ice文档站:http://124.221.148.247/zh
1 Demo仓库地址:
github:https://github.com/zjn-zjn/flink-ice
gitee:https://gitee.com/waitmoon/flink-ice
2 Demo功能描述
通过netcat制造输入流(nc -l 9000 windows:nc -l -p 9000)
flink接收本地9000端口输入流,以回车(\n)分割单词
输入流经过IceProcessor处理后打印结果流
3 项目搭建
使用flink-quickstart-java快速搭建flink项目
3.1 添加ice依赖
因flink为非Spring项目,需依赖ice-core并手动初始化,Spring项目直接依赖ice-client-spring-boot-starter即可
<dependency>
<groupId>com.waitmoon.ice</groupId>
<artifactId>ice-core</artifactId>
<version>${ice.version}</version>
</dependency>
3.2 编写StreamingJob
public class StreamingJob {
public static void main(String[] args) throws Exception {
// 创建 Flink 执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//接收本地socket9000端口输入流,以回车分割单词
//通过netcat制造输入流 nc -l 9000 (windows nc -l -p 9000)
DataStreamSource<String> stream = env.socketTextStream("localhost", 9000, "\n");
//按照单词长度keyBy,使用IceProcessor并打印结果
stream.keyBy(String::length).process(new IceProcessor()).print().setParallelism(1);
//执行程序
env.execute("Flink Streaming Java API Skeleton");
}
}
3.3 编写ice算子IceProcessor
在static代码块中初始化ice客户端,此处直接使用的自己部署的ice-server地址对应的app:2
算子功能: 将流内数据放入roam,组装pack并执行ice规则处理(直接根据iceId触发,iceId在server配置后台获取)
/**
* ice算子
*/
public class IceProcessor extends KeyedProcessFunction<Integer, String, String> {
//ice 客户端
private static IceNioClient iceNioClient;
static {
//初始化ice客户端
try {
//配置远程server地址,app,以及节点扫描路径
//此处使用了自己搭建的server,后台地址 http://eg.waitmoon.com/config/list/2
iceNioClient = new IceNioClient(2, "waitmoon.com:18121", "com.waitmoon.flink.ice.node");
//启动ice客户端
iceNioClient.start();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public void processElement(String value, Context ctx, Collector<String> out) {
//组装IcePack
IcePack pack = new IcePack();
//设置要触发的iceId(配置后台中需要触发的ID)
//http://eg.waitmoon.com/config/detail/2/1081
pack.setIceId(1081);
//初始化roam,将单词和长度放入roam中
IceRoam roam = new IceRoam();
roam.put("input", value);
roam.put("length", ctx.getCurrentKey());
pack.setRoam(roam);
//同步执行
Ice.syncProcess(pack);
//执行完成后,获取roam中的result
String result = roam.getMulti("result");
if (result != null) {
//result不为空,将结果放入下游算子
out.collect(result);
}
}
@Override
public void close() {
if (iceNioClient != null) {
//清理ice 客户端
iceNioClient.destroy();
iceNioClient = null;
}
}
}
3.4 编写节点ContainsFlow
节点功能: 判断根据key去roam里拿的值是否在set中,是则返回true,否则返回false
/**
* @author waitmoon
* 过滤性质节点
* 判断值在不在集合中
*/
@Data
@Slf4j
@EqualsAndHashCode(callSuper = true)
public class ContainsFlow extends BaseLeafRoamFlow {
//默认input
private String key = "input";
private Set<String> set;
@Override
protected boolean doRoamFlow(IceRoam roam) {
//判断roam中的key对应的值是否在集合中
return set.contains(roam.<String>getMulti(key));
}
@Override
public void afterPropertiesSet() {
log.info("ContainsFlow init with key:{}, set:{} nodeId:{}", key, set, this.getIceNodeId());
}
public NodeRunStateEnum errorHandle(IceContext ctx, Throwable t) {
log.error("error occur id:{} e:", this.findIceNodeId(), t);
return super.errorHandle(ctx, t);
}
}
3.5 编写节点PutNone
节点功能: 将value值放入roam的key中,不干扰流程(不返回true/false)
/**
* @author waitmoon
* 不干扰流程性质节点
* 将一个值放入roam
*/
@Data
@EqualsAndHashCode(callSuper = true)
public class PutNone extends BaseLeafRoamNone {
//默认result
private String key = "result";
private Object value;
@Override
protected void doRoamNone(IceRoam roam) {
//将value放到roam中
roam.putMulti(key, value);
}
}
4 项目启动
4.1 netcat 制造输入流
mac/linux 使用 nc -l 9000命令,windows使用 nc -l -p 9000 命令 制造一个Socket输入流
![在这里插入图片描述]()
4.2 运行StreamingJob
运行时可以看到ice客户端启动相关信息
![在这里插入图片描述]()
5 编排ice规则
在ice-server后台编辑ice规则,用的是自己部署的ice-server,地址:http://124.221.148.247:8121
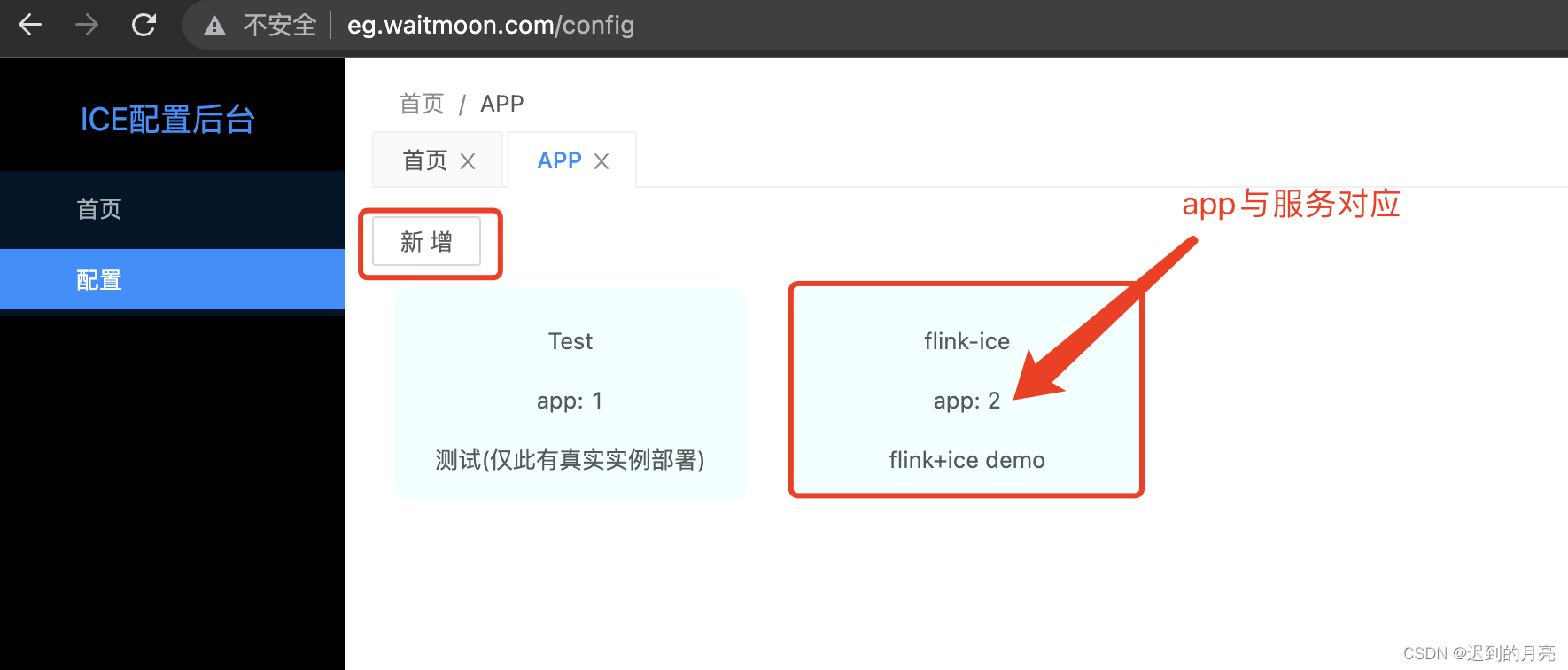
5.1 新增app
![在这里插入图片描述]()
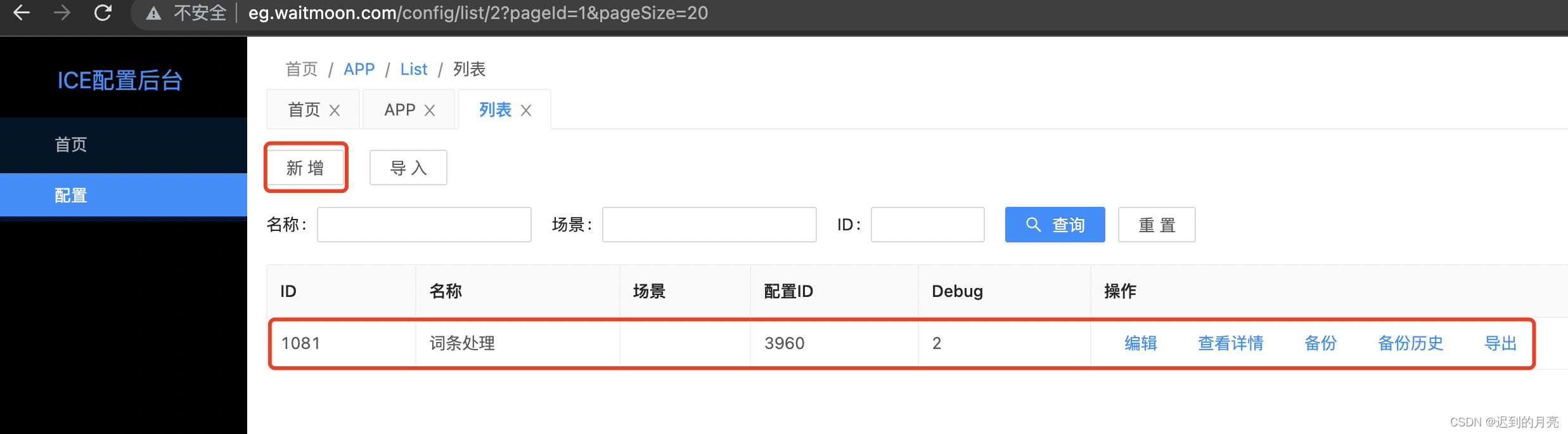
5.2 新增ice
此处Debug填2表示只打印节点执行过程,pack中的iceId即为此处的ID,点击查看详情即可编排规则
![在这里插入图片描述]()
5.3编排ice规则
![在这里插入图片描述]()
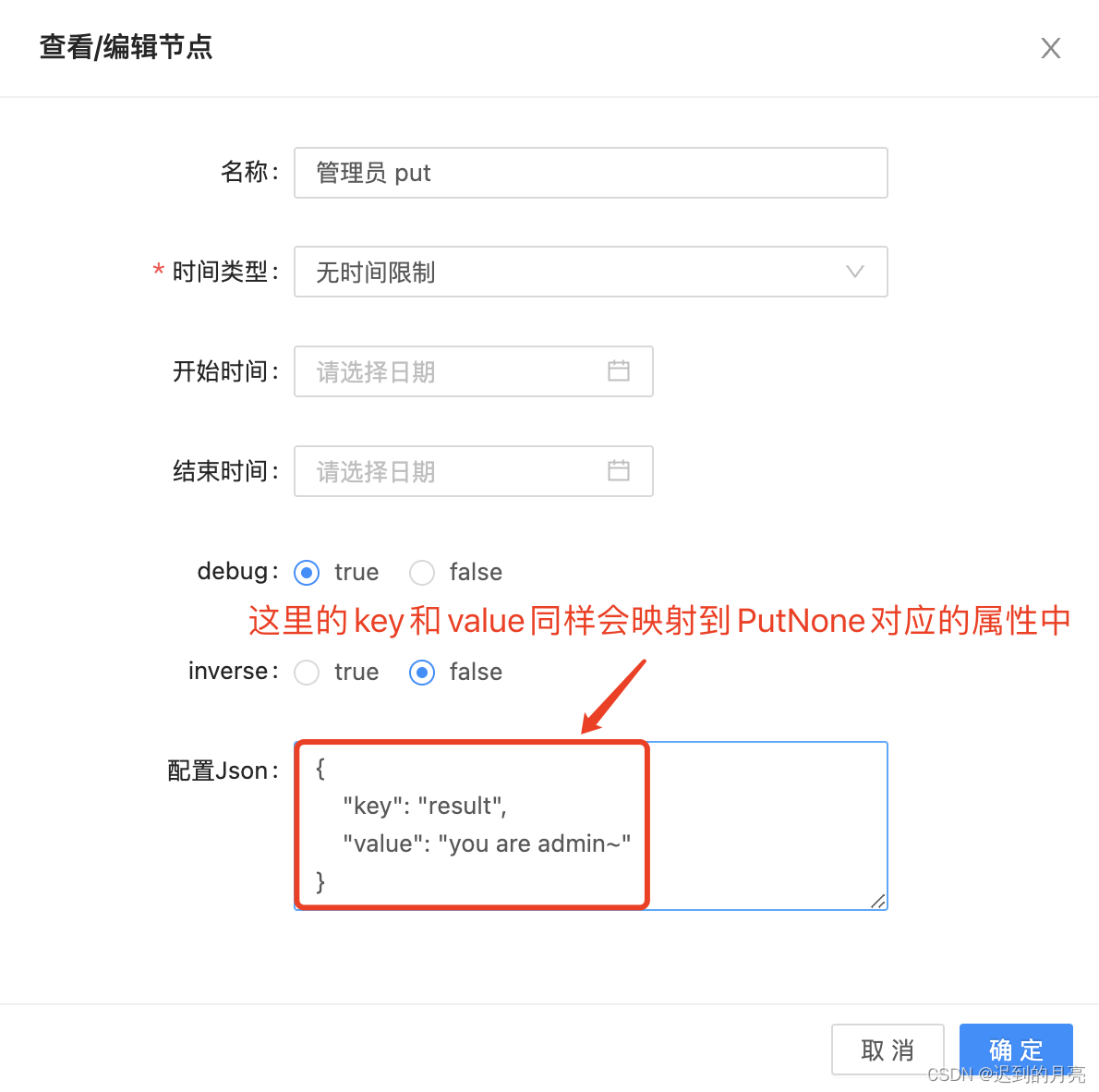
此编排实现逻辑:根据不同的输入单词,输出对应的结果到roam的result字段中供后续使用
如输入waitmoon,在管理员列表中,则输出"you are admin~"到roam的result字段,并最终由flink打印
![在这里插入图片描述]()
![在这里插入图片描述]()
6 发布与执行
在编排完规则后切记要发布后才会将变更推送到客户端并生效!!!
在终端输入单词并回车
![在这里插入图片描述]()
在flink项目日志里可以看到:
![在这里插入图片描述]()
ice打印了执行过程,[节点ID:节点类名简称:节点执行结果:节点执行耗时]
flink因为最后的sink是print(),所以打印了对应的输出。
这时候你就可以随意的更改与编排规则去实现自己的业务啦~~~