

每日一博 | 推荐算法架构 —— 粗排
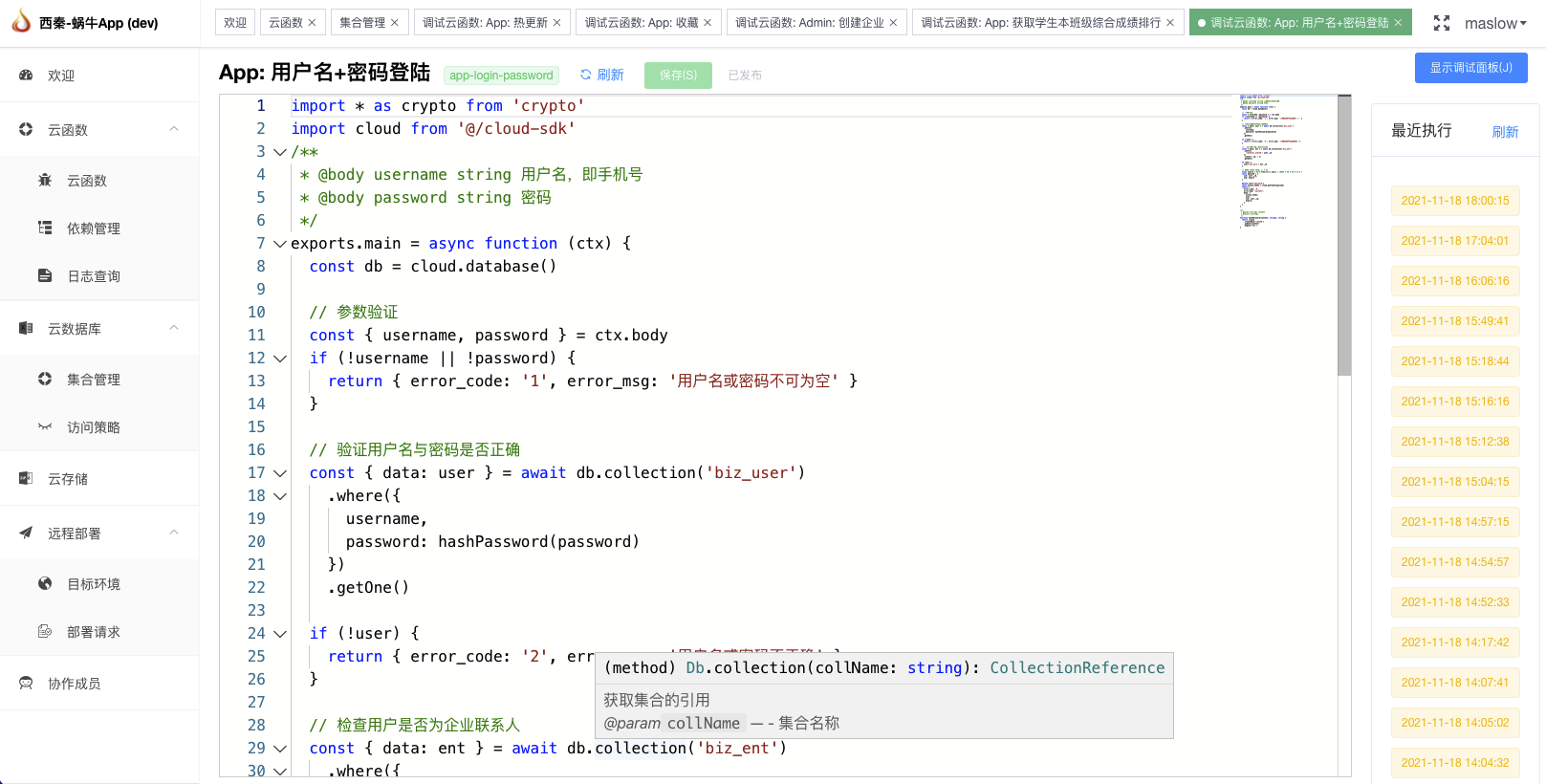
导语 | 粗排是介于召回和精排之间的一个模块,是典型的精度与性能之间trade-off的产物。理解粗排各技术细节,一定要时刻把精度和性能放在心中。 本篇将深入重排这个模块进行阐述。 一、总体架构 粗排是介于召回和精排之间的一个模块。它从召回获取上万的候选item,输出几百上千的item给精排,是典型的精度与性能之间trade-off的产物。对于推荐池不大的场景,粗排是非必选的。粗排整体架构如下: 二、粗排基本框架:样本、特征、模型 目前粗排一般模型化了,基本框架也是包括数据样本、特征工程、深度模型三部分。 (一)数据样本 目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。只使用曝光样本作为训练,但却要对曝光和非曝光同时预测,存在严重的样本选择偏差(SSB问题),导致训练与预测不一致。相比精排,显然粗排的SSB问题更严重。 (二)特征工程 粗排的特征也可以类似于精排,由于其计算延迟要求高,只有10ms~20ms,故一般可以粗分为两类: 普通特征:类似精排,user...