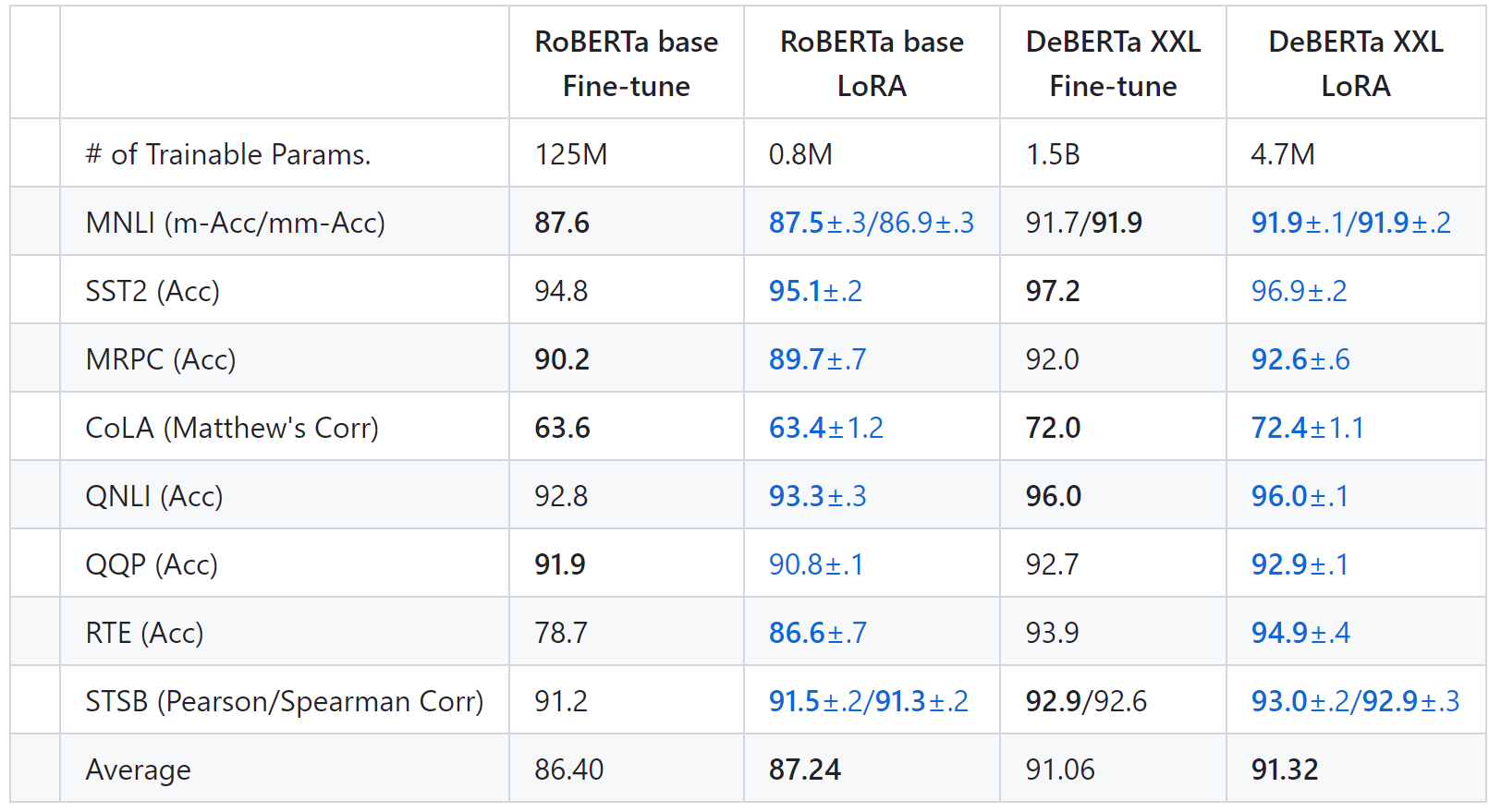
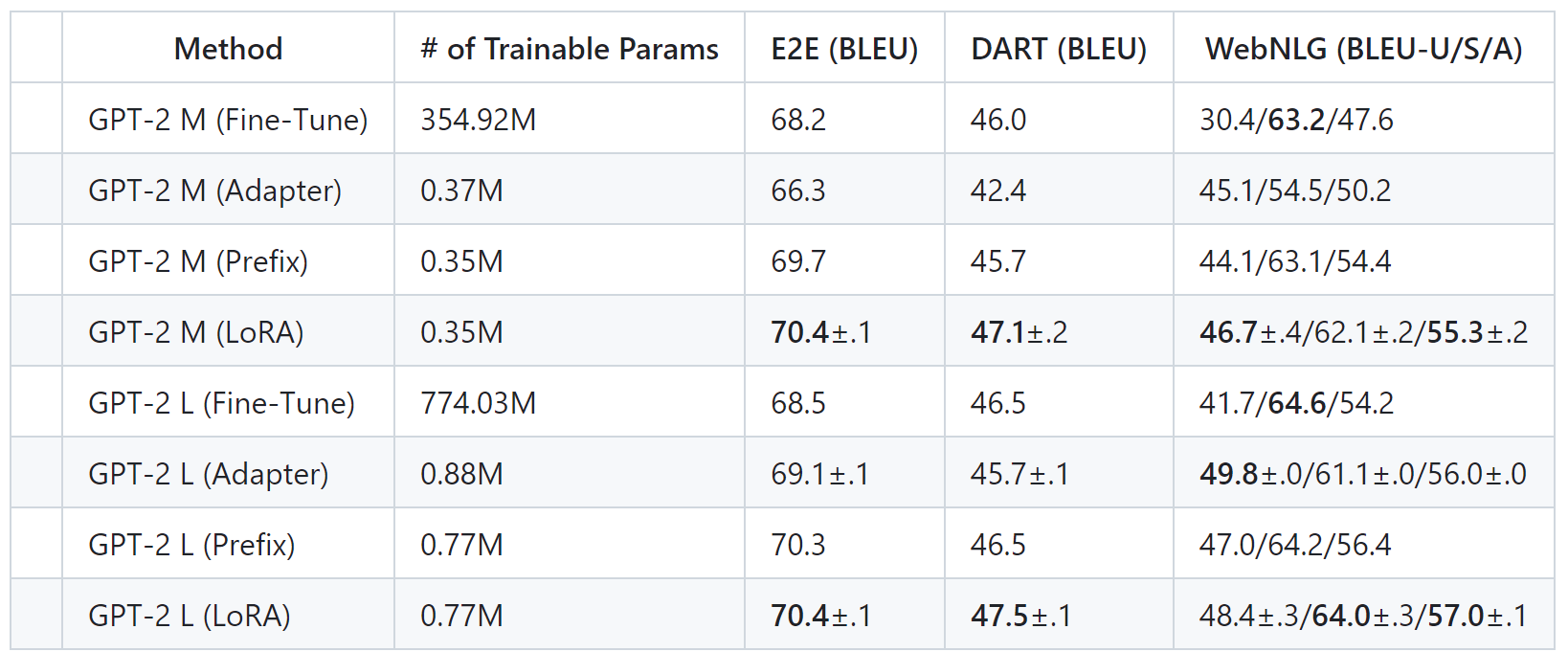

每日一博 | 物流路由线路配载前端算法逻辑实现方案
作者:京东物流 柳宏 1.前置知识 1.1 基本概念 1.1.1 配载 配载代表着某条线路是否具有发往某个方向(区域、省市县、分拣等)的能力,也可以说是网点(分拣中心)是否具有承载配载所指方向货物的能力。一般网络规划者,在均衡线路间货量时,会通过调整配载来完成。 线路上可允许配载货物的“产品类型、最终妥投目的地”,通过线路的配载,计算 当前网点 到 目的网点 的 下一个网点 ,线路 绑定的配载代表通过当前线路最终可以到达的目的地 。以下图为例 表示:如果放置在整个路由网络资源中,一个标记T1的货物要从北京发往福建,可选的路由有①北京站-北京-武汉-福建-福建站;②北京站-北京-广州-福建-福建站;之所以剔除了北京站-北京-上海-福建-福建站以及北京站-北京-武汉-上海-福建-福建站,正是因为后两条线路中未包含T1的配载代码,只标记了T2 ,说明这条线路只有配载航空的货物,而没有普通陆运的带货能力。 下图就是用于描述配载的树形结构 1.1.2 班期与生失效日期 班期:指的是发运频率,1234567代表着每周七天中,这个班次的“上线时间”,一般来讲,维护时缺失某个值,会造成路由中断的...