1.前言
1.1 社区数字场景
社区业务有非常多的数字统计场景,基础的场景主要有以下这些:
用户维度:发布内容数、被点赞数、被收藏数、关注数、粉丝数、点赞内容数、收藏内容数等。
内容维度:内容点赞数、内容阅读数、内容分享数、内容收藏数、内容评论数等。
标签维度:话题内容数、特效内容数、商品内容数、品牌内容数等。
其中部分场景还会有很多细分情况,例如内容相关的统计还会有以下场景:
这样排列组合出来的最终结果就有很多了,比如需要查询用户发布的图文内容数、用户点赞的视频内容数等等,且这些数字一般都需要能够支持高度精确性、高性能查询和批量查询等能力。
1.2 具体案例
具体案例可参考下列图示:
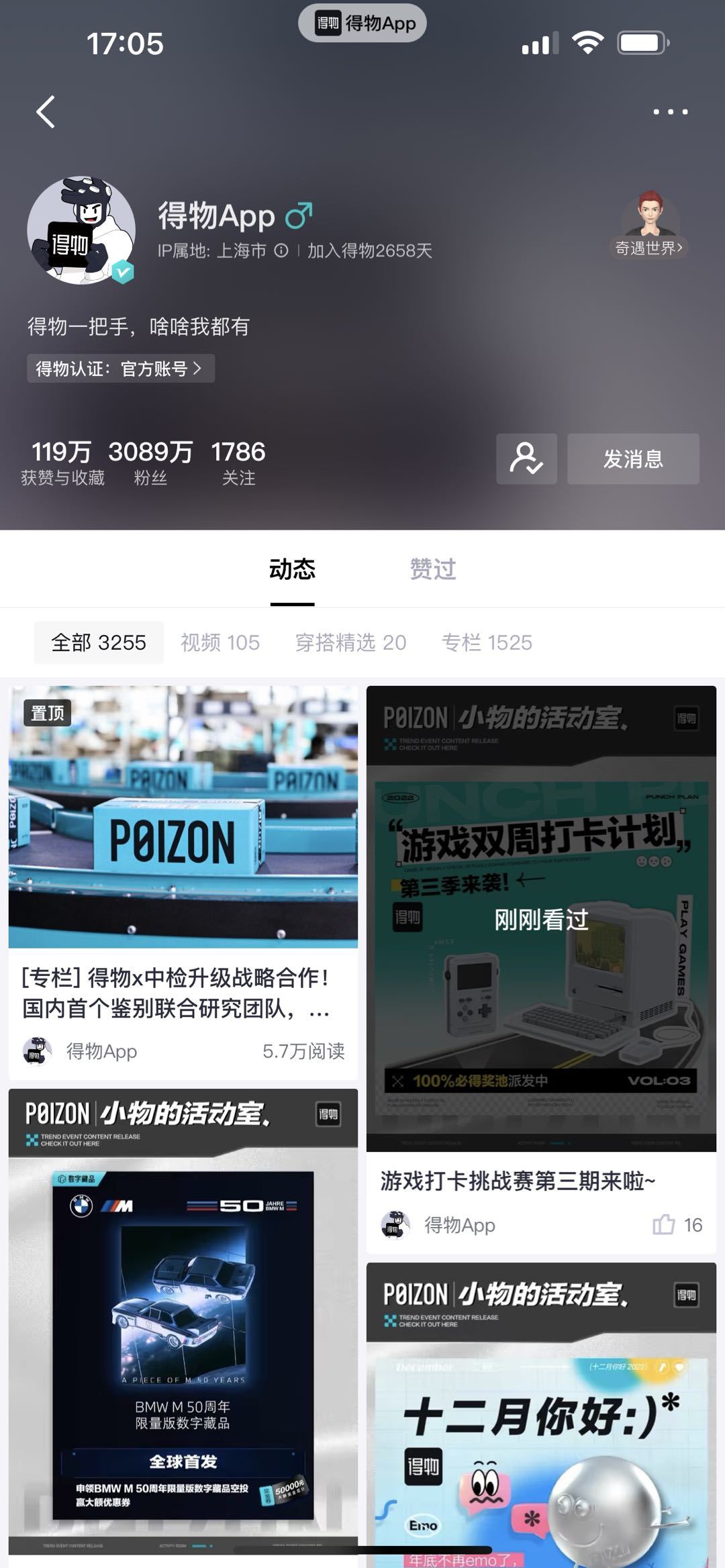
- 图1. 个人主页展示获赞与收藏总数、粉丝数、关注数、发布动态数(视频数、穿搭精选数、专栏数)。
![1.jpeg]()
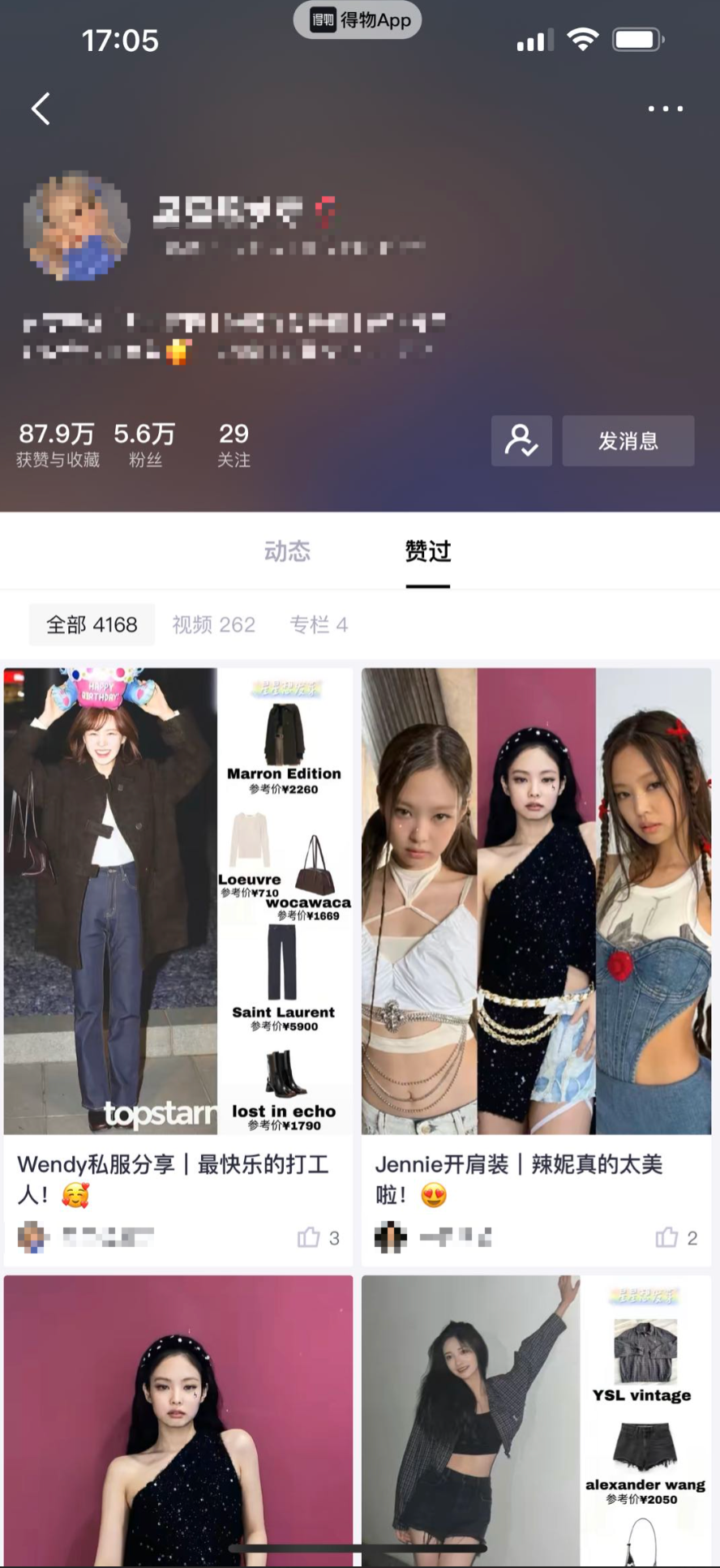
- 图2. 他人主页展示获赞与收藏总数、粉丝数、关注数、点赞动态数(视频数、专栏数)。
![2.png]()
![3.png]()
2.逐渐浮现的系统风险
2.1 历史方案
早期社区是直接采用Count数据表+缓存的方式,这种方式在体量较小和单体服务的情况下完全没问题,而且成本低、性能高、绝对精准,但随着社区的体量逐渐变大、微服务拆分越来越细之后,该方案就会越来越难以支撑业务。
2.2 系统风险
性能瓶颈和稳定性风险:
一方面业务明细表的体量越来越大,需要通过分库分表来解决问题,分库分表后再用Count聚合的方式性能就会变差。
另一方面业务统计规则越来越复杂,使用数据库Count的方式会使数据查询语句越来越复杂,容易引发慢SQL从而导致数据库不稳定。
计数业务数据层和缓存都和核心业务部分放在一起,若出现统计导致的不稳定会影响核心业务场景的使用,从而将小问题变成大问题。
缓存策略问题:
热点穿透问题:部分计数场景下是有新数据就删除缓存的策略,但若出现热点内容、热点用户时,对应的统计数据(如点赞数、粉丝数)会频繁删除缓存导致穿透的问题,且一般热点内容和用户产生的数据量比较大、查询量也比较大,会更容易加剧问题从而引发雪崩。
数据一致性问题:部分计数场景下是定时更新缓存的策略,缓存操作和MySQL操作无法在一个事务中完成,会产生不一致的问题,且在越频繁变更的场景下差异值就会越大。
3
计数系统设计与实现
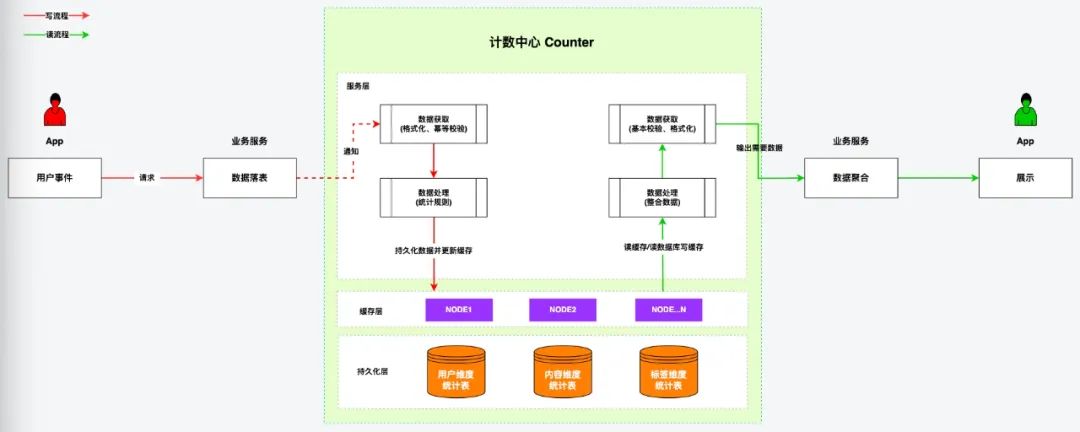
结合当前社区的业务现状、体量以及考虑中长期体量增长的规划,我们也调研了业内比较常见的一些实现方案,最终敲定通过维护一套计数中心的服务,由计数中心服务统一管理社区的数字统计的方式,整体情况大致如下:
![4.jpeg]()
3.1 写场景
该场景下计数中心内部主要干三件事,主要包括数据获取、数据处理、数据持久化。
3.1.1 数据获取
数据的获取一般有两种方式,通过接口或通过MQ的方式,既然是平台服务更希望对业务没什么侵入性,因此我们目前采用的主要是MQ的方式。
使用MQ的情况下也有两种方案可取,一种是业务服务根据事件触发MQ消息,需要业务服务先保证业务数据已经持久化且需要生产端保证消息投递无丢失,另一种则是直接通过订阅业务数据表binlog的方式,这种方式可以保证业务数据已经持久化,目前得物已有DTS(数据订阅平台),使用起来也比较方便且可保证消息投递不丢失,因此我们目前更多的是采用第二种方案。
数据获取到后我们做一些格基础校验,验证是否存在我们必要的一些字段是否完整,同时需要验证数据处理的幂等性防止数据重复消费等,通过消息ID和业务唯一ID做幂等,然后把每行业务数据的各字段格式化成变更前和变更后俩个值且可以区分出是新增还是更新(binlog消息体就是这样因此更加方便),之后就可以进入数据处理阶段。
3.1.2 数据处理
拿到通过校验和格式化后的数据,根据对应的事件和规则来判断当前变更数据具体要做什么操作,我们通过具体的案例来看会更直观,如:
场景1. 用户A关注用户B
第一步,判断出该场景下需要变更的统计数,用户A的关注数要+1,用户B的粉丝数要+1。
第二步,提取需要变更的统计数的对象值,如用户A的ID和用户B的ID。
第三步,格式化成统计的格式,对象ID+统计类型+统计数变化值。
第四步,调用数据持久化的方法。
场景2. 用户A发布的图文内容状态由正常变为删除
第一步,判断出该场景下需要变更的统计数,用户A发布的图文内容数要-1。
第二步,提取需要变更的统计数的对象值,如用户A的ID。
第三步,格式化成统计的格式,对象ID+统计类型+统计数变化值。
第四步,调用数据持久化的方法。
3.1.3 数据持久化
持久化部分主要分为两块,一是DB持久化,二是对于缓存的更新。社区的数字统计场景主要有以下两种情况:
只增不减:如内容分享事件,每次事件触发只需要给内容的分享数+1即可。
既有增又有减:如用户A(关注/取消关注)用户B事件,需要给用户A关注数(+1/-1),也需要给用户B的粉丝数(+1/-1)。
又因为我们通过MQ消费数据是无序的,极端情况下可能会出现先减再加的情况从而导致负数的出现,因此存储层的字段需要支持有符号的数据,保证最终计算的结果是正确的即可。DB层持久完成后再直接操作缓存变更数字并延长有效期,若缓存不存在则不处理等待读场景有需要时再处理。
3.2 读场景
读场景整体逻辑比较简洁,就是先查缓存,缓存不存在就查询DB再写入缓存即可,可批量跨场景查询,需要注意对负数情况的处理。
4.总结及规划
4.1 总结
计数中心是业内比较常见的做法,相对于老方案能够降低各个业务对于复杂计数场景的维护成本,提升迭代效率和系统稳定性,独立出来后在出现异常时业务也可做短时间降级,从而降低对核心业务的影响面。
4.2 规划
目前社区已有多个场景接入计数中心,结合当前的现状及未来的可能性,考虑后续主要优化方向主要有:
![11111.jpg]()
文/小夏