摘要:其实游戏客户对数据库的诉求是很明确的,数据库应当“放心存放心用”。
本文分享自华为云社区《华为云GaussDB(for Redis)揭秘第27期:聊聊游戏业务怎么用高斯Redis》,作者:高斯Redis官方博客。
华为云数据库团队是比较重视技术洞察的,对客户真实的业务场景也比较看重。年初出差了几次游戏客户现场,有幸跟客户的业务开发和运维聊了聊,发现游戏对Redis的应用其实很多。不过一般都会对自建的开源Redis吐槽比较多,其实也都是常见问题了,例如:
痛点1:开源Redis全部数据放内存,存不下全量玩家,有成本瓶颈
像玩家装备、福利活动领取记录、朋友圈发帖等等,这类数据其实很适合用NoSQL数据库存储,扩展性好,性能高。但开源Redis将全量数据加载进内存,等到后期玩家持续上量后,成本扛不住,导致骑虎难下。
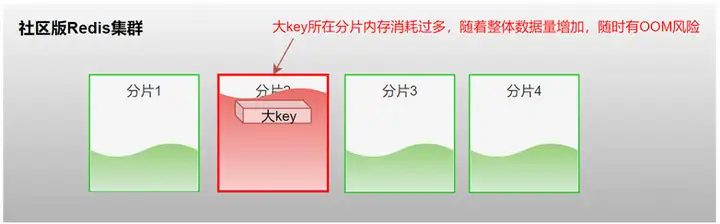
痛点2:全局大key会导致分片数据倾斜,动不动OOM
全局排行榜、发券抢券都难免会有些使用大Key的场景,这时虽然开源Redis的性能没啥问题,但由于Redis集群中每个分片能“装”的数据很少,如果个别Key太大,就很容易会导致数据倾斜,有些分片会经常发生OOM,影响业务。
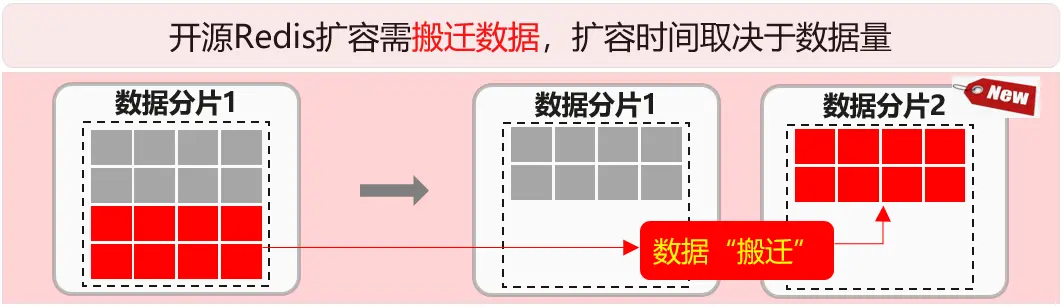
痛点3:扩容慢,对业务影响大
游戏开服、节假日活动,都需要预置充足资源。开源Redis做扩容会是个麻烦事,由于要跨分片做数据的拷贝,因此往往动辄半小时以上,而且考虑到对业务的影响,客户只能在半夜实施扩容。
其实,此类问题已经存在很多年了,业界是有一些解法的。比如用SSD替代内存的自建KV存储方案,或者AWS那种比较先进的MemoryDB数据库服务,都能或多或少解决一些开源Redis的使用痛点。
针对这类游戏场景,华为云也提供一款足够靠谱的云数据库:GaussDB(for Redis)。
GaussDB(for Redis)是华为云数据库团队在吸取了开源Redis的经验教训后,自主研发的KV数据库,兼容开源Redis协议,采用存算分离的架构,提供了很多好用的企业级特性。针对几种常见的游戏业务痛点,展开来说:
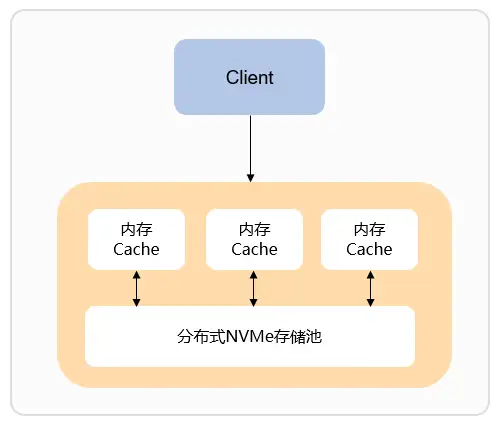
企业级特性1:采用内存+NVMe的存储方案,自动冷热交换,实现有效降本30%+
使用Redis的场景必然需要数据库能提供高性能、低时延的有力支撑。GaussDB(for Redis)除了将全量数据落盘到NVMe存储池外,还支持缓存高频访问的热数据存在内存中,内部自动完成冷热数据交换,通过LRU算法淘汰冷数据,业务能优先从内存中读取热数据,最终端到端达成业务对高并发和低时延的诉求。
同时,GaussDB(for Redis)分布式NVMe存储池具有高压缩比。根据实际业务测试,string、hash等常用数据类型在GaussDB(for Redis)实际存储空间占用仅为开源Redis的70%~85%。GaussDB(for Redis)最多可支撑36TB数据存储,数据量越多,相比开源Redis的成本越低。
企业级特性2:存储池统一管理全量Key,不会发生数据倾斜,极少OOM,更稳定
开源Redis存储大key会导致分片内存消耗不均,随着集群整体数据量水位提升,大key所在分片随时有OOM风险。在扩容和删除大key时,业务访问会被阻塞甚至数据丢失。
GaussDB(for Redis)支持大key可靠存储,且不会导致分片OOM。另外,在GaussDB(for Redis)的控制台WebClient可以轻松一键进行“大Key诊断”,随时都能掌握业务使用的大Key情况。
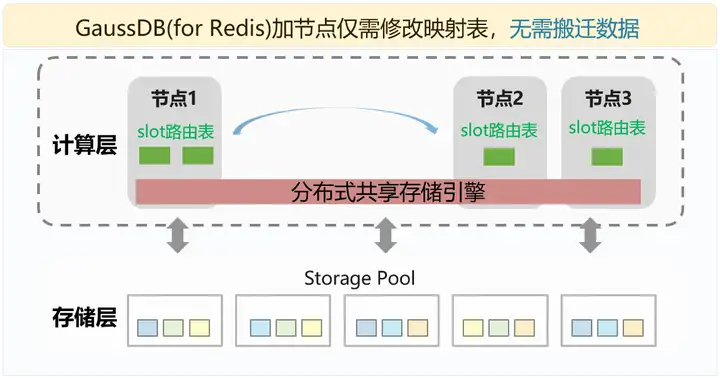
企业级特性3:真正的秒级弹性伸缩,运营节日活动更轻松
开源Redis扩缩容涉及数据的拷贝迁移,速度慢,业务中断时间长。业务在流量突增的场景,需要紧急快速扩容,否则会影响用户体验,甚至给客户带来经济损失。
GaussDB(for Redis)采用存算分离的架构,扩容不需要迁移存储池中的数据,只需将数据分片信息均衡到新增加的计算节点上即可,不涉及迁移数据,可以秒级完成,对业务影响小。
总结
其实游戏客户对数据库的诉求是很明确的,数据库应当“放心存放心用”。GaussDB(for Redis)是一款超越开源Redis的企业级KV数据库,既能满足游戏业务对高并发的性能指标要求,且能有效降本增效。后续还会给大家聊聊GaussDB(for Redis)针对其他业务场景的痛点退出的企业级特性,尽请期待。
点击关注,第一时间了解华为云新鲜技术~