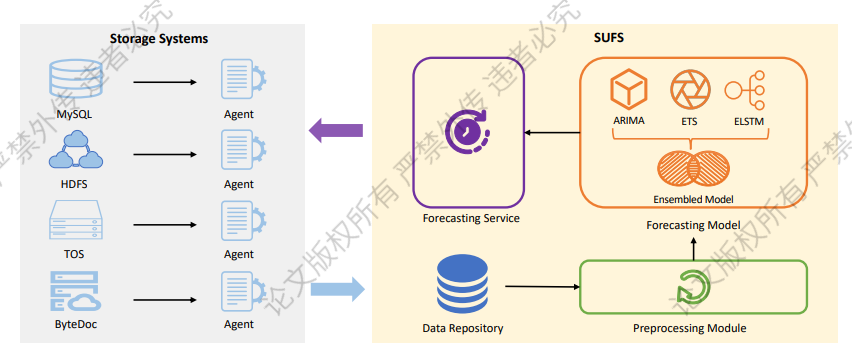
二、SUFS 架构与算法
![]()
如上图所示,SUFS 在不同的存储系统中使用 Agent 采集存储空间使用量的历史数据并存储,在对数据进行预处理后,使用自适应模型集成方法对未来多天的存储资源使用量进行预测,根据预测结果提供资源的监控告警、容量规划、动态扩缩容等服务。
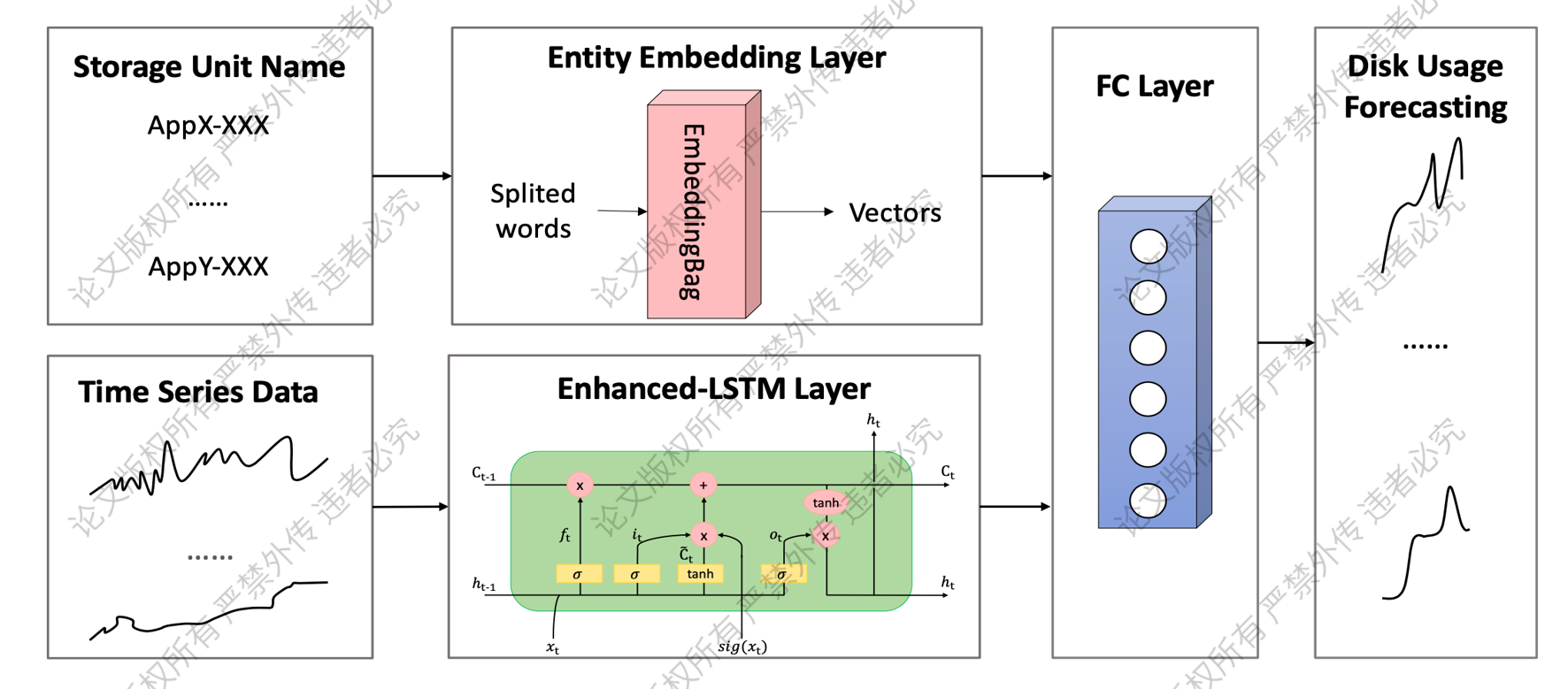
1.增强 LSTM 神经网络
LSTM(Long Short-Term Memory)是一种循环神经网络 RNN 的变体,本文提出的增强的 LSTM 神经网络,在普通 LSTM 神经网络的 Input Gate 前加入额外的一个信号量,该信号量的值与磁盘使用量的值是否为突增突降有关,而判断是否突增突降使用了 IQR 检验方法。
其工作原理为:如果 IQR 判断当前的磁盘使用量值是突增或突降,则该信号量是一个极小的值,在 LSTM 内部就可以控制当前使用量不对已有状态产生影响,使得模型忽略掉这些突变;而当没有遇到突增突降时,这个增强的 LSTM 神经网络模块与普通 LSTM 无异。
此外,这个神经网络还考虑到属于同一用户或服务的存储资源使用具有类似模式的现象,通过存储资源实体编码嵌入网络,将这种先验知识加入到模型的预测中。
![]()
2.自适应模型集成算法
为了在一个统一的预测服务中完成不同模式时序数据的预测,这篇文章提出了一种自适应的模型集成方法:
模型集成(Model Ensemble):机器学习的一种范式,在模型集成时,通常会训练多个模型解决相同的问题,并且把这些模型的结果结合起来以获得更好的结果。
这些被集成的模型称为弱学习器或者叫基模型,当基模型被合理的组合起来的时候,我们可以得到更准确或者更鲁棒的预测结果。一些常见的模型集成方法包括 Bagging、Boosting、Stacking 等,本文中用到的方法属于 Stacking 这一类,是将多个基于不同算法的基模型的预测结果,通过某种方式将结果组合起来。
使用模型集成的出发点就是因为不同的基模型对于不同模式的时序数据会有不同准确率,比如前面提出的增强的 LSTM 神经网络会更适用于带有突变的时序数据,而 SARIMA 模型更适用于带有周期性的时序数据等。
在将多个基模型的预测结果进行集成时,一种简单并且常见的方案是将不同基模型的预测结果进行加权平均,比如对某一天的使用量预测一个是 10,一个是 8,那集成后的结果就是 9。但是这种平均的集成方案还是存在弊端,不能充分发挥某一个基模型对其适合数据的预测能力,本文提出的模型集成则具有两个特点:
![]()
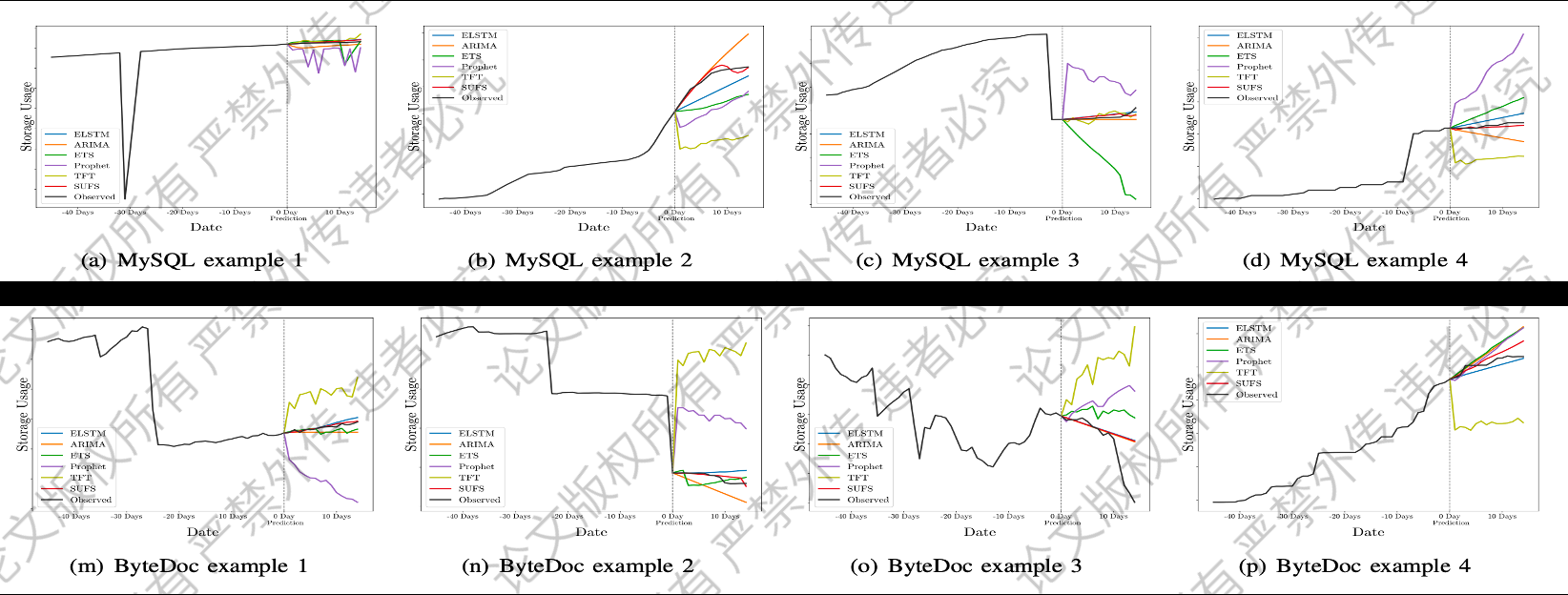
三、实验与总结
本文在多个真实生产环境的存储系统上进行了实验结果验证,从预测误差分布、典型特例分析、存储代价节省、模型预测开销等多个角度验证了提出方法在存储资源使用量预测任务中的有效性。
![]()
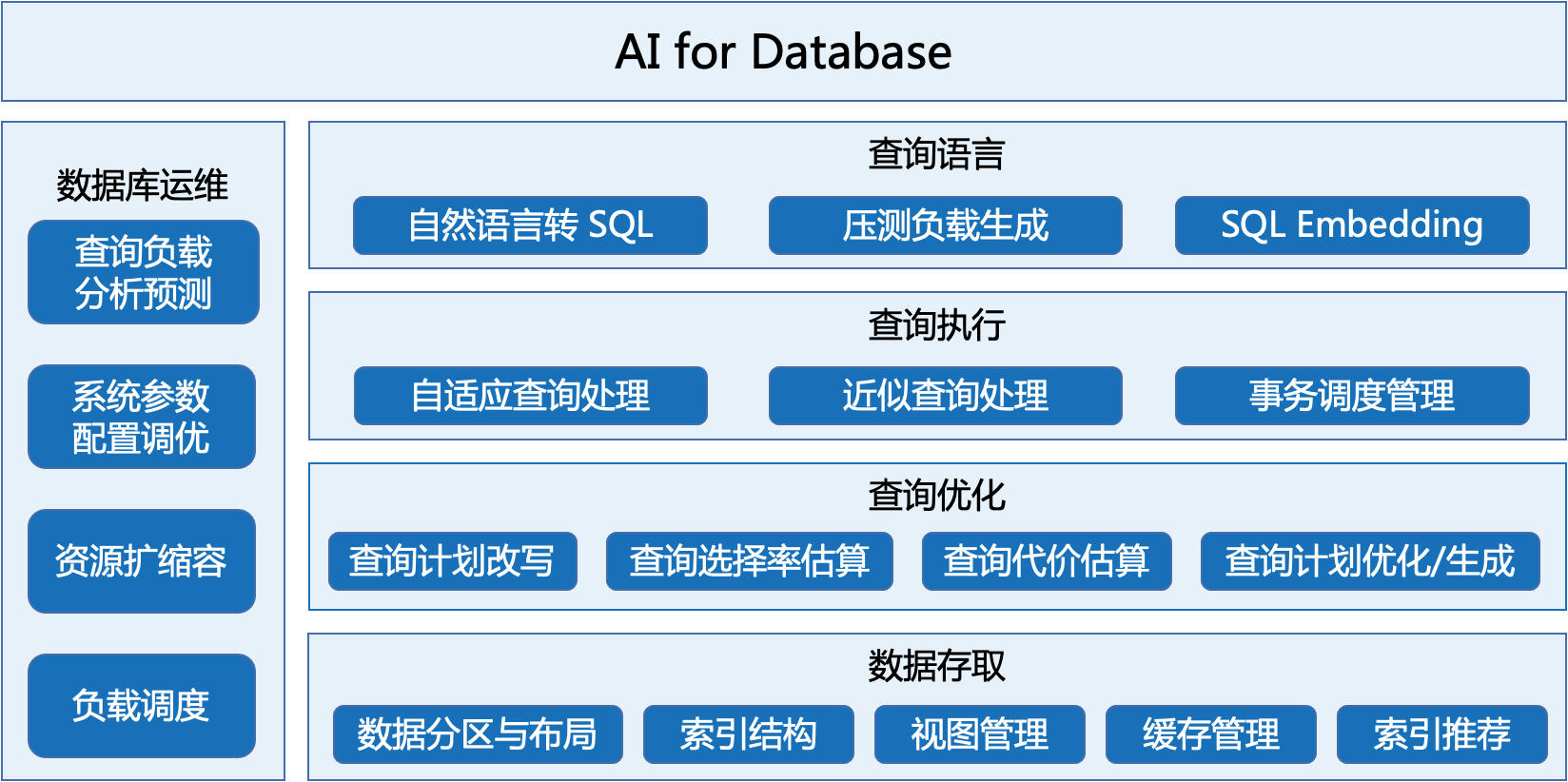
本文所解决的存储空间使用量预测问题,是使用人工智能技术协助系统运维的一个应用,属于 AI for DB 的范畴。AI for DB 包含的内容很多,涉及到数据库的各个方面,KaiwuDB 的 KAP 自治平台,同样提供包含存储空间预测在内的多项自治运维服务。