原文由 Yury Selivanov(@1st1)和 Elvis Pranskevichus(@elprans)发布于 2022 年 7 月 28 日。
在 Hacker News 上查看 EdgeDB 2.0 的英文讨论,以及在 YouTube 上观看上线直播的回放。也可以在 Gitee Issues 上参与中文讨论,发布会视频也发在了 B 站(生肉),中英文双语字幕正在努力制作中(1.0 还没做完)。
在 1.0 🏁发布半年后的今天,EdgeDB 2.0 正式发布。
自从农历正月初十发布了 1.0,我们更新了三个 1.x 小版本,在 Discord 开了频道(已经有 750 位成员加入了!),又攒了几千 GitHub 的星星,并有大几千活跃用户,对此我们十分开心——而精彩还在后面。
EdgeDB 2.0 带来了许多新功能,包括:
- 内置数据库管理面板;
- 新的 EdgeQL
GROUP 语句;
- 对象级别的访问控制;
- 区间数据类型;
- (久违的)官方 Rust 客户端;
- ……还有很多。
开始之前
开始介绍 2.0 之前,照例先安利一波。
EdgeDB 是一种我们叫做图-关系模型的数据库,通过扩展关系模型而解决了对象与关系的“阻抗失配”问题——能用面向对象的方式,更为直观地完成数据的建模和查询,同时保留了经典关系数据库的可靠性和高性能。
在 EdgeDB 出现之前,使用传统关系数据库搭建应用程序往往需要用到各种关系对象映射(ORM)和额外的中间件,它们曾经是数据建模、迁移和查询所必不可少的事实标准。而如今,EdgeDB 釜底抽薪地填补上了对象与关系之间的嫌隙,彻底从技术栈中消灭了这些不必要的抽象层,其强大的查询功能是 ORM 无法比拟的,而直接用 SQL 实现相同功能又十分不切实际。与此同时,EdgeDB 还带来了超乎寻常的运行时性能提升。
EdgeDB 的功能相当丰富,篇幅所限,这里简单介绍几个关键特性:
声明式建模
用写定义的方式建模所有的数据设计,包括计算属性、继承关系、函数定义、复杂约束和索引,以及访问规则。
type User {
required property email -> str {
constraint exclusive;
}
}
type BlogPost {
required property title -> str;
required property published -> bool {
default := false
};
link author -> User;
index on (.title);
}
内置 migration 系统
包含数据库原生的 migration 生成器、自动 migration 历史追踪,以及一套命令行开发工作流。
$ edgedb migration create
Created dbschema/migrations/00001.edgeql
$ edgedb migrate
Applied dbschema/migrations/00001.edgeql
一款简约的现代化查询语言
EdgeQL 不仅拥有 SQL 引以为豪的强大表达力,而且增添了语句嵌套拼装的超能力,摒弃了 SQL 的啰嗦……和 JOIN 语句!
select BlogPost {
title,
trimmed_title := str_trim(.title),
author: {
email
}
}
filter not .published
TypeScript 查询构造器
用 TypeScript 的代码来编写任意 EdgeQL 查询,并且带有自动的类型侦测。
e.select(e.BlogPost, post => ({
title: true,
trimmed_title: e.str_trim(post.title),
author: {
email: true
},
filter: e.op("not", post.published)
}))
以上这些好东西竟然全部都是开源的,而在底层,Postgres 默默地驱动着 EdgeDB。
《【译】EdgeDB 1.0》里介绍了更多创造 EdgeDB 的初衷,在此就不多赘述了,下面直切今天的主题—— 2.0。
2.0 的新功能
EdgeDB 2.0 改进了数据库的方方面面——类型系统、查询语言、客户端库、二进制协议,以及使用 EdgeDB 的开发体验。具体改动清单可参考 v2.0 更新日志,包括了新功能、问题修复清单,以及一份将已有项目迁移到 EdgeDB 2.0 的指南。
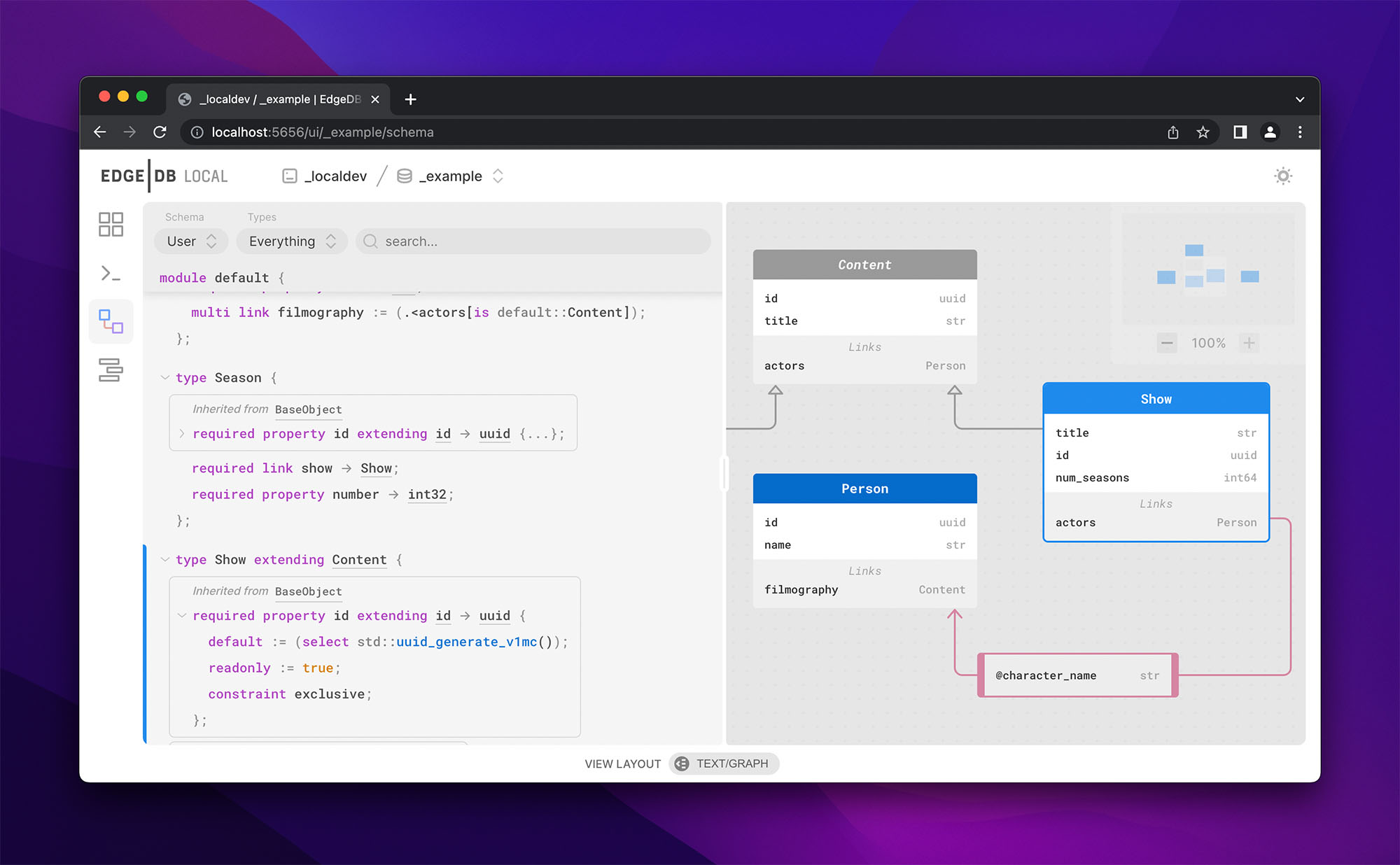
EdgeDB 管理面板(UI)
![]()
EdgeDB UI 是一个精美的数据库可视化管理工具,EdgeDB 2.0 及更高版本都内置了此功能,在工程目录中执行 edgedb ui 命令即可在默认浏览器中打开 UI 管理界面(一个 localhost 的 URL),其功能包括:
- 数据浏览编辑器;
- 即时查询命令行;
- schema 检视器,有文本和图形两种模式,如上图所示。
您还可以用 EdgeDB UI 创建一个带有示例数据的库,以便快速尝试各种复杂查询,或者一睹数据结构的真容。
而这当然只是一个开端,我们会在将来的版本中不断给 UI 加入更多新功能,比如可视化的查询计划、内置文档和管理工具。
GROUP 语句
EdgeDB 2.0 新增了一个根语句 GROUP,用来对数据进行分组和聚合。与常规的 SELECT 查询类似,GROUP 查询语句输出的也是一个对象的集合,而每个对象则代表数据的一个分组,每个分组都有三个属性:grouping、key 和 elements。比如说:
db> group Movie by .release_year;
{
{
key: {release_year: 2016},
grouping: {'release_year'},
elements: {
default::Movie {title: 'Captain America: Civil War'},
default::Movie {title: 'Doctor Strange'},
},
},
{
key: {release_year: 2017},
grouping: {'release_year'},
elements: {
default::Movie {title: 'Guardians of the Galaxy Vol. 2'},
default::Movie {title: 'Spider-Man: Homecoming'},
default::Movie {title: 'Thor: Ragnarok'},
},
},
...
}
另外,GROUP 的分组依据也可以是任意 EdgeQL 表达式、嵌套结构下的属性以及 elements 上的链接,因此能够支持复杂的数据分析查询语句(CUBE 和 ROLLUP 默默路过……)。当然,GROUP 的真正实力还是在于能与其它的 EdgeQL 语句强强联手:
db> with
... groups := (
... group Movie
... using
... starts_with_vowel := re_test('(?i)^[aeiou]', .title),
... by starts_with_vowel
... )
... select groups {
... starts_with_vowel := .key.starts_with_vowel,
... count := count(.elements),
... mean_title_length := math::mean(len(.elements.title))
... };
{
{starts_with_vowel: false, count: 12, mean_title_length: 19.75},
{starts_with_vowel: true, count: 3, mean_title_length: 19.66},
}
在 SQL 中,GROUP BY 本是 SELECT 的一个子语句,却大幅影响了 SELECT 原本的功能用意,还带来了一连串的限制(比如说,非分组依据的字段必须用聚合函数才能查询)。与之相比,EdgeQL 的各种语句都可以不费吹灰之力地拼装在一起,真的不用吹(😘),就是比 SQL 好。
对象访问控制与全局变量
此前,EdgeDB 的建模系统已经可以支持完备的基础数据类型、声明式的对象定义、类型混编特性(mixin)、动态计算属性和链接、复杂约束和索引、用户函数,等等,足以应对各种复杂的应用场景。
而在 EdgeDB 2.0 中,我们又更上一层楼,引入了对象访问控制——在建模时就可以定义应用场景中的访问控制逻辑,EdgeDB 本身则可以作为中心化的单一可信节点,为整个应用程序透明地提供仅被规则允许的数据。
具体来说,EdgeDB 2.0 允许在对象类型定义中,添加不同访问策略,去限制哪些对象可以查询到、哪些可以更新、哪些可以删除,或者允许创建什么样的对象。举个例子,下面是两个没有访问策略的对象类型:
type 用户 {
required property 邮箱 -> str {
constraint exclusive;
};
}
type 文章 {
required property 标题 -> str;
link 作者 -> 用户;
}
接下来,我们想增加一条访问策略,限制只有作者本人可以修改其文章的标题。可是,怎么告诉数据库当前执行查询的用户是哪一个呢?
+ global 当前用户 -> uuid;
type 用户 {
required property 邮箱 -> str {
constraint exclusive;
};
}
type 文章 {
required property 标题 -> str;
link 作者 -> 用户;
}
这里我们先增加了一个叫做当前用户的全局变量,这是 2.0 新加的机制,用来定义查询执行的上下文(译注:等效于所有查询语句都共享的一个查询参数)。一旦定义好了全局变量,在代码中(或是在命令行中查询)传值就很直观了:
TypeScript:
import createClient from 'edgedb';
const client = createClient();
const myApiHandler = async (userId: string) => {
const scopedClient = client.withGlobals({
当前用户: userId,
});
return await scopedClient.query(
`select global 当前用户;`
);
}
Python:
import edgedb
client = edgedb.create_client()
async def my_api_handler(user_id):
scoped_client = client.with_globals({
'当前用户': user_id,
})
return await scoped_client.query(
"select global 当前用户;"
)
命令行查询:
db> set global 当前用户 :=
... (SELECT 用户 FILTER .邮箱 = 'elvis@edgedb.com').id;
OK: SET GLOBAL
db> select global 当前用户;
{<uuid>"5b4d1530-0e0b-11ed-ae2a-133197f4faf5"}
贴士:EdgeDB 的客户端库能很高效地处理全局变量的打包传输,同时还能最大化共享同一个连接池,隐藏了底层通讯协议上巧妙却不易懂的用法。
划重点了:与查询参数不同的是,全局变量可以在任意 EdgeQL 上下文中使用,尤其是在 schema 定义中。比如说,我们就可以使用当前用户来新增一条文章的访问策略:
global 当前用户 -> uuid;
type 用户 {
required property 邮箱 -> str {
constraint exclusive;
};
}
type 文章 {
required property 标题 -> str;
link 作者 -> 用户;
+ access policy 只能操作自己的文章
+ allow all
+ using (.作者.id ?= global 当前用户)
}
新加的访问策略叫做只能操作自己的文章,仅当文章的 .作者.id 等于全局变量当前用户的值时,该策略才允许(allow)文章的全部(all)操作,包括任何增删改查。
我们特别高兴能设计出如此灵活的访问控制功能:
- 不同的策略可以分别允许(
allow)和拒绝(deny)特定的操作,包括 select、insert、delete 和 update,其中 update 又可细分为更新前检查(update read)和更新后检查(update write);
using 子句中可以放置任意的 EdgeQL 表达式;- 访问策略的数量没有上限(译注:除非因为策略太多,执行速度慢到不能忍了)。
这是一种通用的新机制,可以用来实现各种不同的访问逻辑,比如下面的例子就是一个新的类型混编特性,仅允许其对象在特定时间段内才能访问:
abstract type 混编有效期 {
required property 有效期 -> range<datetime>;
access policy 隐藏过期对象 allow all using (
contains(.有效期, datetime_of_transaction())
)
}
访问策略的文档中还有更多细节和示例,欢迎参阅。
还有好多好东西!
Rust。官方 Rust 客户端库 终于来了!🎉 尽管我们自己在深度使用 Rust(比如官方命令行就是纯 Rust 写的),但这个客户端库还是花了我们不少时间来打磨接口设计。现在,官方客户端库的数量上升到 4 个了,除了 Rust 之外,还有 TypeScript、Python 和 Go,另外还有社区维护的 .NET 和 Elixir 的客户端库。
通讯协议。EdgeDB 的二进制通讯协议版本升级到 1.0 了,带来了多处改进:
- 彻底无状态化:多个并发会话可以共享同一个无状态连接,我们甚至还可以在 HTTP 协议之上穿插 EdgeDB 二进制协议——这种穿插功能已经用在新的 UI 里了,即时查询就是 HTTP 之上的二进制 EdgeDB 1.0 协议。此外在将来,这种穿插用法还可以用在诸如 Next.js Live 等环境的集成中。
- 支持全局变量和本地状态。连接建立时,客户端将收到一份完整的状态描述,以便后续对全局变量和会话设置的值进行序列化。
- 优化分析/执行流程。客户端可以用更少的网络反复完成查询执行,降低了查询延迟。
本地开发更节省资源。EdgeDB 2.0 现已支持通过 socket 唤醒本地数据库实例,意味着暂时不用的实例不会占用任何 CPU 和内存资源,只有尝试连接某个实例,该实例才会开始运行(译注:并且 10 分钟不用就自动关闭了)。另外,运行中的实例也会自动伸缩其进程池,始终保持最小的资源占用。因此,用 EdgeDB 2.0 开发可以肆无忌惮地创建很多工程和对应的数据库实例,你用哪个工程,对应的实例就自动启动,不会再长期占用资源了。译注:此模式在开发环境中是默认的,并且仅推荐开发环境这样做!
区间类型。EdgeDB 2.0 开始支持区间类型,可以用来表示一个取值的区间,比如日期区间,时间区间,或者 64 位整数区间等等。区间实现了一系列运算符和内置函数,并且支持转成 JSON 再转回来。
日期与时间。经过调整,EdgeDB 2.0 的本地日期与时间的算术运算变的更合乎常理,并且新增了一个 cal::date_duration 类型,以及相关操作函数。
以上只是一部分,全部内容请见 v2 的更新日志!
下一步
我们希望保持一个紧凑的发布周期,因为实在有太多功能可以做了!我们计划在 6 个月后发布 EdgeDB 3.0,眼下优先级比较高的任务有:
- 用来分析 EdgeQL 查询的
EXPLAIN 命令;
- 错误(异常)类型进入标准库,用户亦可自定义;
- EdgeQL 查询构型中支持查询“所有字段”;
- RBAC 基于角色的访问控制;
- 全文检索支持。
最后必须提到的是,EdgeDB Cloud 的首个预览版即将问世,届时将可以用一条简单的命令,启动一个全托管的 EdgeDB 云实例,可直接放心用于生产环境。点击这里填写表单后,我们会在 EdgeDB Cloud 上线后的第一时间邀请您参与体验🌤。
欢迎关注我们的官方网站、OSCHINA 项目主页、知乎专栏和掘金专栏,了解更多资讯。
我们在 Gitee 开设了中文沟通交流讨论区,欢迎前来开新帖(Issue)问问题,或分享你使用 EdgeDB 的经历!❤️