导读:如果说互联网的上半场是粗狂运营,那么在下半场,精细化运营将是长久的主题,有数据分析能力才能让用户得到更好的体验。当下比较典型的分析方式是构建用户标签系统,本文将由网易严选分享 DMP 标签系统的建设以及 Apache Doris 在其中的应用实践。
作者|刘晓东 网易严选资深开发工程师
如果说互联网的上半场是粗狂运营,因为有流量红利不需要考虑细节。那么在下半场,精细化运营将是长久的主题,有数据分析能力才能让用户得到更好的体验。当下比较典型的分析方式是构建用户标签系统,从而精准地生成用户画像,提升用户体验。今天分享的主题是网易严选 DMP 标签系统建设实践,主要围绕下面五点展开:
平台总览
标签生产 :标签圈选&生产链路
标签存储:存储方式&存储架构演进
高性能查询
未来规划
平台总览
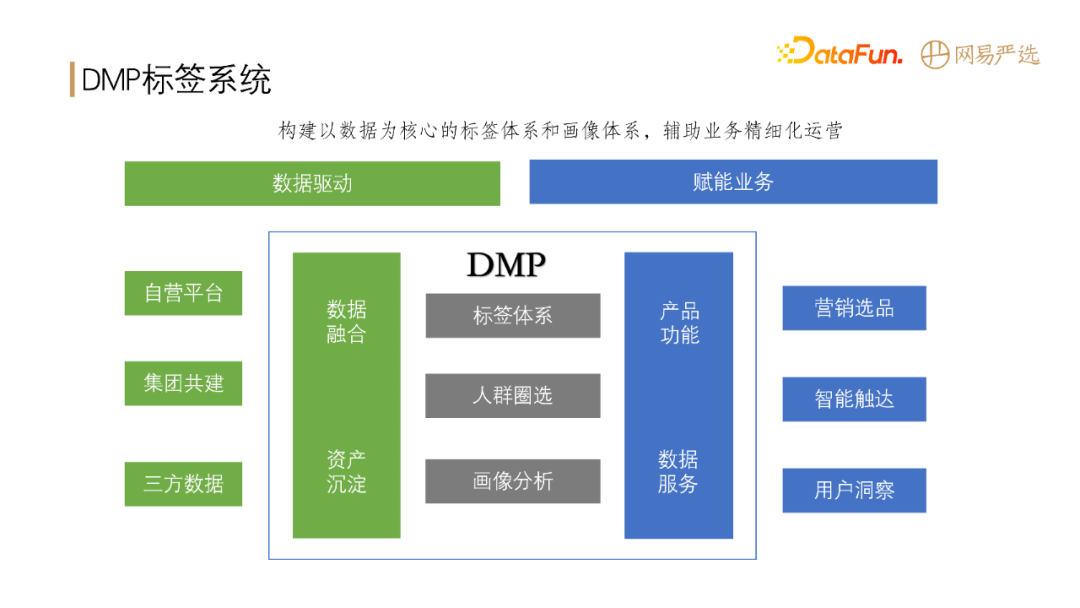
DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务,承担着非常重要的基石角色。
DMP 的数据来源主要包括三大部分:
通过收集、清洗,将以上数据形成数据资产沉淀下来。DMP 在数据资产基础上形成了一套自己的标签产出、人群圈选和用户画像分析体系,从而为业务提供支撑,包括:智能化的选品、精准触达以及用户洞察等。总的来说,DMP 系统就是构建以数据为核心的标签体系和画像体系,从而辅助业务做一系列精细化的运营。
![]()
了解 DMP 系统,先从以下几个概念开始。
标签:对于实体(用户、设备、手机号等)特征的描述,是一种面向业务的数据组织形式,比如使用:年龄段、地址、偏好类目等对用户实体进行刻画。
人群圈选:通过条件组合从全体用户中圈选出一部分用户,具体就是指定一组用户标签和其对应的标签值,得到符合条件的用户人群。
画像分析:对于人群圈选结果,查看该人群的行为情况、标签分布。例如查看【城市为杭州,且性别为女性】的用户在严选 APP 上的行为路径、消费模型等。
![]()
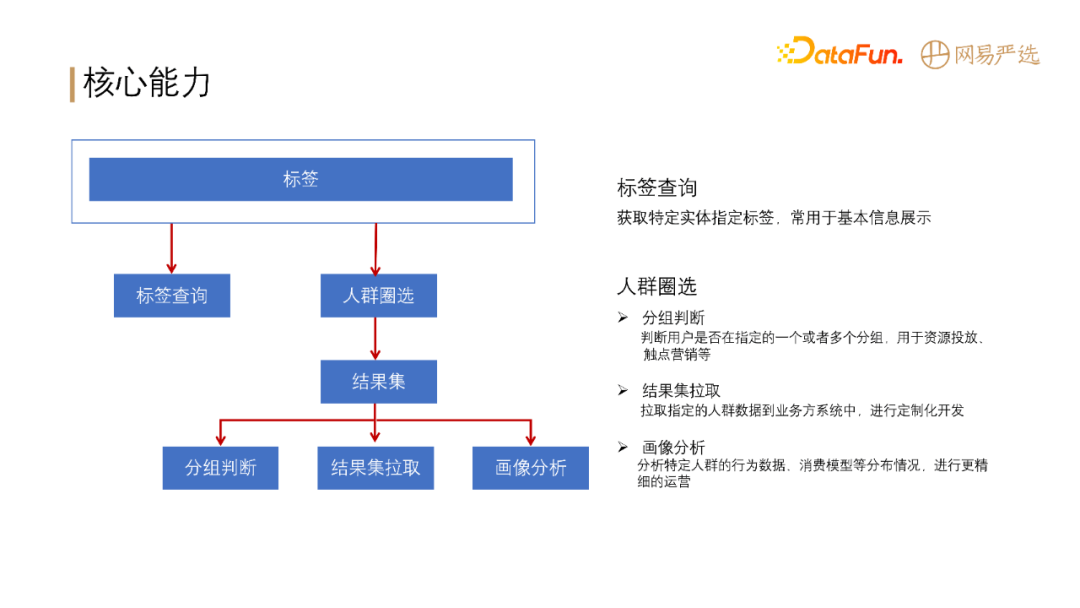
严选标签系统对外主要提供两大核心能力:
标签查询:查询特定实体指定标签的能力,常用于基本信息的展示。
人群圈选:分为实时和离线圈选。圈选结果主要用于:
分组判断:判读用户是否在指定的一个或多个分组,资源投放、触点营销等场景使用较多。
结果集拉取:拉取指定的人群数据到业务方系统中,进行定制化开发。
画像分析:分析特定人群的行为数据,消费模型等,进行更精细的运营。
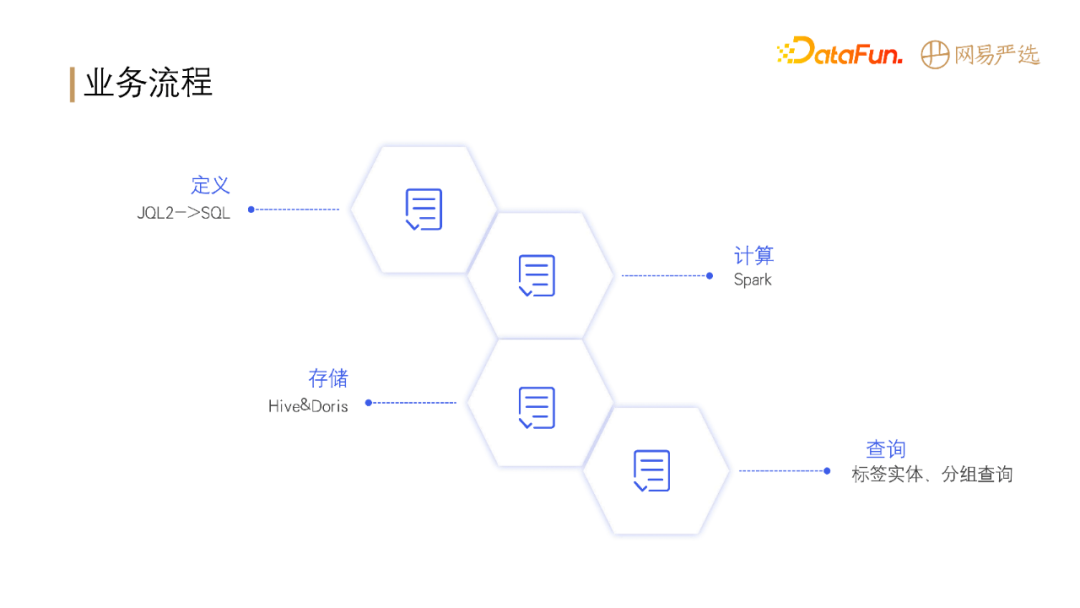
整体的业务流程如下:
![]()
首先定义标签和人群圈选的规则;
定义出描述业务的 DSL 之后,便可以将任务提交到 Spark 进行计算;
计算完成之后,将计算结果存储到 Hive 和 Doris;
之后业务方便可以根据实际业务需求从 Hive 或 Doris 中查询使用数据。
![]()
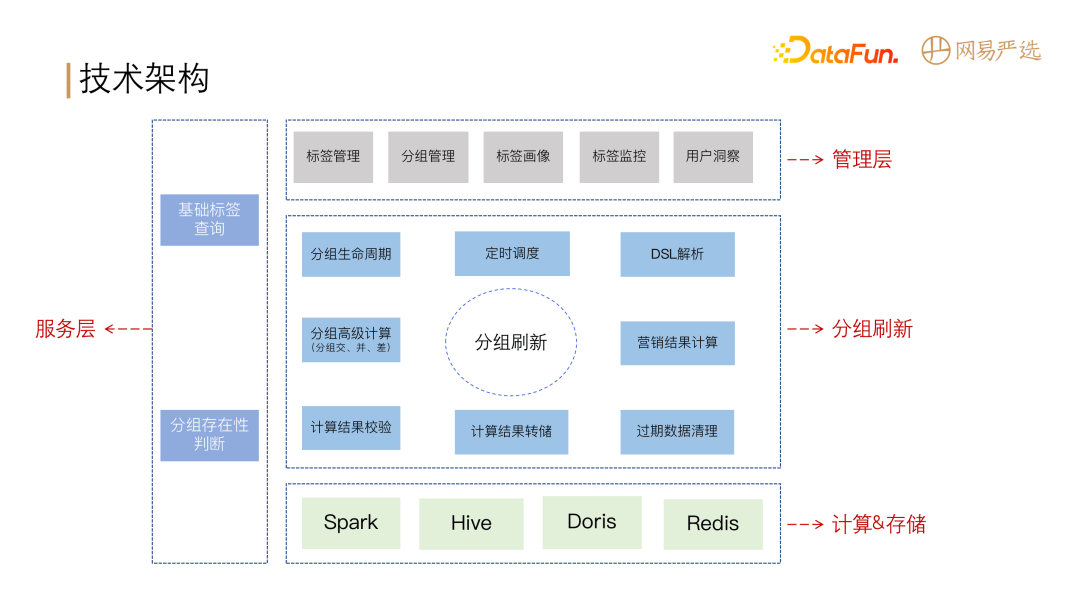
DMP 平台整体分为计算存储层、调度层、服务层、和元数据管理四大模块。
所有的标签元信息存储在源数据表中;调度层对业务的整个流程进行任务调度:数据处理、聚合转化为基础标签,基础标签和源表中的数据通过 DSL 规则转化为可用于数据查询的 SQL 语义,由调度层将任务调度到计算存储层的 Spark 进行计算,将计算结果存储到 Hive 和 Doris 中。服务层由标签服务、实体分组服务、基础标签数据服务、画像分析服务四部分组成。
![]()
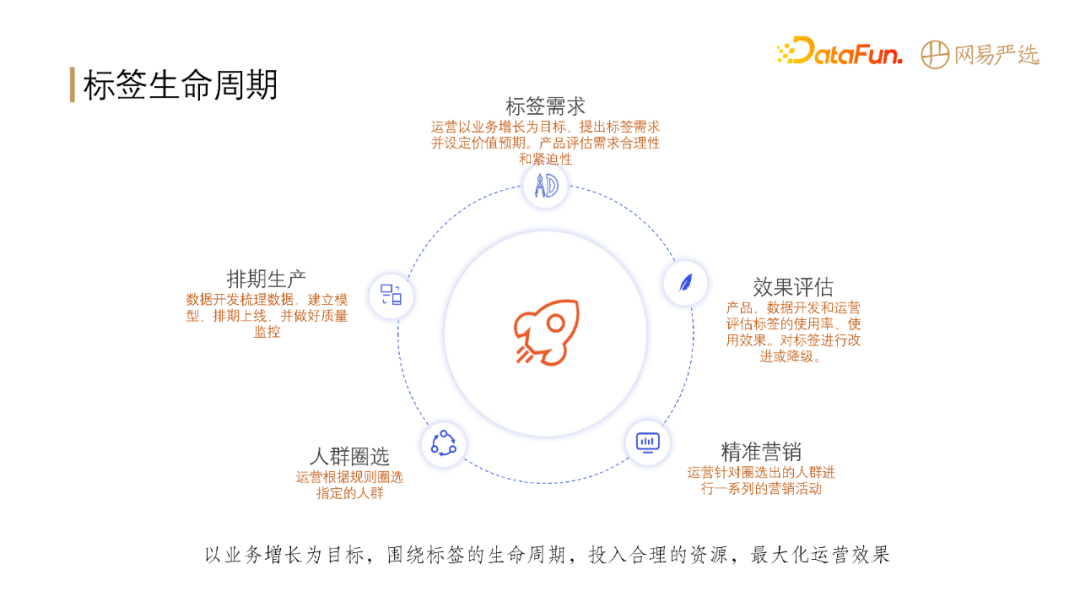
标签的生命周期包含5个阶段:
标签需求:在此阶段,运营提出标签的需求和价值预期,产品评估需求合理性以及紧迫性。
排期生产:此阶段需要数据开发梳理数据,从 ods 到 dwd 到 dm 层整个链路,根据数据建立模型,同时数据开发需要做好质量监控。
人群圈选:标签生产出来之后进行应用,圈选出标签对应的人群。
精准营销:对圈选出来的人群进行精准化营销。
效果评估:最后产品、数据开发和运营对标签使用率、使用效果进行效果评估来决定后续对标签进行改进或降级。
总的来说,就是以业务增长为目标,围绕标签的生命周期,投入合理的资源,最大化运营效果。
标签生产
接下来介绍标签生产的整个过程。
![]()
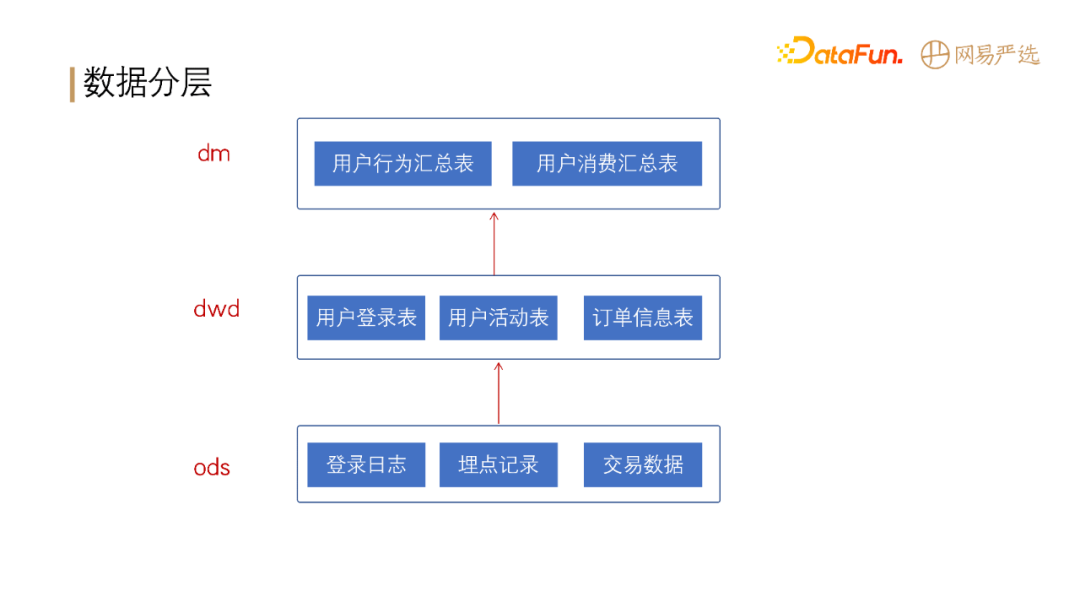
标签的数据分层:
最下层是 ods 层,包括用户登录日志、埋点记录日志、交易数据以及各种数据库的 Binlog 数据。
对 ods 层处理后的数据到达 dwd 明细层,包括用户登录表、用户活动表、订单信息表等。
dwd 层数据聚合后到 dm 层,标签全部基于 dm 层数据实现。
目前我们从原始数据库到 ods 层数据产出已经完全自动化,从 ods 层到 dwd 层实现了部分自动化,从 dwd 到 dm 层有一部分自动化操作,但自动化程度还不高,这部分的自动化操作是我们接下来的工作重点。
![]()
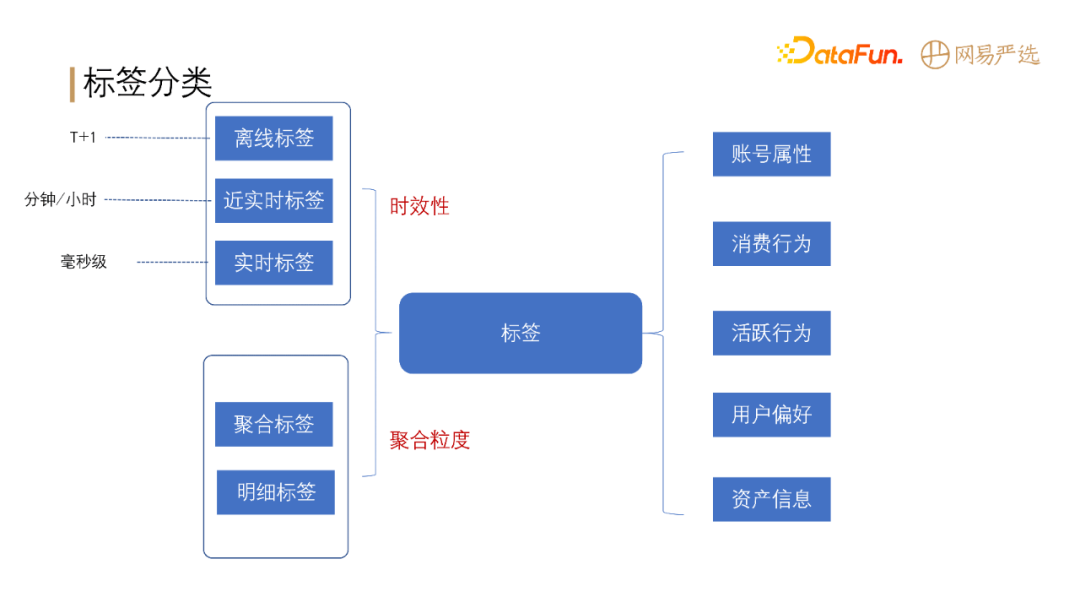
标签根据时效性分为:离线标签、近实时标签和实时标签。
根据聚合粒度分为:聚合标签和明细标签。
通过类别维度可将标签分为:账号属性标签、消费行为标签、活跃行为标签、用户偏好标签、资产信息标签等。
![]()
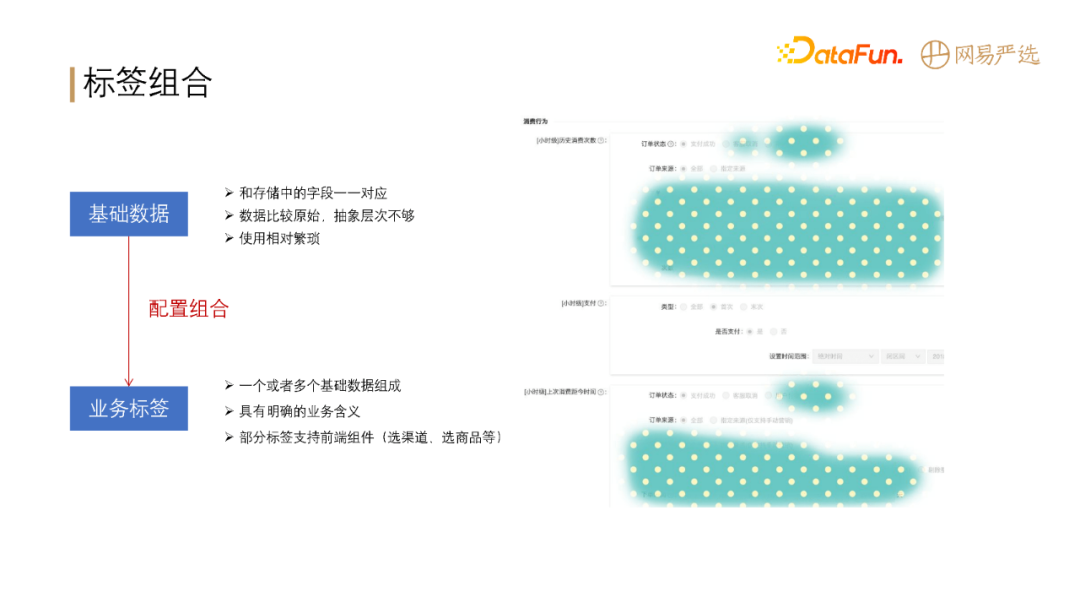
直接将 dm 层的数据不太方便拿来用,原因在于:
基础数据比较原始,抽象层次有所欠缺、使用相对繁琐。通过对基础数据进行与、或、非的组合,形成业务标签供业务方使用,可以降低运营的理解成本,降低使用难度。
![]()
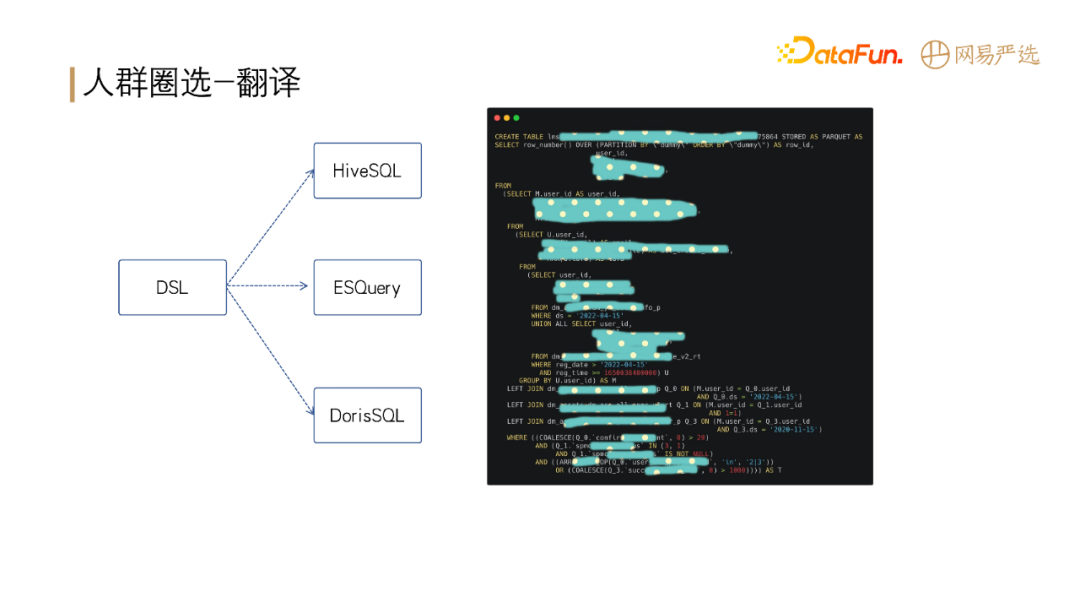
标签组合之后需要对标签进行具体业务场景应用,如人群圈选。配置如上图左侧所示,支持离线人群包和实时行为(需要分开配置)。
配置完后,生成上图右侧所示的 DSL 规则,以 Json 格式表达,对前端比较友好,也可以转成存储引擎的查询语句。
![]()
![]()
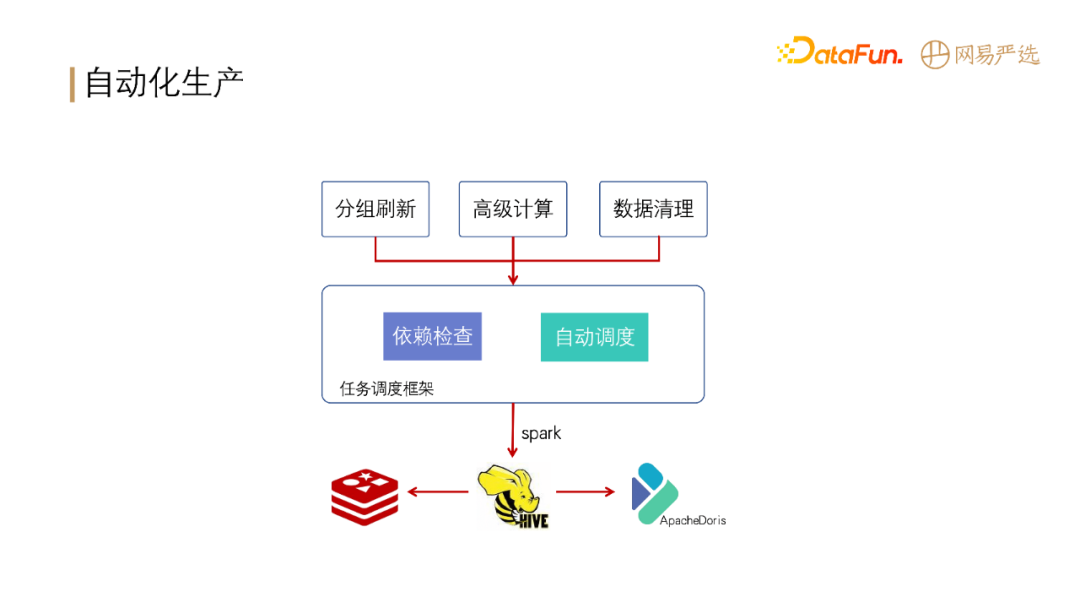
标签有一部分实现了自动化。在人群圈选部分自动化程度比较高。比如分组刷新,每天定时刷新;高级计算,如分组与分组间的交/并/差集;数据清理,及时清理过期失效的实体集。
标签存储
下面介绍一下我们在标签存储方面的实践。
严选 DMP 标签系统需要承载比较大的 C端流量,对实时性要求也比较高。
我们对存储的要求包括:
支持高性能查询,以应对大规模 C端流量
支持 SQL,便于应对数据分析场景
支持数据更新机制
可存储大数据量
支持扩展函数,以便处理自定义数据结构
和大数据生态结合紧密
目前还没有一款存储能够完全满足要求。
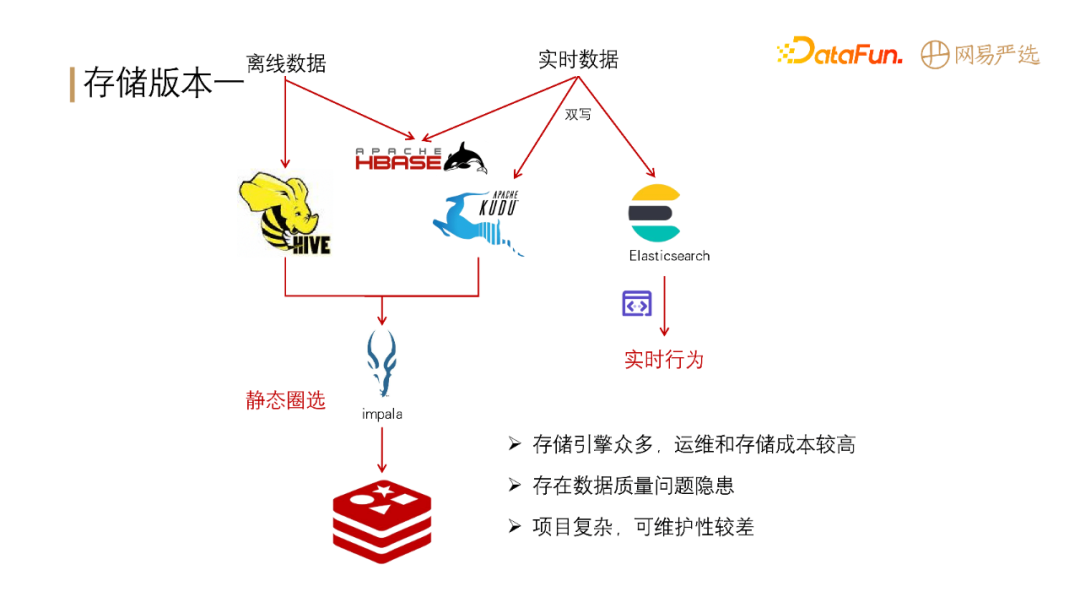
我们第一版的存储架构如下图所示:
![]()
离线数据大部分存储在 Hive 中,小部分存储在 Hbase(主要用于基础标签的查询)。实时数据一部分存储在 Hbase 中用于基础标签的查询,部分双写到 KUDU 和 ES 中,用于实时分组圈选和数据查询。离线圈选的数据通过 impala 计算出来缓存在 Redis 中。
这一版本的缺点包括:
为了减少引擎和存储的使用量,提高项目可维护性,在版本一的基础上改进实现了版本二。
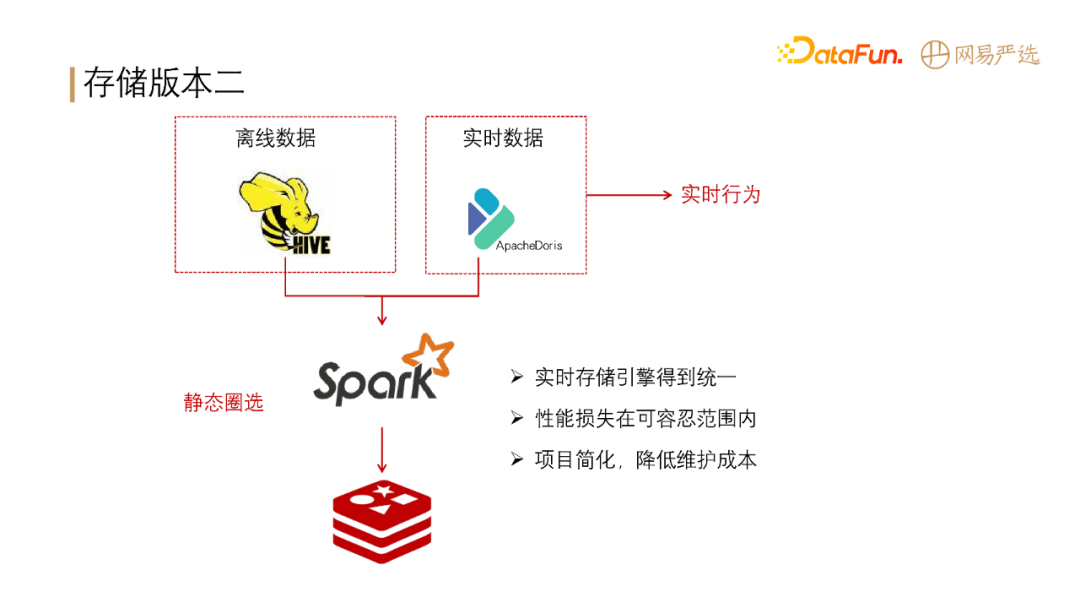
我们第二版的存储架构如下图所示:
![]()
存储架构版本二引入了 Apache Doris,离线数据主要存储在 Hive 中,同时将基础标签导入到 Doris,实时数据也存储在 Doris,基于 Spark 做 Hive 加 Doris 的联合查询,并将计算出来的结果存储在 Redis 中。经过此版改进后,实时离线引擎存储得到了统一,性能损失在可容忍范围内(Hbase 的查询性能比 Doris 好一些,能控制在 10ms 以内,Doris 目前是 1.0 版本,p99,查询性能能控制在 20ms 以内,p999,能控制在 50ms 以内);项目简化,降低了运维成本。
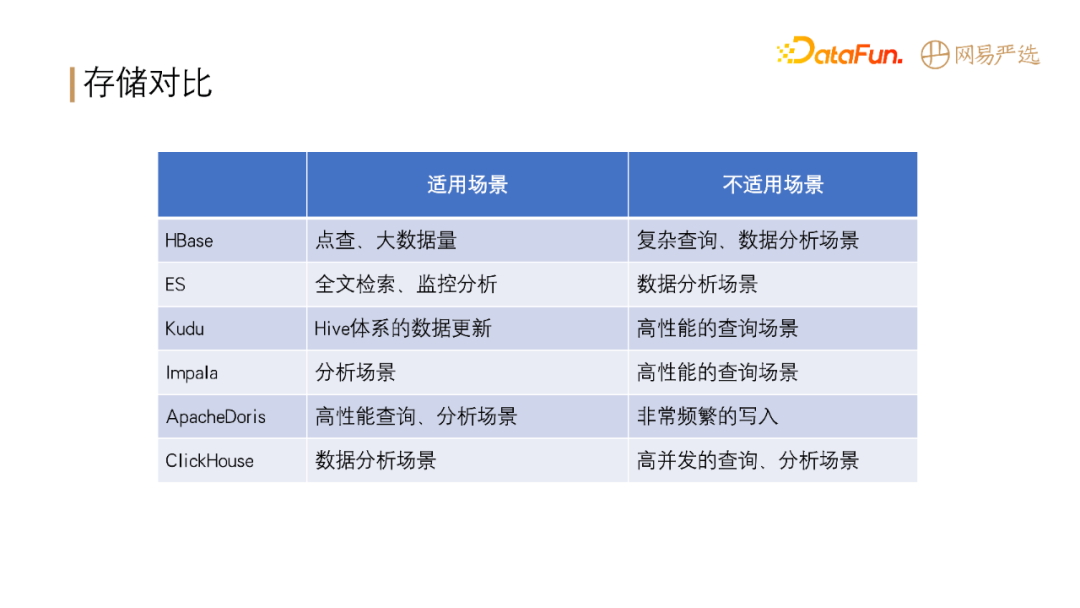
在大数据领域,各种存储计算引擎有各自的适用场景,如下表所示:
![]()
高性能查询
![]()
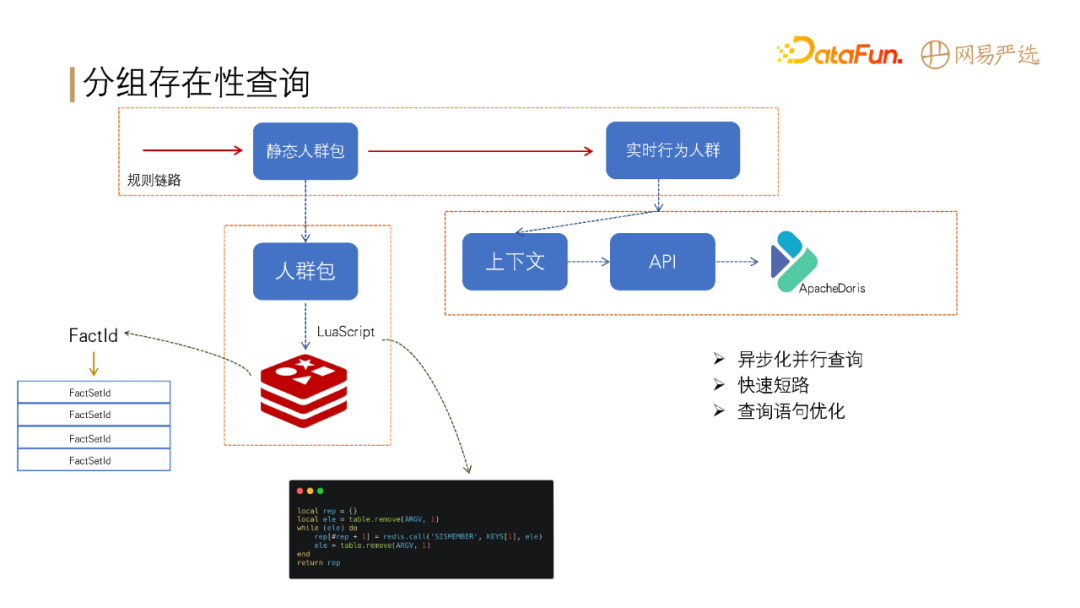
分组存在性判断:判断用户是否在指定的一个分组或者多个分组。包括两大部分:
![]()
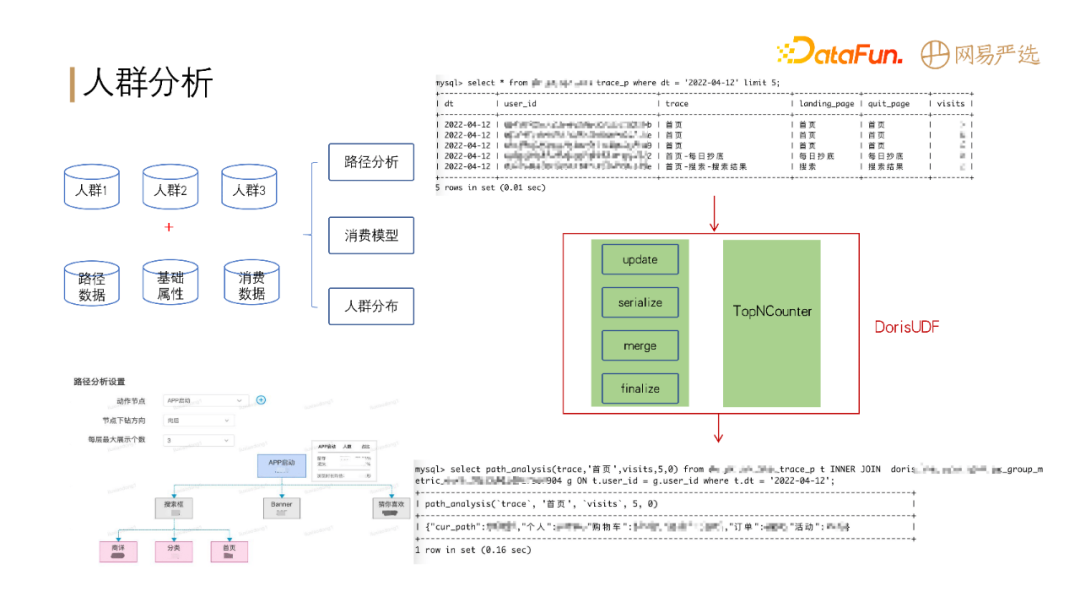
还有一个场景是人群分析:人群分析需要将人群包数据同多个表进行联合查询,分析行为路径。目前 Doris 还不支持路径分析函数,因此我们开发了 DorisUDF 来支持此业务。Doris 的计算模型对自定义函数的开发还是很友好的,能够比较好地满足我们的性能需要。
![]()
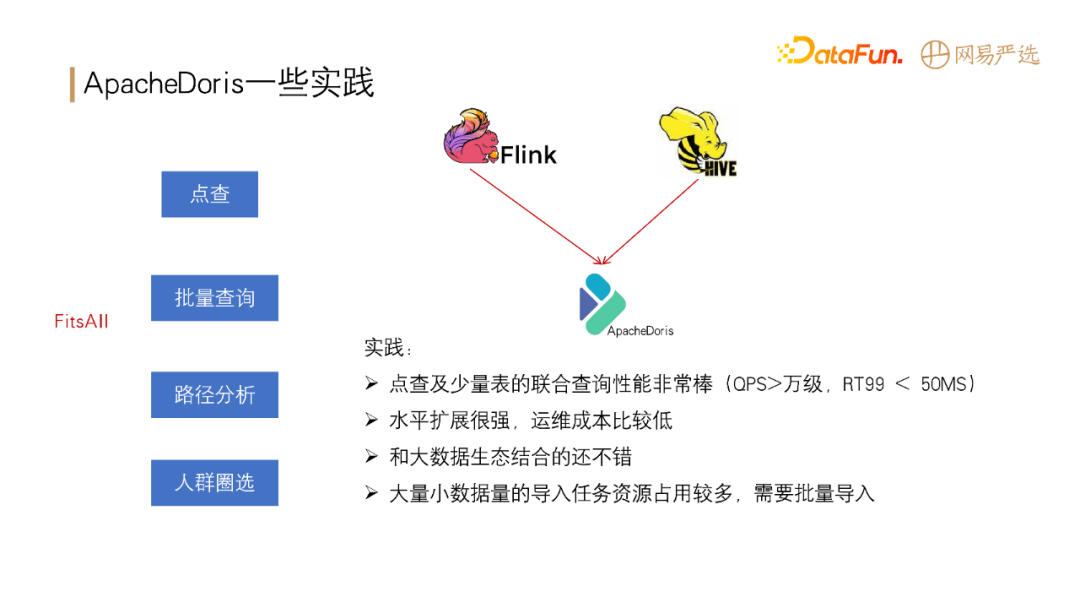
Apache Doris 在网易严选中已应用于点查、批量查询、路径分析、人群圈选等场景。在实践中具备以下优势:
不足之处在于大量小数据量的导入任务资源占用较多,不过此问题已经在 Doris 1.1 版本中进行了优化,**Doris 在 1.1 中大幅增强了数据 Compaction 能力,对于新增数据能够快速完成聚合,避免分片数据中的版本过多导致的 -235 错误以及带来的查询效率问题。**待 Doris 1.1.2 版本正式发布后我们也会及时同步升级。
具体可以参考:Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时
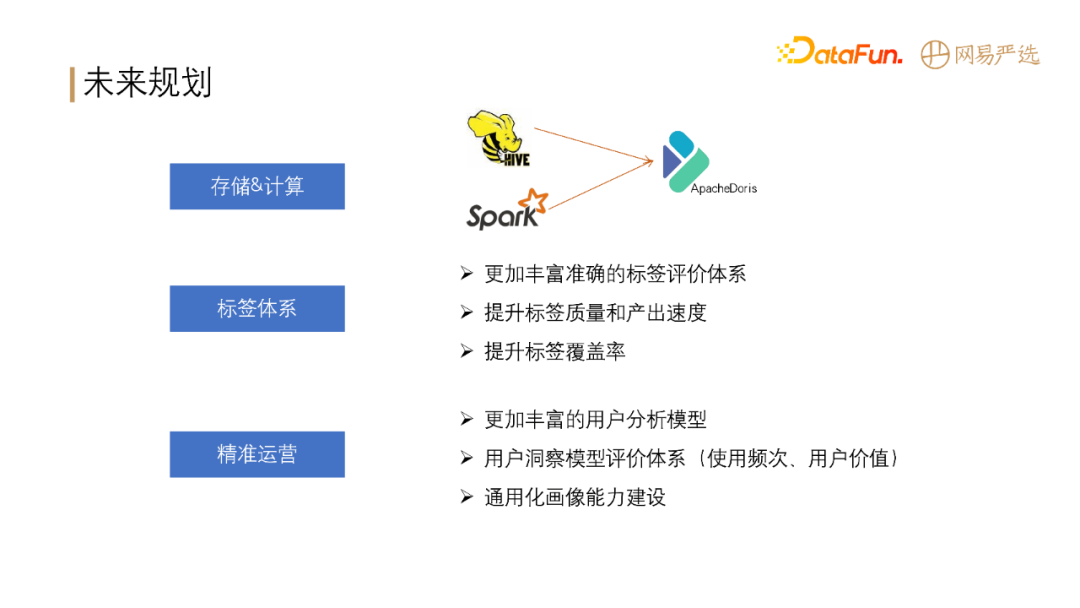
未来规划
![]()
提升存储&计算性能:Hive 和 Spark 逐渐全部转向 Apache Doris。
优化标签体系:
建立丰富准确的标签评价体系
提升标签质量和产出速度
提升标签覆盖率
更精准的运营
资料下载
关注公众号「SelectDB」,后台回复【网易严选】获取本次演讲 PPT 资料!
如果你对 Apache Doris 感兴趣,请点击「 **阅读原文 」了解并加入 Doris!我们也发起了征文活动****,**邀你讲讲与Doris相遇 相知 相识的故事,不仅有精美礼品相送,还可获得 SelectDB 全渠道曝光加持!
最后,欢迎更多的开源技术爱好者加入 Apache Doris 社区,携手成长,共建社区生态。
![]()
![]()
SelectDB 是一家开源技术公司,致力于为 Apache Doris 社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于 Apache Doris 研发的新一代云原生实时数仓 SelectDB,运行于多家云上,为用户和客户提供开箱即用的能力。
相关链接:
SelectDB 官方网站:
https://selectdb.com
Apache Doris 官方网站:
http://doris.apache.org
Apache Doris Github:
https://github.com/apache/doris
Apache Doris 开发者邮件组:
dev@doris.apache.org