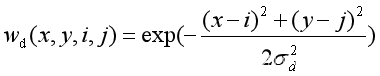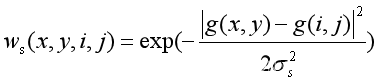摘要:本文将详细讲解两种非线性滤波方法中值滤波和双边滤波。
本文分享自华为云社区《[Python从零到壹] 五十六.图像增强及运算篇之图像平滑(中值滤波、双边滤波)》,作者: eastmount 。
一.中值滤波
前面讲述的都是线性平滑滤波,它们的中间像素值都是由邻域像素值线性加权得到的,接下来将讲解一种非线性平滑滤波——中值滤波。中值滤波通过计算每一个像素点某邻域范围内所有像素点灰度值的中值,来替换该像素点的灰度值,从而让周围的像素值更接近真实情况,消除孤立的噪声。
中值滤波对脉冲噪声有良好的滤除作用,特别是在滤除噪声的同时,能够保护图像的边缘和细节,使之不被模糊处理,这些优良特性是线性滤波方法所不具有的,从而使其常常被应用于消除图像中的椒盐噪声[1-2]。
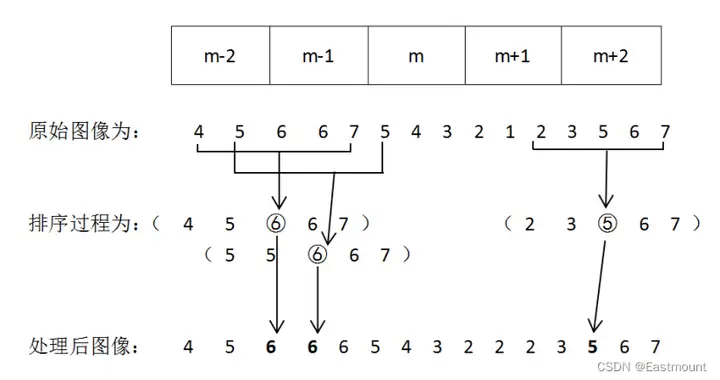
中值滤波算法的计算过程如图1所示。选择含有五个点的窗口,依次扫描该窗口中的像素,每个像素点所对应的灰度值按照升序或降序排列,然后获取最中间的值来替换该点的灰度值。
上图展示的是矩形窗口,常用的窗口还包括正方形、十字形、环形和圆形等,不同形状的窗口会带来不同的过滤效果,其中正方形和圆形窗口适合于外轮廓边缘较长的图像,十字形窗口适合于带尖角形状的图像。
OpenCV将中值滤波封装在medianBlur()函数中,其函数原型如下所示:
- dst = medianBlur(src, ksize[, dst])
– src表示待处理的输入图像
– dst表示输出图像,其大小和类型与输入图像相同
– ksize表示内核大小,其值必须是大于1的奇数,如3、5、7等
下面是调用medianBlur()函数实现中值滤波的代码。
# -*- coding: utf-8 -*-
# By:Eastmount
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图片
img = cv2.imread('lena-zs.png')
source = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#中值滤波
result = cv2.medianBlur(source, 3)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图形
titles = ['原始图像', '中值滤波']
images = [source, result]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
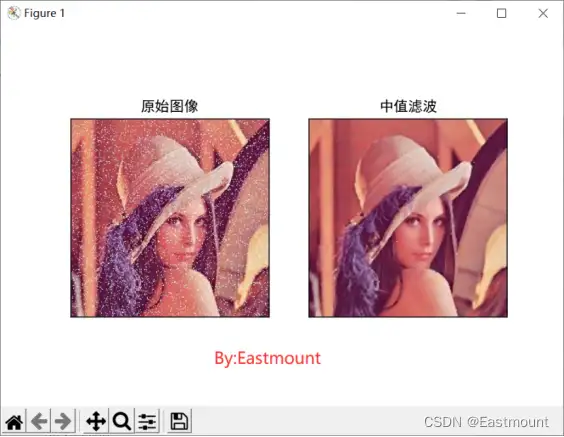
其运行结果如图2所示,它有效地过滤掉了“lena”图中的噪声,并且很好地保护了图像的边缘信息,使之不被模糊处理。
二.双边滤波
双边滤波(Bilateral filter)是由Tomasi和Manduchi在1998年发明的一种各向异性滤波,它一种非线性的图像平滑方法,结合了图像的空间邻近度和像素值相似度(即空间域和值域)的一种折中处理,从而达到保边去噪的目的。双边滤波的优势是能够做到边缘的保护,其他的均值滤波、方框滤波和高斯滤波在去除噪声的同时,都会有较明显的边缘模糊,对于图像高频细节的保护效果并不好[3]。
双边滤波比高斯滤波多了一个高斯方差sigma-d,它是基于空间分布的高斯滤波函数。所以在图像边缘附近,离的较远的像素点不会过于影响到图像边缘上的像素点,从而保证了图像边缘附近的像素值得以保存。但是双边滤波也存在一定的缺陷,由于它保存了过多的高频信息,双边滤波不能有效地过滤掉彩色图像中的高频噪声,只能够对低频信息进行较好地去噪[4]。
在双边滤波器中,输出的像素值依赖于邻域像素值的加权值组合,对输入图像进行局部加权平均得到输出图像 的像素值,其公式如下所示:
式中表示中心点(x,y)的(2N+1)×(2N+1)的领域像素,值依赖于领域像素值的加权平均。权重系数取决于空间域核(domain)和值域核(range)的乘积。空间域核的定义如公式(2)所示。
值域核的定义如公式(3)所示。
两者相乘之后,就会产生依赖于数据的双边滤波权重函数,如下所示:
从式子(4)可以看出,双边滤波器的加权系数是空间邻近度因子和像素亮度相似因子的非线性组合。前者随着像素点与中心点之间欧几里德距离的增加而减小,后者随着像素亮度之差的增大而减小[5-6]。
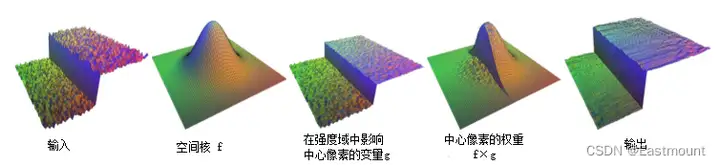
在图像变化平缓的区域,邻域内亮度值相差不大,双边滤波器转化为高斯低通滤波器;在图像变化剧烈的区域,邻域内像素亮度值相差较大,滤波器利用边缘点附近亮度值相近的像素点的亮度平均值替代原亮度值。因此,双边滤波器既平滑了图像,又保持了图像边缘,其原理图如图3所示。
OpenCV将中值滤波封装在bilateralFilter()函数中,其函数原型如下所示:
- dst = bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])
– src表示待处理的输入图像
– dst表示输出图像,其大小和类型与输入图像相同
– d表示在过滤期间使用的每个像素邻域的直径。如果这个值我们设其为非正数,则它会由sigmaSpace计算得出
– sigmaColor表示颜色空间的标准方差。该值越大,表明像素邻域内较远的颜色会混合在一起,从而产生更大面积的半相等颜色区域
– sigmaSpace表示坐标空间的标准方差。该值越大,表明像素的颜色足够接近,从而使得越远的像素会相互影响,更大的区域中相似的颜色获取相同的颜色,当d>0,d指定了邻域大小且与sigmaSpace无关。否则,d正比于sigmaSpace
– borderType表示边框模式,用于推断图像外部像素的某种边界模式,默认值为BORDER_DEFAULT,可省略
下面是调用bilateralFilter()函数实现双边滤波的代码,其中d为15,sigmaColor设置为150,sigmaSpace设置为150。
# -*- coding: utf-8 -*-
# By:Eastmount
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取图片
img = cv2.imread('lena-zs.png')
source = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#双边滤波
result = cv2.bilateralFilter(source, 15, 150, 150)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图形
titles = ['原始图像', '双边滤波']
images = [source, result]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
其运行结果如图4所示:
三.总结
本文主要讲解了常用于消除噪声的图像平滑方法,常见方法包括三种线性滤波(均值滤波、方框滤波、高斯滤波)和两种非线性滤波(中值滤波、双边滤波)。这篇文章介绍了中值滤波和双边滤波,通过原理和代码进行对比,分别讲述了各种滤波方法的优缺点,有效地消除了图像的噪声,并保留图像的边缘轮廓。
点击关注,第一时间了解华为云新鲜技术~