@[toc] 在之前的文章中,松哥也有和小伙伴们使用过流程变量,然而没有和大家系统的梳理过流程变量的具体玩法以及它对应的数据表详情,今天我们就来看看 Flowable 中流程变量的详细玩法。
1. 为什么需要流程变量
首先我们来看看为什么需要流程变量。
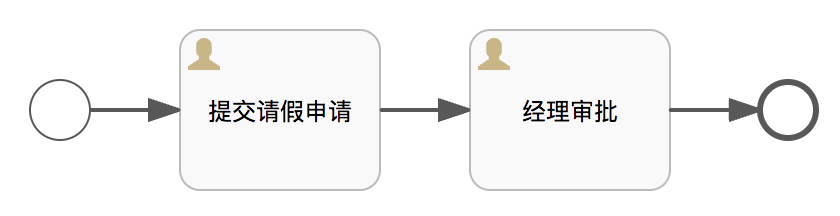
举一个简单的例子,假设我们有如下一个流程:
![]()
这是一个请假流程,那么谁请假、请几天、起始时间、请假理由等等,这些都需要说明,不然领导审批的依据是啥?那么如何传递这些数据,我们就需要流程变量。
2. 流程变量的分类
整体上来说,目前流程变量可以分为三种类型:
- 全局流程变量:在整个流程执行期间,这个流程变量都是有效的。
- 本地流程变量:这个只针对流程中某一个具体的 Task(任务)有效,这个任务执行完毕后,这个流程变量就失效了。
- 临时流程变量:顾名思义就是临时的,这个不会存入到数据库中。
在接下来的内容中,我会跟大家挨个介绍这些流程变量的用法。
3. 全局流程变量
假设我们就是上面这个请假流程,我们一起来看下流程变量的设置和获取。
3.1 启动时设置
第一种方式,就是我们可以在流程启动的时候,设置流程变量,如下:
@Test
void test01() {
Map<string, object> variables = new HashMap<>();
variables.put("days", 10);
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
ProcessInstance pi = runtimeService.startProcessInstanceByKey("demo01", variables);
logger.info("id:{},activityId:{}", pi.getId(), pi.getActivityId());
}
我们可以在启动的时候为流程设置变量,小伙伴们注意到,流程变量的 value 也可以是一个对象(不过这个对象要能够序列化,即实现了 Serializable 接口),然后在启动的时候传入这个变量即可。
我们在流程启动日志中搜索 休息一下 四个字,可以找到和流程变量相关的 SQL,一共有两条,如下:
insert into ACT_HI_VARINST (ID_, PROC_INST_ID_, EXECUTION_ID_, TASK_ID_, NAME_, REV_, VAR_TYPE_, SCOPE_ID_, SUB_SCOPE_ID_, SCOPE_TYPE_, BYTEARRAY_ID_, DOUBLE_, LONG_ , TEXT_, TEXT2_, CREATE_TIME_, LAST_UPDATED_TIME_) values ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ) , ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ) , ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? )
INSERT INTO ACT_RU_VARIABLE (ID_, REV_, TYPE_, NAME_, PROC_INST_ID_, EXECUTION_ID_, TASK_ID_, SCOPE_ID_, SUB_SCOPE_ID_, SCOPE_TYPE_, BYTEARRAY_ID_, DOUBLE_, LONG_ , TEXT_, TEXT2_) VALUES ( ?, 1, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ) , ( ?, 1, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ) , ( ?, 1, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? )
从标名称上大概就能看出来,ACT_HI_VARINST 是存储流程执行的历史信息的,ACT_RU_VARIABLE 则是保存流程运行时候的信息的。
我们打开 ACT_RU_VARIABLE 表来看一下:
![]()
从表中我们可以看到,每一个流程变量都有对应的流程实例 ID,这就说明这些流程变量是属于某一个流程实例的,所以我们可以按照如下方式来查询流程变量:
@Test
void test01() {
List<execution> list = runtimeService.createExecutionQuery().list();
for (Execution execution : list) {
Object reason = runtimeService.getVariable(execution.getId(), "reason");
logger.info("reason:{}", reason);
}
}
对应的查询 SQL 如下:
: ==> Preparing: select * from ACT_RU_VARIABLE WHERE EXECUTION_ID_ = ? AND TASK_ID_ is null AND NAME_ = ?
: ==> Parameters: 6fdd2007-4c3a-11ed-aa7e-acde48001122(String), reason(String)
: <== Total: 1
可以看到,这个就是去 ACT_RU_VARIABLE 表中进行查询,查询条件中包含了变量的名称。
当然,我们也可以直接查询某一个流程的所有变量,如下:
@Test
void test02() {
List<execution> list = runtimeService.createExecutionQuery().list();
for (Execution execution : list) {
Map<string,object> variables = runtimeService.getVariables(execution.getId());
logger.info("variables:{}", variables);
}
}
这个对应的查询 SQL 如下:
: ==> Preparing: select * from ACT_RU_VARIABLE WHERE EXECUTION_ID_ = ? AND TASK_ID_ is null
: ==> Parameters: 6fdd2007-4c3a-11ed-aa7e-acde48001122(String)
: <== Total: 3
可以看到,这个跟上面的那个差不多,只不过少了 NAME_ 这个条件。
3.2 通过 Task 设置
我们也可以在流程启动成功之后,再去设置流程变量,步骤如下:
首先启动一个流程:
@Test
void test01() {
ProcessInstance pi = runtimeService.startProcessInstanceByKey("demo01");
logger.info("id:{},activityId:{}", pi.getId(), pi.getActivityId());
}
然后设置流程变量:
@Test
void test03() {
Task task = taskService.createTaskQuery().singleResult();
taskService.setVariable(task.getId(), "days", 10);
Map<string, object> variables = new HashMap<>();
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
taskService.setVariables(task.getId(),variables);
}
查询到某一个 Task,然后设置流程变量,上面这段代码和小伙伴们演示了两种设置方式:
上面这个设置流程变量的方式,本质上还是往 ACT_HI_VARINST 和 ACT_RU_VARIABLE 表中插入数据。具体的 SQL 也和前面的一样,我就不贴出来了。
3.3 完成任务时设置
也可以在完成一个任务的时候设置流程变量,如下:
@Test
void test04() {
Task task = taskService.createTaskQuery().singleResult();
Map<string, object> variables = new HashMap<>();
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
variables.put("days", 10);
taskService.complete(task.getId(),variables);
}
底层涉及到的 SQL 都跟前面一样,我就不赘述了。
3.4 通过流程设置
由于是全局流程变量,所以我们也可以通过 RuntimeService 来进行设置,如下:
@Test
void test05() {
Execution execution = runtimeService.createExecutionQuery().singleResult();
runtimeService.setVariable(execution.getId(), "days", 10);
Map<string, object> variables = new HashMap<>();
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
runtimeService.setVariables(execution.getId(), variables);
}
好啦,一共就是这四种方式。
4. 本地流程变量
第三小节我们说的全局流程变量是和某一个具体的流程绑定的,而本地流程变量则不同,本地流程变量和某一个 Task 绑定。
4.1 通过 Task 设置
假设我们启动流程之后,通过 Task 来设置一个本地流程变量,方式如下:
@Test
void test03() {
Task task = taskService.createTaskQuery().singleResult();
taskService.setVariableLocal(task.getId(), "days", 10);
Map<string, object> variables = new HashMap<>();
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
taskService.setVariables(task.getId(),variables);
}
上面这段代码中,我设置了一个本地变量,两个全局变量,设置完成后,我们去 ACT_RU_VARIABLE 表中来查看一下具体的效果。
![]()
大家看到,由于 days 是本地变量,所以它的 TASK_ID_ 有值,这个好理解,说明 days 这个变量和这个具体的 Task 是有关的。
此时如果我们完成这个 Task,代码如下:
@Test
void test06() {
Task task = taskService.createTaskQuery().singleResult();
taskService.complete(task.getId());
}
完成之后,再来查看 ACT_RU_VARIABLE 表,如下:
![]()
我们发现本地变量 days 已经没有了。因为上一个 Task 都已经执行完毕了,这个时候如果还是按照第三小节介绍的方式去查询变量,就查不到 days 了。此时如果需要查询到曾经的 days 变量,得去历史表中查询了,方式如下:
@Test
void test07() {
ProcessInstance pi = runtimeService.createProcessInstanceQuery().singleResult();
List<historicvariableinstance> list = historyService.createHistoricVariableInstanceQuery().processInstanceId(pi.getId()).list();
for (HistoricVariableInstance hvi : list) {
logger.info("name:{},type:{},value:{}", hvi.getVariableName(), hvi.getVariableTypeName(), hvi.getValue());
}
}
这是流程本地变量的特点,当然相关的方法还有好几个,这里列出来给小伙伴们参考:
- org.flowable.engine.TaskService#complete(java.lang.String, java.util.Map<java.lang.string,java.lang.object>, boolean):在完成一个 Task 的时候,如果传递了变量,则可以通过第三个参数来控制这个变量是全局的还是本地的,true 表示这个变量是本地的。
- org.flowable.engine.RuntimeService#setVariableLocal:为某一个执行实例设置本地变量。
- org.flowable.engine.RuntimeService#setVariablesLocal:同上,批量设置。
好啦,这就是本地流程变量。
5. 临时流程变量
临时流程变量是不存数据库的,一般来说我们可以在启动流程或者完成任务的时候使用,用法如下:
@Test
void test21() {
Map<string, object> variables = new HashMap<>();
variables.put("reason", "休息一下");
variables.put("startTime", new Date());
ProcessInstance pi = runtimeService
.createProcessInstanceBuilder()
.transientVariable("days", 10)
.transientVariables(variables)
.processDefinitionKey("demo01")
.start();
logger.info("id:{},activityId:{}", pi.getId(), pi.getActivityId());
}
上面这段代码涉及到的流程变量就是临时流程变量,它是不会存入到数据库中的。
也可以在完成一个任务的时候设置临时变量,如下:
@Test
void test22() {
Task task = taskService.createTaskQuery().singleResult();
Map<string, object> transientVariables = new HashMap<>();
transientVariables.put("days", 10);
taskService.complete(task.getId(), null, transientVariables);
}
这个临时变量也是不会存入到数据库中的。
好啦,关于流程变量,今天就和小伙伴们先说这么多~</string,></string,></java.lang.string,java.lang.object></historicvariableinstance></string,></string,></string,></string,></string,object></execution></execution></string,>