自 Chrome 113 发布以来,已经过了四个星期,Google 近日也准时发布了 Chrome 114。Chrome 114 默认启用了 CHIPS,这是 Google 通过新的 cookie 属性来淘汰第三方 Cookie 的一部分;Chrome 114 还默认启用了 Popover API,以便更轻松地实现弹框。
![]()
text-wrap:balance
使用text-wrap-balance来改善文本布局。下面的动画显示了你可以通过这一行代码来实现的差异。
![]()
作为一个开发者,你不知道文本的最终尺寸、字体大小,甚至文本语言。所有的变量都是有效处理文本包装的需要。由于浏览器确实知道所有的因素,通过 text-wrap:balance,你可以要求浏览器找出最佳的方案。
![]()
平衡的文本块更讨好读者的眼睛。它能更好地抓住读者的注意力,总体上更容易阅读。
CHIPS: 具有独立分区状态的 Cookies。
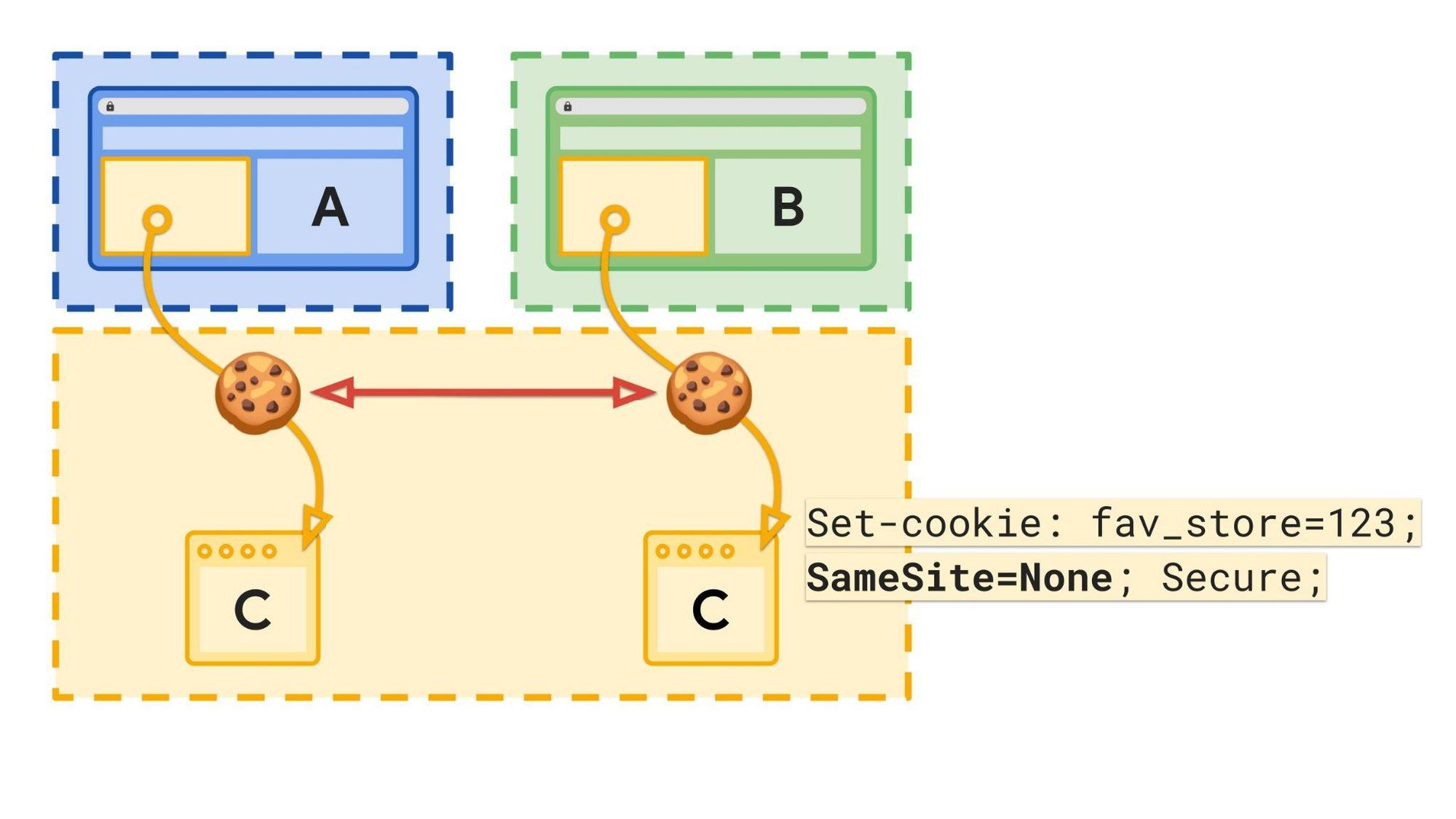
在之前,当用户访问站点 A 时,嵌入式站点 C 可以在用户的机器上设置 cookie。如果用户随后访问也嵌入站点 C 的站点 B,则站点 C 可以访问在站点 A 上设置的相同 cookie。这允许站点 C 跨站点 A、B 及其嵌入的每个站点编译用户的浏览活动。
![]()
虽然跨网站追踪是一个问题,但有一些有效的跨网站 cookie 需求,可以通过 cookie 分区以保护隐私的方式实现。
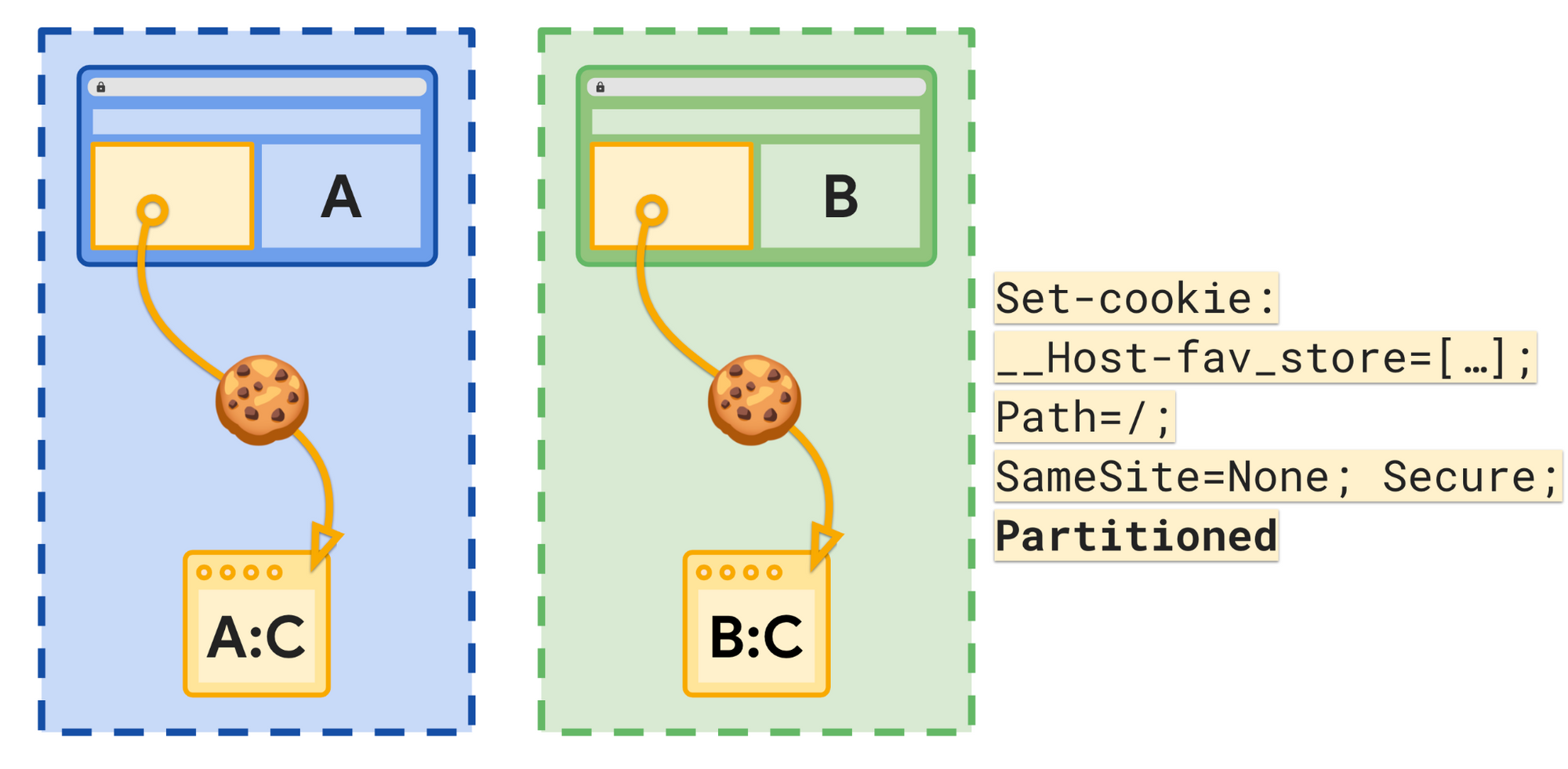
有了 CHIPS,当用户访问站点 A 并且站点 C 中的嵌入内容设置具有 Partitioned 属性的 Cookie 时,对于站点 C 在站点 A 上嵌入时设置的 Cookie,该 Cookie 仅保存在分区 jar 中。浏览器只会在顶级站点为 A 时发送该 cookie。
![]()
当用户访问新站点(例如站点 B)时,站点 C 将不会收到在站点 A 中嵌入 C 时设置的 Cookie。
Popover API
有了 Popover API,就可以更容易地建立临时的用户界面(UI)元素,这些元素会显示在所有其他 Web 应用的 UI 之上。
这些元素包括用户交互式元素,如行动菜单、表单元素建议、内容选择器和教学 UI。新的 popover 属性使任何元素能够自动显示在顶层。这意味着开发者不用再担心定位、堆叠元素、焦点或键盘交互的问题。
其他
- Devtools 让你在支持 DWARF 的 WebAssembly 应用程序中暂停和调试 C 和 C++ 代码
- 在
navigator.bluetooth.requestDevice()中的exclusionFilters选项允许 Web 开发者将一些设备从浏览器选择器中排除。
更多详情可查看:https://developer.chrome.com/en/blog/new-in-chrome-114/