Curve 文件存储是一个 POSIX 兼容的分布式文件系统,适用于私有云、公有云、混合云环境。我们可以通过 Curve 文件存储轻松访问百亿级文件。
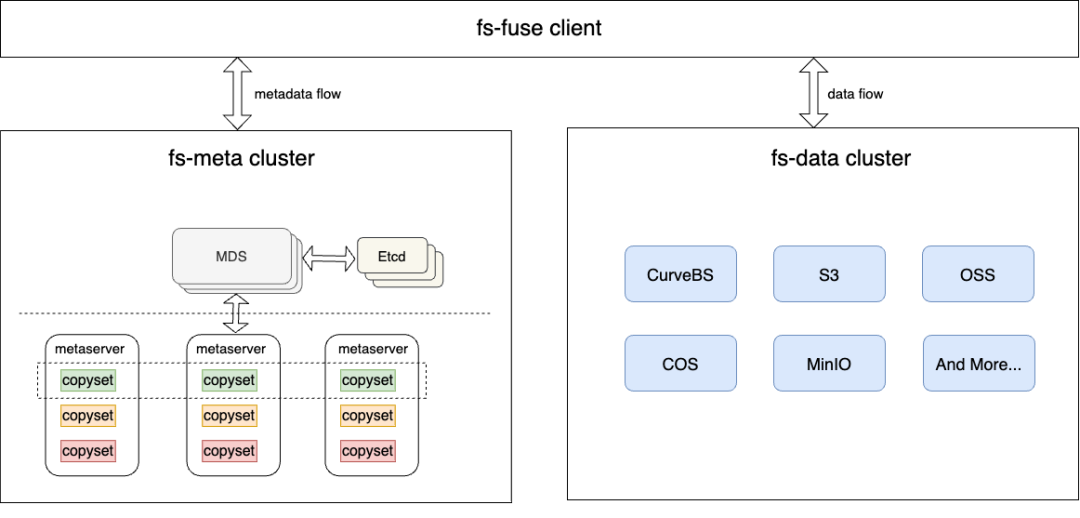
先对 Curve 文件存储的架构做一个简单的介绍。文件存储需要持久化的信息有两类,一类是文件的元数据,主要以 inode 和 dentry 为主,一类是文件的数据,即用户的写入内容。Curve 文件系统在设计之初,考虑到多云的支持,以及在大规模数据场景下的成本(冷数据居多),需要支持数据在不同性能的存储中流转,因此选择了把元数据和数据分开存储。
下图是 Curve 文件系统的架构。
![]()
如何支撑百亿级文件
Curve 文件系统的重要特点之一就是适用于海量文件存储,那么 Curve 文件系统如何保证可以支撑百亿级规模?如何保证在百亿级规模下的性能?从理论上来看:
规模方面,Curve文件存储的元数据集群,每个节点存储一定范围的 inode(比如1~10000)和 dentry,如果文件数量增多,可以进行存储节点的扩充,所以理论上规模是没有上限的。
性能方面,当文件数量很多时,对于单个文件的操作是没有什么差别的,但对于一些需要元数据的聚合操作会出现性能问题,比如 du (计算当前文件系统的容量), ls (获取目录下所有文件信息)等操作,需要做一定的优化来保障性能。
那实际上 Curve 文件系统的表现如何呢?
首先介绍一下文件系统的几款通用测试工具。
pjdfstest[1]: posix 兼容性测试。有3600+个回归测试用例,覆盖 chmod, chown, link, mkdir, mkfifo, open, rename, rmdir, symlink, truncate, unlink 等
mdtest[2]: 元数据性能测试。对文件或者目录进行 open/stat/close 等操作,并返回报告
vdbench[3]: 数据一致性测试。Vdbench 是 Oracle 编写的一款应用广泛的存储性能测试工具,既支持块设备的性能测试,也支持文件系统性能测试,在做随机写的一致性测试很方便,能实时检查出哪一个扇区出现了数据不一致
fio[4]: 数据性能测试。
Curve 文件系统从v2.3版本以后提供了单独压测元数据集群的方式(数据集群一般使用 Curve 块存储和 S3 ,所以直接对这些组件进行性能测试即可)。
通过 CurveAdm[5] 搭建文件系统,在准备客户端配置文件 client.yaml[6] 时新增配置项: s3.fakeS3=true[7]。
使用 mdtest,vdbench,ImageNet数据集[8]作为数据源,测试大小文件混合场景下文件系统的稳定性和性能。
根据元数据的数据结构估算,百亿级文件的存储元数据逻辑空间大概需要8TB,实际存储使用3副本大概在24TB左右。有兴趣测试的小伙伴可以参考一下。
海量文件存储下性能如何
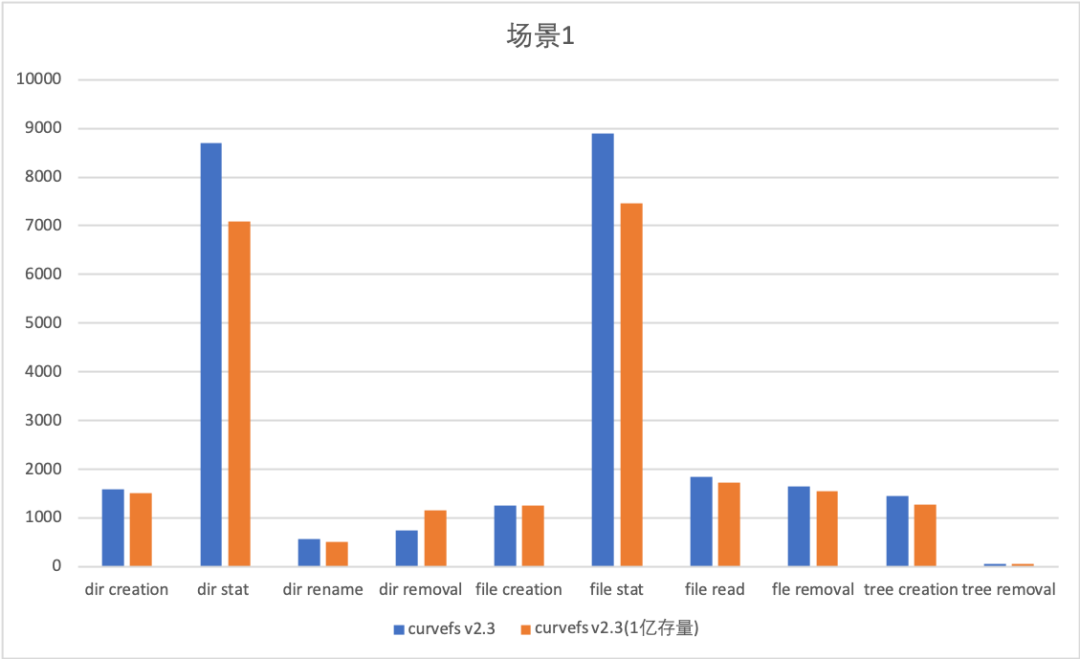
Curve 文件存储随着存量数据增长,性能可以相对保持平稳(stat 请求的下降在15%左右)。
场景1(测试目录个数较多的情况):
测试命令 mdtest -z 2 -b 3 -I 10000 -d /mountpoint
场景2(测试目录层级很深的情况):
测试命令 mdtest -z 10 -b 2 -I 100 -d /mountpoint
![]()
![]()
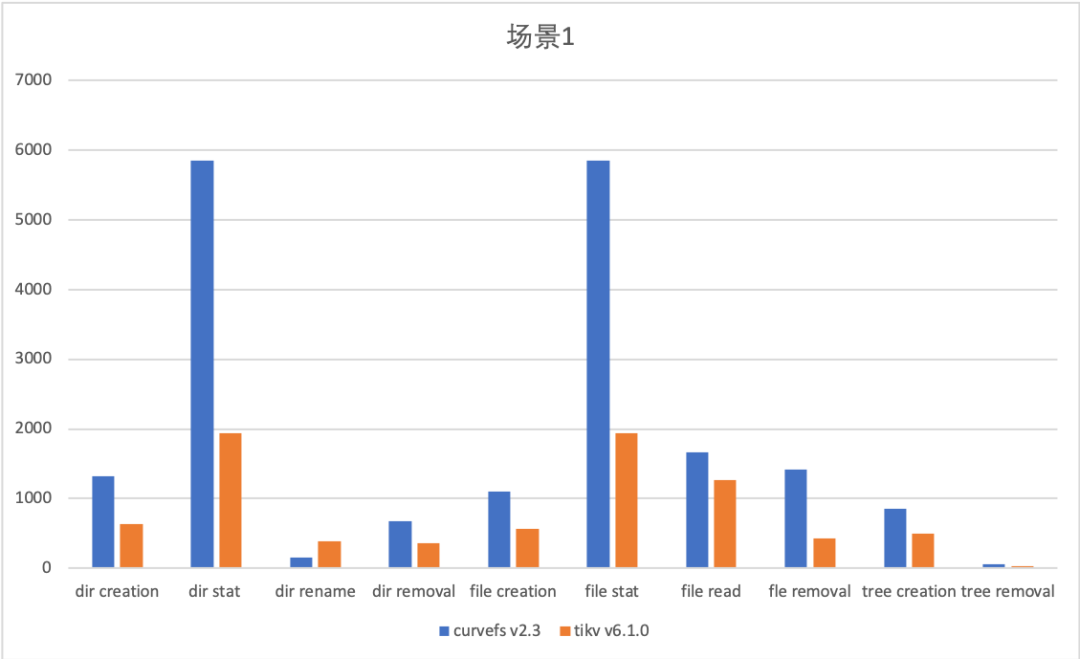
Curve文件存储当前使用元数据集群,相对于使用分布式kv存储(如TiKV)性能较优。
说明:本组测试打开了 fuseClient.enableMultiMountPointRename ,保证多挂载点rename的事务性,所以和上组的基础测试数据有偏差。
场景1(测试目录个数较多的情况):
测试命令 mdtest -z 2 -b 3 -I 10000 -d /mountpoint
场景2(测试目录层级很深的情况):
测试命令 mdtest -z 10 -b 2 -I 100 -d /mountpoint
![]()
![]()
当前,Curve文件存储已经在ES、AI场景落地,后续会有相应的案例分享给大家。
<原创作者:李小翠,Curve Maintainer>
参考链接:
pjdfstest:[1]
https://github.com/pjd/pjdfstest
mdtest:[2]
https://github.com/LLNL/mdtest
vdbench:[3]
https://www.oracle.com/downloads/server-storage/vdbench-downloads.html
fio:[4]
https://github.com/axboe/fio
CurveAdm:[5]
https://github.com/opencurve/curveadm/wiki
client.yaml:[6]
https://github.com/opencurve/curveadm/wiki/curvefs-client-deployment#%E7%AC%AC-3-%E6%AD%A5%E5%87%86%E5%A4%87%E5%AE%A2%E6%88%B7%E7%AB%AF%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6
s3.fakeS3=true:[7]
https://github.com/opencurve/curve/blob/5df72f5e1e2813e4bfa5d73672ea0f6a25630e74/curvefs/conf/client.conf#L128
ImageNet数据集:[8]
https://www.kaggle.com/competitions/imagenet-object-localization-challenge/data
Curve 是一款高性能、易运维、云原生的开源分布式存储系统。可应用于主流的云原生基础设施平台:对接 OpenStack 平台为云主机提供高性能块存储服务;对接 Kubernetes 为其提供 RWO、RWX 等类型的持久化存储卷;对接 PolarFS 作为云原生数据库的高性能存储底座,完美支持云原生数据库的存算分离架构。
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve
官网:https://opencurve.io/
用户论坛:https://ask.opencurve.io/
微信群:搜索群助手微信号 OpenCurve_bot