文章来源于亚马逊 AWS 官方博客
![]()
马丽丽,亚马逊云科技数据库解决方案架构师,十余年数据库行业经验,先后涉猎 NoSQL 数据库 Hadoop/Hive、企业级数据库 DB2、分布式数仓 Greenplum/Apache HAWQ 以及亚马逊云原生数据库的开发和研究。
1. 前言
Amazon Aurora 是亚马逊云科技自研的一项关系数据库服务,它在提供和开源数据库 MySQL、PostgreSQL 的完好兼容性同时,也能够提供和商业数据库媲美的性能和可用性。性能方面,Aurora MySQL 能够支持到与开源标准 MySQL 同等配置下五倍的吞吐量,Aurora PostgreSQL 能够支持与开源标准 PostgreSQL 同等配置下三倍的吞吐量的提升。在扩展性的角度,Aurora 在存储与计算、横向与纵向方面都进行了功能的增强和创新。Aurora 支持多达 128TB 的存储容量,而且支持 10GB 为单位的存储层动态收缩。计算方面,Aurora 提供多个读副本的可扩展性配置支持一个区域内多达 15 个读副本的扩展,提供多主的架构来支持同一个区域内 4 个写节点的扩展,提供 Serverless 无服务器化的架构实例级别的秒级纵向扩展,提供全球数据库来实现数据库的低延迟跨区域扩展。
随着用户数据量的增长,Aurora 已经提供了很好的扩展性,那是否可以进一步处理更多的数据量、支持更多的并发访问呢?您可以考虑利用分库分表的方式,来支持底层多个 Aurora 集群的配置。基于此,包含这篇博客在内的系列博客会进行相应的介绍,旨在为您进行分库分表时选择使用代理或者 JDBC 提供参考。
本篇博客会聚焦如何使用 ShardingSphere-Proxy,一个开源的分库分表中间件工具,来进行数据库集群的构建,会涵盖分库分表、读写分离、动态配置等方面。
2. ShardingSphere-Proxy 介绍
作为中间件,ShardingSphere-Proxy 的定位是透明化的数据库代理端。它采用 Apache2.0 协议,持续迭代版本,最新版本为 5.1.0,目前支持 MySQL 和 PostgreSQL 版本。它对应用程序透明,兼容 MySQL/PostgreSQL 协议的客户端。MySQL 命令行 mysql,MySQL workbench 等都可以直接访问 ShardingSphere-Proxy。
ShardingSphere-Proxy 下层可以连接不同的数据库,这些数据库可以是同构也可以是异构的。用户可以有两种方式指定底层数据库的分库分表或者读写分离规则:1)根据 yaml 配置文件静态指定;2)利用 ShardingSphere 提供的增强性的 DistSQL 语言来指定。因为 DistSQL 支持动态创建规则不需要重启 Proxy 本身,它成为 ShardingSphere-Proxy 未来发展的重点。
作为数据库代理,是否能够提供连接池增强用户并发访问的连接处理是需要考量的一方面,ShardingSphere-Proxy 在添加数据源并进行初始化时,会支持为每个数据库配置一个 Hikari 连接池。Hikari 是业界广泛使用的连接池,对性能损耗较小,而且被 SpringBoot 采用为缺省连接池。ShardingSphere-Proxy 的连接池可以支持用户配置最大连接数、最大空闲时间以及缓存相关的信息等。除 Hikari 连接池外,ShardingSphere-Proxy 也支持其它连接池的配置。
和现有 SQL 的语法兼容性也是用户衡量数据库代理的关键因素,因为这涉及到是否更改应用代码。以 MySQL 为例,ShardingSphere 支持大部分的 MySQL 语法,但也有少量不支持的语法,比如 optimize 表、资源组的管理、用户的创建和 GRANT 权限管理等。具体可以查阅 ShardingSphere 的最新文档。
下面会分享我对 ShardingSphere-Proxy 连接 Aurora 的几个维度的实验测试:1)分库分表;2)动态扩展;3)读写分离;4)多表 join;5)故障恢复。
3.环境构建
3.1Aurora 集群搭建
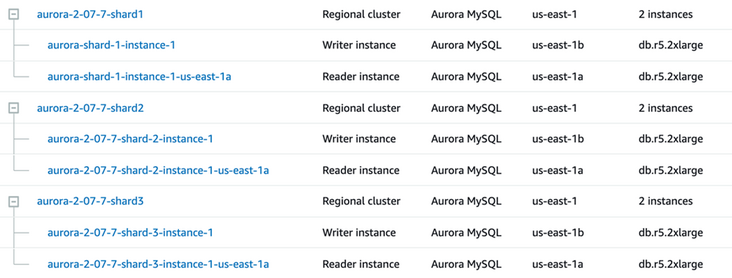
首先根据 Aurora 集群创建指南创建三套 Aurora MySQL 集群,机型为 db.r5.2xlarge,每套集群有一个写节点一个读节点。
![]()
3.2ShardingSphere-Proxy 搭建
在与 Aurora 相同的可用区下启动一台 EC2 节点,机型为 r5.8xlarge,然后在上面安装 ShardingSphere-Proxy。
3.2.1 下载安装包
直接下载二进制安装包,进行解压。下载最新版本 5.1.0,它对 DistSQL 支持较好。
wget https://dlcdn.apache.org/shardingsphere/5.1.0/apache-shardingsphere-5.1.0-shardingsphere-proxy-bin.tar.gz
tar -xvf apache-shardingsphere-5.1.0-shardingsphere-proxy-bin.tar.gz
ShardingSphere-Proxy 自带的库里包含对 PostgreSQL 的 JDBC driver,但不包含 MySQL 的 driver。因为创建的集群是 MySQL,需要将 MySQL 的 JDBC driver 拷贝到 lib 目录。
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
cp mysql-connector-java-5.1.47.jar apache-shardingsphere-5.1.0-shardingsphere-proxy-bin/lib/
3.2.2 配置 Proxy 的服务端
在 ShardingSphere-Proxy 的根目录下,有个配置文件目录为 conf,里面有一个文件是 server.yaml,用来配置 ShardingSphere-Proxy 自己作为代理对外提供服务的信息以及元信息存放等。下面是一个配置示例,里面配置了用户权限信息,特定属性信息,以及元信息以集群模式存放在 zookeeper 里。
rules:
- !AUTHORITY
users: //访问Proxy的用户名和密码信息
- root@%:root
- sharding@:sharding
provider: //控制用户对schema的登陆权限
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION //事务类型配置,支持本地事务、XA两阶段事务、BASE柔性事务
defaultType: XA
providerType: Atomikos
props: //特定属性配置
max-connections-size-per-query: 1
proxy-hint-enabled: true //为强制路由使用,默认值为false
mode: //元信息存放的配置,shardingsphereProxy支持三种模式:内存、单机和集群
type: Cluster
repository:
type: ZooKeeper //可以设置为zookeeper、etcd等
props:
namespace: shardingproxy
server-lists: localhost:2181
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: false
3.3启动 Proxy
直接在 ShardingSphere-Proxy 根目录下的 bin 对应着启动和停止脚本。运行时的日志在目录 logs 下。启动 Proxy:
3.4验证连接
如无特殊配置,ShardingSphere-Proxy 默认使用 3307 端口。使用 3.2.2 中配置的用户名和密码登录 Proxy。在 EC2 上运行 MySQL 命令行工具进行连接,连接成功。注意这里没有任何数据库,因为我们没有使用 YAML 配置文件预先配置数据源。
[ec2-user@ip-111-22-3-123 bin]$ mysql -h 127.0.0.1 -uroot --port 3307 -proot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.7.22-ShardingSphere-Proxy 5.1.0
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
Empty set (0.01 sec)
4.功能测试
4.1DistSQL 创建分片规则和数据分片测试
本节来验证 ShardingSphere 的基本的分库分表能力。ShardingSphere-Proxy 支持两种方式创建分片规则和读写分离规则,YAML 和 DistSQL。DistSQL 扩展了 SQL 语法,可以支持在线创建数据源、创建和更改建表规则,较为灵活,本文只介绍 DistSQL 的用例。
4.1.1 创建数据库
连接到 ShardingSphere-Proxy,去创建数据库,作为逻辑的分布式数据库。
MySQL [(none)]> create database distsql_sharding_db;
Query OK, 0 rows affected (0.90 sec)
在各个 Aurora 集群上创建数据库,作为数据库源进行连接。其中,rshard1,rshard2,rshard3 是我自己定义的连接 Aurora 数据库的 alias。
alias rshard1=’mysql -h $dbname -u$username -p$password’
[ec2-user@ ip-111-22-3-123 bin]$ rshard1 -e "create database dist_ds";
[ec2-user@ ip-111-22-3-123 bin]$ rshard2 -e "create database dist_ds;"
[ec2-user@ ip-111-22-3-123 bin]$ rshard3 -e "create database dist_ds;"
4.1.2 创建数据源
在 ShadingSphere-Proxy 中运行下面 DistSQL 语句创建 3 个数据源,分别指向 3 个不同 Aurora 集群。
MySQL [distsql_sharding_db]> add resource ds_0(url="jdbc:mysql://aurora-2-07-7-shard1.cluster-12345678.us-east-1.rds.amazonaws.com:3306/dist_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678);
Query OK, 0 rows affected (0.03 sec)
MySQL [distsql_sharding_db]> add resource ds_1(url="jdbc:mysql://aurora-2-07-7-shard2.cluster-12345678.us-east-1.rds.amazonaws.com:3306/dist_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678);
Query OK, 0 rows affected (0.06 sec)
MySQL [distsql_sharding_db]> add resource ds_2(url="jdbc:mysql://aurora-2-07-7-shard3.cluster-12345678.us-east-1.rds.amazonaws.com:3306/dist_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678);
Query OK, 0 rows affected (0.05 sec)
4.1.3 创建分片规则
这里指明 torder 表的分片规则,注意分片规则的表名和后续要创建的表表名一致。具体规则为:对底层的 3 个数据源(Aurora 集群)按照 orderid 对表进行 hash 分片,分成 6 份。另外,对 order_id 采用值自动生成的策略,采用策略为 snowflake 算法。ShardingSphere 支持两种分布式主键生成策略:UUID 和雪花算法 SNOWFLAKE。使用雪花算法生成的主键,二进制表示形式包含 4 部分,从高位到低位分表为:1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。在 ShardingSphere-Proxy 中运行下面 DistSQL 语句建立分片规则:
MySQL [distsql_sharding_db]> CREATE SHARDING TABLE RULE t_order(
→ RESOURCES(ds_0,ds_1, ds_2),
→ SHARDING_COLUMN=order_id,
→ TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=6)),
→ KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=snowflake))
→ );
Query OK, 0 rows affected (0.02 sec)
4.1.4 建表
建表语句和普通 MySQL 建表语句一致。在 ShardingSphere-Proxy 中运行下面语句建表:
MySQL [distsql_sharding_db]> CREATE TABLE `t_order` ( `order_id` bigint NOT NULL, `user_id` int NOT NULL, `status` varchar(45) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
-> ;
Query OK, 0 rows affected (0.22 sec)
在 ShardingSphere-Proxy 上查看表的状态。
MySQL [distsql_sharding_db]> show tables;
+-------------------------------+------------+
| Tables_in_distsql_sharding_db | Table_type |
+-------------------------------+------------+
| t_order | BASE TABLE |
+-------------------------------+------------+
1 row in set (0.00 sec)
分别连接到 3 个 Aurora 集群上查看表是否自动创建。可以看到每个底层数据库集群上都创建了两张表,一共是 6 张表。而且表名是以“toder”数字排序的。
[ec2-user@ ip-111-22-3-123 bin]$ rshard1 -Ddist_ds -e "show tables;"
+-------------------+
| Tables_in_dist_ds |
+-------------------+
| t_order_0 |
| t_order_3 |
+-------------------+
[ec2-user@ ip-111-22-3-123 bin ]$ rshard2 -Ddist_ds -e "show tables;"
+-------------------+
| Tables_in_dist_ds |
+-------------------+
| t_order_1 |
| t_order_4 |
+-------------------+
[ec2-user@ ip-111-22-3-123 bin]$ rshard3 -Ddist_ds -e "show tables;"
+-------------------+
| Tables_in_dist_ds |
+-------------------+
| t_order_2 |
| t_order_5 |
+-------------------+
4.1.5 插入和查找数据
在 ShardingSphere-Proxy 中插入并查找数据,数据可以正常插入和查找成功。在 ShardingSphere-Proxy 中运行:
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (1, 'ok');
insert into t_order(user_id, status) values (2, 'abc');
Query OK, 1 row affected (0.01 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (2, 'abc');
insert into t_order(user_id, status) values (3, 'abc');
Query OK, 1 row affected (0.00 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (3, 'abc');
insert into t_order(user_id, status) values (4, 'abc');
Query OK, 1 row affected (0.01 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (4, 'abc');
insert into t_order(user_id, status) values (5, 'abc');
Query OK, 1 row affected (0.00 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (5, 'abc');
insert into t_order(user_id, status) values (6, 'abc');
Query OK, 1 row affected (0.01 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (6, 'abc');
insert into t_order(user_id, status) values (7, 'abc');
Query OK, 1 row affected (0.00 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (7, 'abc');
insert into t_order(user_id, status) values (8, 'abc');
Query OK, 1 row affected (0.01 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (8, 'abc');
Query OK, 1 row affected (0.00 sec)
MySQL [distsql_sharding_db]> insert into t_order(user_id, status) values (9, 'abc');
Query OK, 1 row affected (0.00 sec)
MySQL [distsql_sharding_db]> select * from t_order;
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161915748353 | 2 | abc |
| 708700161995440128 | 5 | abc |
| 708700169725542400 | 9 | abc |
| 708700161877999616 | 1 | ok |
| 708700161936719872 | 3 | abc |
| 708700162041577472 | 7 | abc |
| 708700161970274305 | 4 | abc |
| 708700162016411649 | 6 | abc |
| 708700162058354689 | 8 | abc |
+--------------------+---------+--------+
9 rows in set (0.01 sec)
去各个 Aurora 集群中查找子表插入的数据,可以看到在 Proxy 插入的 9 条记录被打散到底层的 6 张表中。因为 order_id 为 snowflake 算法生成而数据量比较小,这里的数据并不均匀。
[ec2-user@ip-111-22-3-123 bin]$ rshard1 -Ddist_ds -e "select * from t_order_0;"
[ec2-user@ip-111-22-3-123 bin]$ rshard1 -Ddist_ds -e "select * from t_order_3;"
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161915748353 | 2 | abc |
+--------------------+---------+--------+
[ec2-user@ip-111-22-3-123 bin]$ rshard2 -Ddist_ds -e "select * from t_order_1;"
[ec2-user@ip-111-22-3-123 bin]$ rshard2 -Ddist_ds -e "select * from t_order_4;"
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161995440128 | 5 | abc |
| 708700169725542400 | 9 | abc |
+--------------------+---------+--------+
[ec2-user@111-22-3-123 bin]$ rshard3 -Ddist_ds -e "select * from t_order_2;"
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161877999616 | 1 | ok |
| 708700161936719872 | 3 | abc |
| 708700162041577472 | 7 | abc |
+--------------------+---------+--------+
[ec2-user@ip-111-22-3-123 bin]$ rshard3 -Ddist_ds -e "select * from t_order_5;"
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161970274305 | 4 | abc |
| 708700162016411649 | 6 | abc |
| 708700162058354689 | 8 | abc |
+--------------------+---------+--------+</code></pre></div>
上述实验验证了 ShardingSphere-Proxy 具有创建逻辑库、连接数据源、创建分片规则、创建逻辑表时会自动在底层数据库上创建子表、能够执行查询的分发以及聚合能力。
4.2动态伸缩验证(在线扩展分片)
本节来验证 ShardingSphere-Proxy 是否具有动态更改表的分片规则的能力。
ShardingSphere-Proxy 提供在线更改分片规则的能力,但是如果子表已经按照之前的规则创建成功,则不会有新的子表随着分片数目的增多被创建出来,也不会有原来的子表随着分片数目的减少而被删除。所以需要手动在底层分片数据库上创建表名和迁移数据。
将 4.1 节里的表的分片数从 6 调高到 9,修改分片规则本身能够成功,但是后续查找会出错,因为没有新的子表创建出来。在 ShardingSphere-Proxy 上运行下面 DistSQL:
MySQL [distsql_sharding_db]> alter SHARDING TABLE RULE t_order(
-> RESOURCES(ds_0,ds_1, ds_2),
-> SHARDING_COLUMN=order_id,
-> TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=9)),
-> KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=snowflake))
-> );
Query OK, 0 rows affected (0.01 sec)
MySQL [distsql_sharding_db]> select * from t_order;
ERROR 1146 (42S02): Table 'dist_ds.t_order_6' doesn't exist
如果此时在子集群上分别创建好对应的子表,再在 ShardingSphere-Proxy 上查找就不会再出错。连接到 3 个 Aurora 集群,手动创建子表。
[ec2-user@ip-111-22-3-123 bin]$ rshard1 -Ddist_ds -e "create table t_order_6(order_id bigint not null, user_id int not null, status varchar(45) default null, primary key(order_id)) engine=innodb default charset=utf8mb4; "
[ec2-user@ ip-111-22-3-123 bin]$ rshard2 -Ddist_ds -e "create table t_order_7(order_id bigint not null, user_id int not null, status varchar(45) default null, primary key(order_id)) engine=innodb default charset=utf8mb4; "
[ec2-user@ip-111-22-3-123 bin]$ rshard3 -Ddist_ds -e "create table t_order_8(order_id bigint not null, user_id int not null, status varchar(45) default null, primary key(order_id)) engine=innodb default charset=utf8mb4; "
Proxy 查找整个逻辑表不再报错。在 ShardingSphere-Proxy 上运行下面 SQL:
MySQL [distsql_sharding_db]> select * from t_order;
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161915748353 | 2 | abc |
| 708700161995440128 | 5 | abc |
| 708700169725542400 | 9 | abc |
| 708700161877999616 | 1 | ok |
| 708700161936719872 | 3 | abc |
| 708700162041577472 | 7 | abc |
| 708700161970274305 | 4 | abc |
| 708700162016411649 | 6 | abc |
| 708700162058354689 | 8 | abc |
+--------------------+---------+--------+
9 rows in set (0.01 sec)
如果有新的数据插入,会按照新的分片规则进行到子表的映射。在 ShardingSphere-Proxy 上查看 SQL 语句的查询计划:
MySQL [distsql_sharding_db]> preview insert into t_order values(7, 100, 'new');
+------------------+---------------------------------------------+
| data_source_name | sql |
+------------------+---------------------------------------------+
| ds_1 | insert into t_order_7 values(7, 100, 'new') |
+------------------+---------------------------------------------+
1 row in set (0.00 sec)
MySQL [distsql_sharding_db]> insert into t_order values(7, 100, 'new');
Query OK, 1 row affected (0.00 sec)
登录到 Aurora 子集群上查看子表,可以看到数据已经成功插入。
[ec2-user@ip-111-22-3-123 bin]$ rshard2 -Ddist_ds -e "select * from t_order_7;"
+----------+---------+--------+
| order_id | user_id | status |
+----------+---------+--------+
| 7 | 100 | new |
+----------+---------+--------+
再来看下在线减少分片的情况。如果将分片数目调小,比如调到 3,表里的已有数据不会被迁移,查找整张表时只能拿到部分数据。在 ShardingSphere-Proxy 上运行下面 DistSQL 和 SQL 语句:
MySQL [distsql_sharding_db]> alter SHARDING TABLE RULE t_order(
-> RESOURCES(ds_0,ds_1, ds_2),
-> SHARDING_COLUMN=order_id,
-> TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=3)),
-> KEY_GENERATE_STRATEGY(COLUMN=order_id,TYPE(NAME=snowflake))
-> );
Query OK, 0 rows affected (0.02 sec)
MySQL [distsql_sharding_db]> select * from t_order;
+--------------------+---------+--------+
| order_id | user_id | status |
+--------------------+---------+--------+
| 708700161877999616 | 1 | ok |
| 708700161936719872 | 3 | abc |
| 708700162041577472 | 7 | abc |
+--------------------+---------+--------+
3 rows in set (0.00 sec)
经过上面验证,我们的结论是 ShardingSphere-Proxy 的分片规则是可以在线更改的,但子表的创建和数据的重新分布需要手动去完成。
4.3绑定表和广播表的测试
本节来验证 ShardingSphere-Proxy 对于多表 join 的支持。尽管 OLTP 的数据库中的操作通常较为简单,但也有可能会涉及到多表 join 的情况。ShardingSphere-Proxy 针对多表 join 的优化有支持绑定表和广播表。如果两张表是绑定表而且 join 时采用的是 shard key,可以进行两张表的 join。广播表通过把小表复制到各个节点,可以实现大表和小表的快速 join。
4.3.1 绑定表
ShardingSphere-Proxy 的绑定表可以通过 DistSQL 里的 CREATE SHARDING BINDING TABLE RULES 来绑定两张表。这里以 4.1 节中提到的 torder 表和新创建的一张表 torder_item 为例进行展开。
连接到 ShardingSphere-Proxy 上运行下面 DistSQL 和 SQL 语句。
MySQL [distsql_sharding_db]> CREATE SHARDING TABLE RULE t_order_item(
-> RESOURCES(ds_0,ds_1, ds_2),
-> SHARDING_COLUMN=order_id,
-> TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=6)));
Query OK, 0 rows affected (0.04 sec)
MySQL [distsql_sharding_db]> CREATE TABLE `t_order_item` ( `order_id` bigint NOT NULL, `item_id` int NOT NULL, `name` varchar(45) DEFAULT NULL, PRIMARY KEY (`item_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ;
Query OK, 0 rows affected (0.08 sec)
创建了 binding rule 以后,查看 join 计划,我们看到 join 下推到对应子表和子表的 join 上。在 ShardingSphere-Proxy 上运行:
MySQL [distsql_sharding_db]> CREATE SHARDING BINDING TABLE RULES (t_order,t_order_item);
Query OK, 0 rows affected (0.04 sec)
MySQL [distsql_sharding_db]> preview select * from t_order, t_order_item where t_order.order_id=t_order_item.order_id;
+------------------+------------------------------------------------------------------------------------------+
| data_source_name | sql |
+------------------+------------------------------------------------------------------------------------------+
| ds_0 | select * from t_order_0, t_order_item_0 where t_order_0.order_id=t_order_item_0.order_id |
| ds_0 | select * from t_order_3, t_order_item_3 where t_order_3.order_id=t_order_item_3.order_id |
| ds_1 | select * from t_order_1, t_order_item_1 where t_order_1.order_id=t_order_item_1.order_id |
| ds_1 | select * from t_order_4, t_order_item_4 where t_order_4.order_id=t_order_item_4.order_id |
| ds_2 | select * from t_order_2, t_order_item_2 where t_order_2.order_id=t_order_item_2.order_id |
| ds_2 | select * from t_order_5, t_order_item_5 where t_order_5.order_id=t_order_item_5.order_id |
+------------------+------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
4.3.2 广播表
广播表是指每张表在每个库里都有一个完整的备份,可以通过 CREATE SHARDING BROADCAST TABLE RULES 来指定。
MySQL [distsql_sharding_db]> CREATE SHARDING BROADCAST TABLE RULES (t_user);
Query OK, 0 rows affected (0.03 sec)
MySQL [distsql_sharding_db]> create table t_user (user_id int, name varchar(100));
Query OK, 0 rows affected (0.04 sec)
登录到各个 shard Aurora 集群查看创建的表。可以看到与分片表的子表名末尾有数字序号不同的是,广播表对应的每个库上的名字是相同的,就是逻辑表名本身。
[ec2-user@ip-111-22-3-123 bin]$ rshard1 -D dist_ds -e "show tables like '%user%';"
+----------------------------+
| Tables_in_dist_ds (%user%) |
+----------------------------+
| t_user |
+----------------------------+
[ec2-user@ip-111-22-3-123 bin]$ rshard2 -D dist_ds -e "show tables like '%user%';"
+----------------------------+
| Tables_in_dist_ds (%user%) |
+----------------------------+
| t_user |
+----------------------------+
[ec2-user@ip-111-22-3-123 bin]$ rshard3 -D dist_ds -e "show tables like '%user%';"
+----------------------------+
| Tables_in_dist_ds (%user%) |
+----------------------------+
| t_user |
+----------------------------+
在 ShardingSphere-Proxy 中运行广播表和其它表的 join,采用的是本地 join 的方式。
MySQL [distsql_sharding_db]> preview select * from t_order, t_user where t_order.user_id=t_user.user_id;
+------------------+------------------------------------------------------------------------+
| data_source_name | sql |
+------------------+------------------------------------------------------------------------+
| ds_0 | select * from t_order_0, t_user where t_order_0.user_id=t_user.user_id |
| ds_0 | select * from t_order_3, t_user where t_order_3.user_id=t_user.user_id |
| ds_1 | select * from t_order_1, t_user where t_order_1.user_id=t_user.user_id |
| ds_1 | select * from t_order_4, t_user where t_order_4.user_id=t_user.user_id |
| ds_2 | select * from t_order_2, t_user where t_order_2.user_id=t_user.user_id |
| ds_2 | select * from t_order_5, t_user where t_order_5.user_id=t_user.user_id |
+------------------+--------
上面实验验证了 ShardingSphere-Proxy 是可以支持两张绑定表的 join,以及广播表和分片表的 join 的。对于非绑定的两张分片表的 join,ShardingSphere-Proxy 有一个 Federation 的功能是在支持的,但还不是很成熟,建议后续持续关注。
4.4读写分离功能验证
本节来验证 ShardingSphere-Proxy 对于读写分离的支持。随着业务增长,写和读的负载分别在不同的数据库节点上能够有效提供整个数据库集群的处理能力。Aurora 通过读/写的 endpoint 可以满足用户写和强一致性读的需求,只读的 endpoint 可以满足用户非强一致性读的需求。Aurora 的读写延迟在毫秒级别,比 MySQL 基于 binlog 的逻辑复制要低得多,所以有很多负载是可以直接打到只读 endpoint 的。
ShardingSphere-Proxy 提供的读写分离的特性可以进一步可以封装 Aurora 的读/写端点和只读端点。用户可以直接连接到 Proxy 的端点,即可进行自动的读写分离。ShardingSphere-Proxy 对特殊情况的处理逻辑是:1)同一线程且同一数据库连接内,如果有写入操作,则后续的读操作均从主库读取;2)可以通过 Hint 的机制强制把读请求发到写节点(主库)。下面会以 Aurora3 个集群中的第一个集群来验证 ShardingSphere-Proxy 读写分离的能力。
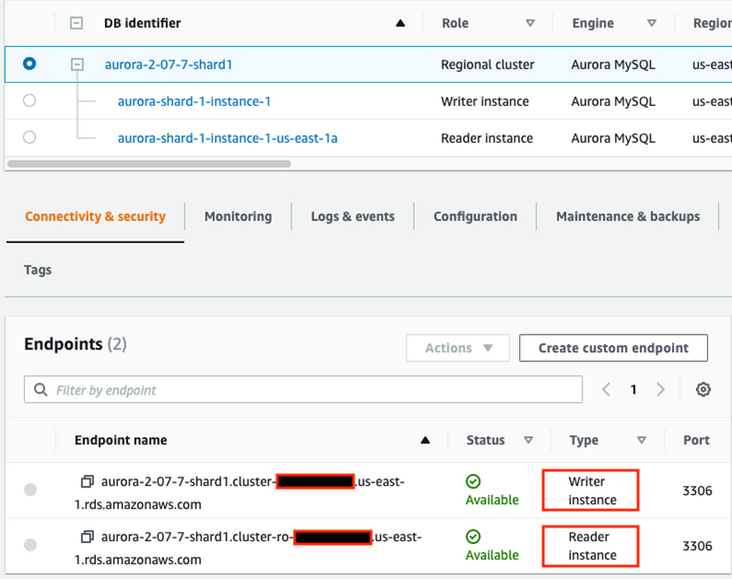
4.4.1 查看 Aurora 集群读/写端点和只读端点
Aurora 集群有两个端点,写的端点和读的端点。
![]()
4.4.2 在 Aurora 集群中创建数据库
连接到 Aurora 集群中运行:
[ec2-user@ip-111-22-3-123 ~]$ rdbw -e "create database wr_ds;"
4.4.3 数据源配置
在 ShardingSphere-Proxy 上创建数据源,写的数据源指向 Aurora 的读写 endpoint,读的数据源指向 Aurora 的只读 endpoint。注意:对域名的情况,ShardingSphere-Proxy 只支持通过 url 的方式创建数据源,尚未支持通过 HOST、Port 的方式。连接到 ShardingSphere-Proxy 上创建逻辑数据库 distsqlrwsplitdb 并在改数据库中添加数据源:
MySQL [(none)]> create database distsql_rwsplit_db;
Query OK, 0 rows affected (0.02 sec)
MySQL [(none)]> use distsql_rwsplit_db;
Database changed
MySQL [distsql_rwsplit_db]> add resource write_ds(url="jdbc:mysql://aurora-2-07-7-shard1.cluster-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678), read_ds(url="jdbc:mysql://aurora-2-07-7-shard1.cluster-ro-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678);
Query OK, 0 rows affected (0.08 sec)
4.4.4 读写分离规则配置
创建读写分离规则,写请求发到写的数据源,读请求发到读的数据源。与分库分表规则要求 RULE 后面必须是表名不同的是,这里的 RULE 后面跟的是数据源的名字,适用于在这个数据库里创建的所有的表。在 ShardingSphere-Proxy 上运行下面 DistSQL 语句:
MySQL [distsql_ rwsplit_db]> CREATE READWRITE_SPLITTING RULE wr_ds (
-> WRITE_RESOURCE=write_ds,
-> READ_RESOURCES(read_ds),
-> TYPE(NAME=random)
-> );
Query OK, 0 rows affected (0.36 sec)
4.4.5 建表
创建一张普通表,建表语句和 MySQL 建表语句一致。在 ShardingSphere-Proxy 上运行下面 SQL 语句:
MySQL [distsql_ rwsplit_db]> create table wr_table (a int, b int, c varchar(20));
Query OK, 0 rows affected (0.17 sec)
4.4.6 检查读写分离是否实现
在 ShardingSphere-Proxy 上运行下面语句查看查询计划,查看语句是发送到底层哪个数据源。可以看到:写请求发送到写节点,读请求会发送到读写点。
MySQL [distsql_rwsplit_db]> preview insert into wr_table values(1,1,'ab');
+------------------+---------------------------------------+
| data_source_name | sql |
+------------------+---------------------------------------+
| write_ds | insert into wr_table values(1,1,'ab') |
+------------------+---------------------------------------+
1 row in set (0.10 sec)
MySQL [distsql_rwsplit_db]> preview select * from wr_table;
+------------------+------------------------+
| data_source_name | sql |
+------------------+------------------------+
| read_ds | select * from wr_table |
+------------------+------------------------+
1 row in set (0.02 sec)
运行一个脚本来多次操作,再去 Aurora 集群指标监控中去验证。该脚本是一个循环,运行 1000 次,每次会插入一条记录,并查找表的记录总条数。
[ec2-user@ip-111-22-3-123 shardingproxy]$ cat testReadWrite.sh
#!/bin/bash
n=1
while [ $n -le 1000 ]
do
mysql -h 127.0.0.1 -uroot --port 3307 -proot -Ddistsql_rwsplit_db -e "insert into wr_table values($n,$n,'ok');"
mysql -h 127.0.0.1 -uroot --port 3307 -proot -Ddistsql_rwsplit_db -e "select count(*) from wr_table;"
let n++
done
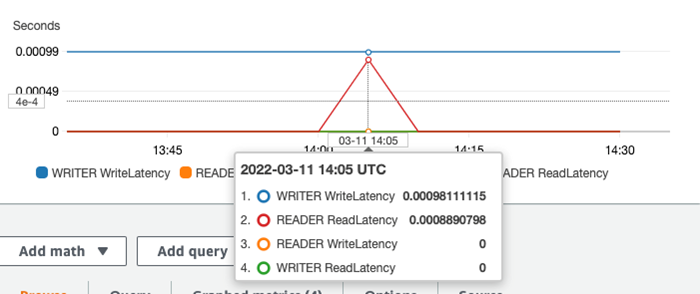
查看 Aurora 集群的写节点和读节点的读写延迟,可以看到写延迟只在写节点上发生,读延迟只在读节点上发生。说明读写分离规则生效。
![]()
尽管 Aurora 的写和读节点之间的复制延迟很低在毫秒级别,但某些应用还是会有强一致性的需求,即要求写后立刻可以读。这时候,可以采用强制将读请求发送到写节点的方式。ShardingSphere-Proxy 通过 hint 的方式来支持。首先需要在前面提到的 conf/server.yaml 里添加一个属性 proxy-hint-enabled: true。然后在连接中显式设置 readwritesplitting hint source 值为 write 来开启强制路由到写节点通过设置值为 auto 或者 clear hint 可以采用默认的规则。readwritesplitting hint source 可以在 session 级别生效。
在 ShardingSphere-Proxy 上依次运行下面语句。可以看到默认的读请求是发送到读节点,将 readwrite_splitting hint source 设置为 write 以后,会发送到写节点,再设成 auto,可以发回至读写点。
MySQL [distsql_rwsplit_db]> preview select count(*) from wr_table;
+------------------+-------------------------------+
| data_source_name | sql |
+------------------+-------------------------------+
| read_ds | select count(*) from wr_table |
+------------------+-------------------------------+
1 row in set (0.01 sec)
MySQL [distsql_rwsplit_db]> set readwrite_splitting hint source = write;
Query OK, 0 rows affected (0.00 sec)
MySQL [distsql_rwsplit_db]> preview select count(*) from wr_table;
+------------------+-------------------------------+
| data_source_name | sql |
+------------------+-------------------------------+
| write_ds | select count(*) from wr_table |
+------------------+-------------------------------+
1 row in set (0.01 sec)
MySQL [distsql_rwsplit_db]> set readwrite_splitting hint source = auto;
Query OK, 0 rows affected (0.00 sec)
MySQL [distsql_rwsplit_db]> preview select count(*) from wr_table;
+------------------+-------------------------------+
| data_source_name | sql |
+------------------+-------------------------------+
| read_ds | select count(*) from wr_table |
+------------------+-------------------------------+
1 row in set (0.00 sec)
另外不使用 YAML 文件更改的方式是直接在 DistSQL 里先后设置两个变量 proxyhintenabled 和 readwrite_splitting hint source。
MySQL [distsql_rwsplit_db]> set variable proxy_hint_enabled=true;
Query OK, 0 rows affected (0.01 sec)
MySQL [distsql_rwsplit_db]> set readwrite_splitting hint source = write;
Query OK, 0 rows affected (0.01 sec)
MySQL [distsql_rwsplit_db]> preview select * from wr_table;
+------------------+------------------------+
| data_source_name | sql |
+------------------+------------------------+
| write_ds | select * from wr_table |
+------------------+------------------------+
1 row in set (0.00 sec)
以上实验验证了 ShardingSphere-Proxy 有良好的读写分离的能力。它验证了底下连接单个 Aurora 集群进行读写分离的场景。如果既需要分库分表又需要读写分离,ShardingSphere-Proxy 也是支持的。比如先分到 3 个 Aurora 集群,然后每个集群需要提供读写分离的能力,我们可以直接将读写分离规则后面定义的数据源名称(4.4.4 里的 wrds)放在分库分表规则对每张表指定的数据源里(4.1.3 里的 ds0,ds1,ds2)。
4.5故障恢复验证
本节来验证 ShardingSphere-Proxy 对于 Aurora 集群故障切换的感知能力。在 Aurora 集群发生主备切换时,如果 Proxy 能够动态检测到主备切换并连接到新的主数据库是比较理想的。本节实验仍然是验证第一个 Aurora 集群。
测试脚本如下,它会持续连接到写节点并发送 update 请求,每次请求间隔 1 秒钟。
[ec2-user@ip-111-22-3-123 shardingproxy]$ cat testFailover.sh
#!/bin/bash
while true
do
mysql -h 127.0.0.1 -uroot --port 3307 -proot -Ddistsql_rwsplit_db -e "update wr_table set c='failover' where a = 1;"
now=$(date +"%T")
echo "update done: $now"
sleep 1
done
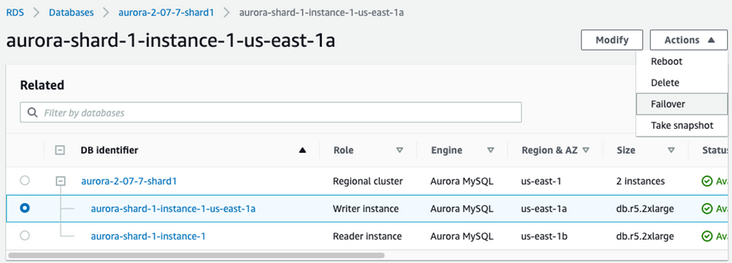
运行脚本,然后在 Aurora 集群的写节点上点击 Action->Failover。会启动 Aurora 写节点和读节点的自动切换。在切换过程中,整个集群的读/写 endpoint 和只读 endpoint 维持不变,只是底层映射的节点发生变化。
![]()
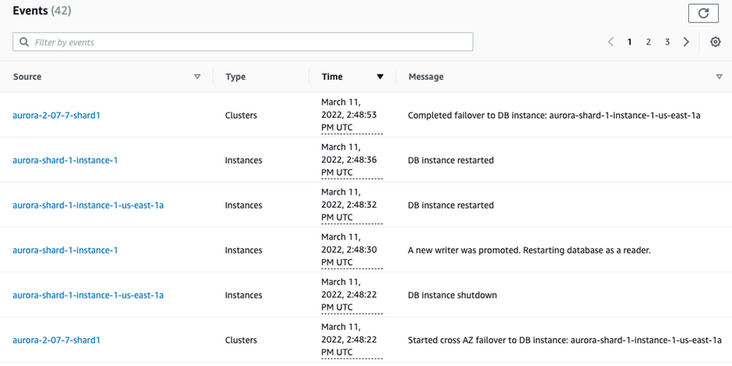
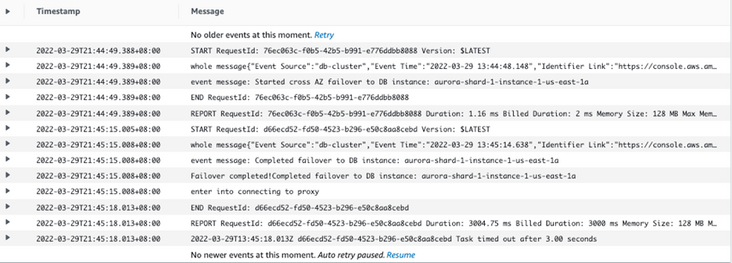
通过观测 Aurora 的 Event(事件),可以看到整个故障切换在 30 秒左右完成。
![]()
遗憾的是,应用程序直接连接 ShardingSphere-Proxy 也就是前面的运行脚本不能自动监测到底层的 IP 变化。运行脚本一直抛错:
ERROR 1290 (HY000) at line 1: The MySQL server is running with the --read-only option so it cannot execute this statement
update done: 15:04:04
ERROR 1290 (HY000) at line 1: The MySQL server is running with the --read-only option so it cannot execute this statement
update done: 15:04:05
ERROR 1290 (HY000) at line 1: The MySQL server is running with the --read-only option so it cannot execute this statement
update done: 15:04:06
直接在 MySQL 命令行连接到 Proxy 也是会有一样的错误。
MySQL [distsql_rwsplit_db]> update wr_table set c="failover" where a =2;
ERROR 1290 (HY000): The MySQL server is running with the --read-only option so it cannot execute this statement
分析原因在于 Aurora 发生故障切换的时候,读写 endpoint 和 IP 的映射会发生变化,而 ShardingSphere 的连接池在连接 Aurora 的时候,没有更新到新的 IP 上。我们可以采用下面的 workaround 可以使 ShardingSphere-Proxy 指向新的写节点,即重新创建数据源。尽管数据源本身定义没有发生变化,但是通过重建数据源 alter resource 的操作, ShardingSphere-Proxy 会重新拿取一遍 endpoint 到 IP 的映射,所以能够成功运行。
MySQL [distsql_rwsplit_db]> alter resource write_ds(url="jdbc:mysql://aurora-2-07-7-shard1.cluster-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678), read_ds(url="jdbc:mysql://aurora-2-07-7-shard1.cluster-ro-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false",user=admin,password=12345678);
Query OK, 0 rows affected (0.05 sec)
MySQL [distsql_rwsplit_db]> update wr_table set c="failover" where a =2;
Query OK, 1 row affected (0.01 sec)
每次 Aurora 故障切换时,我们可以检测故障切换的 event,或者是在应用收到 read-only 报错时显式调用上面语句。为了降低对应用的影响,我们可以采用 Lambda 的方式将 failover 重置数据源的操作自动化。因为 Aurora 的 failover 的事件是可以被监测到的,我们可以写一个 Lambda 函数,在监测到 failover 成功以后,显示调用更改 resource 的操作。
总体的思路是:RDS 通过 Event Subscription 将 Event 的通知信息传递给 SNS topic,再由 SNS topic 传递给 Lambda 方法,然后在 Lambda 方法里显式连接 ShardingSphere-Proxy 调用 alter resource 的 DistSQL 语句。
具体步骤如下:
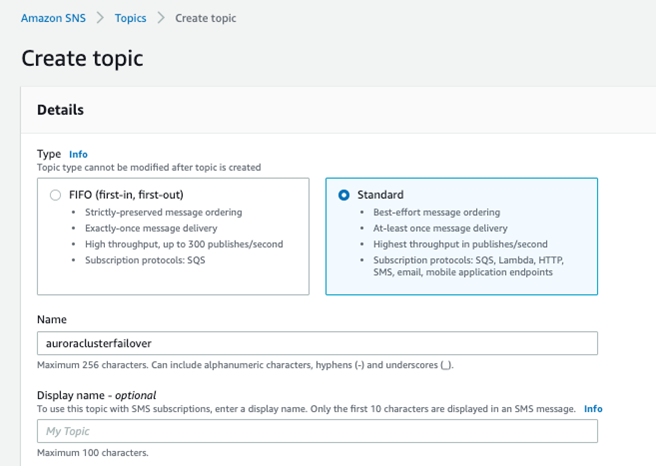
4.5.1 创建 SNS
按照 SNS 创建指南创建 SNS。打开 SNS 的 dashboard,点击创建 SNS topic,选择 Standard 标准类型。其它选择默认或者根据需要调整。
![]()
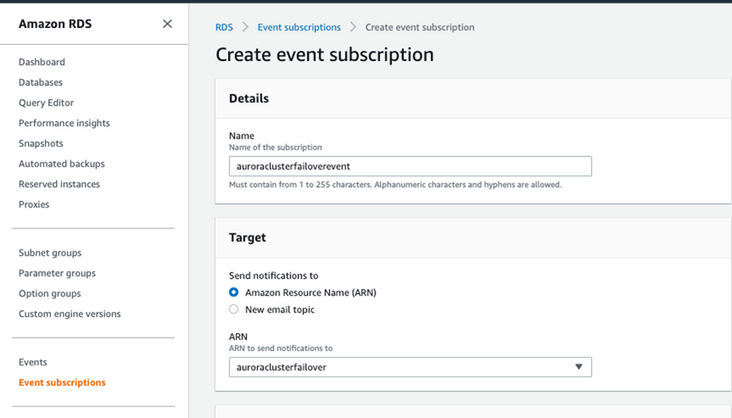
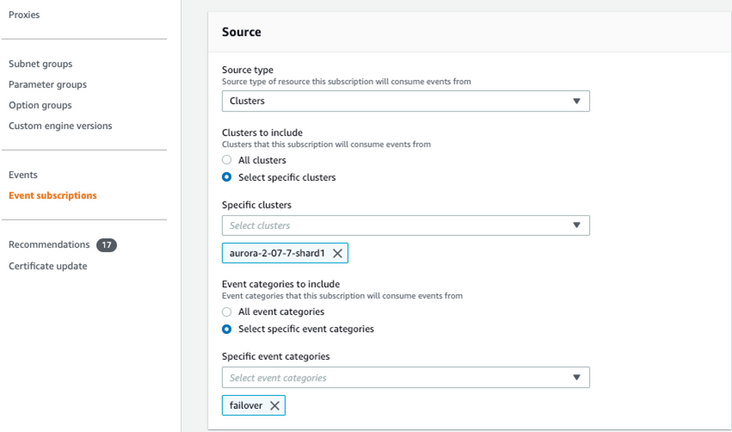
4.5.2 对要进行的 Aurora 集群创建 Event Subscription
在 RDS 的 Event Subscriptions 上,点击“Create Event Subscription”,在弹出的选项卡中选择 Target 为上一步骤创建的 SNS,Source type 选择为 Cluster,Cluster 里面选中我们需要关注的 Aurora 的集群,事件选择 Failover 事件。
![]()
![]()
4.5.3 创建 Lamdba 方法
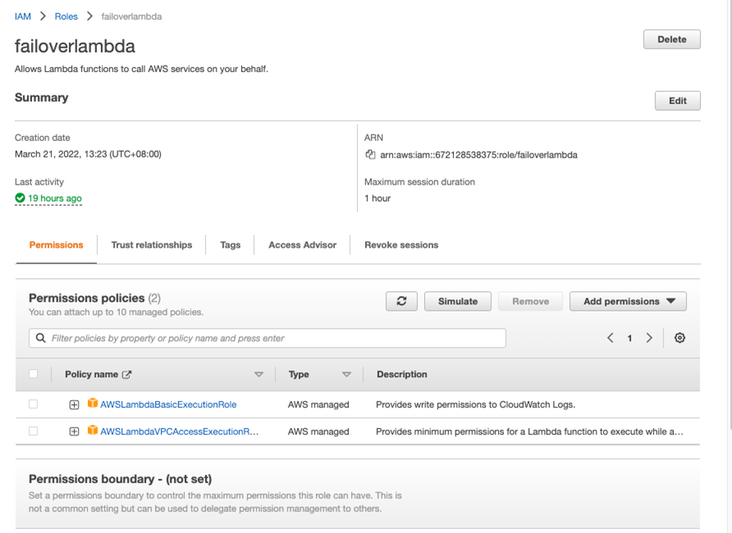
因为 Lambda 要调用 VPC 里的 EC2 上部署的 ShardingProxy,应该给它绑定一个专门的 Role,这个 Role 有权限在 VPC 里执行 Lambda 方法: AWSLambdaVPCAccessExecutionRole 按照 IAM Role(https://docs.aws.amazon.com/zhcn/IAM/latest/UserGuide/idrolescreatefor-service.html)创建文档创建 Role 和 Policy,使 failoverlambda 的 role 有 AWSLambdaVPCAccessExecutionRole 的权限。
![]()
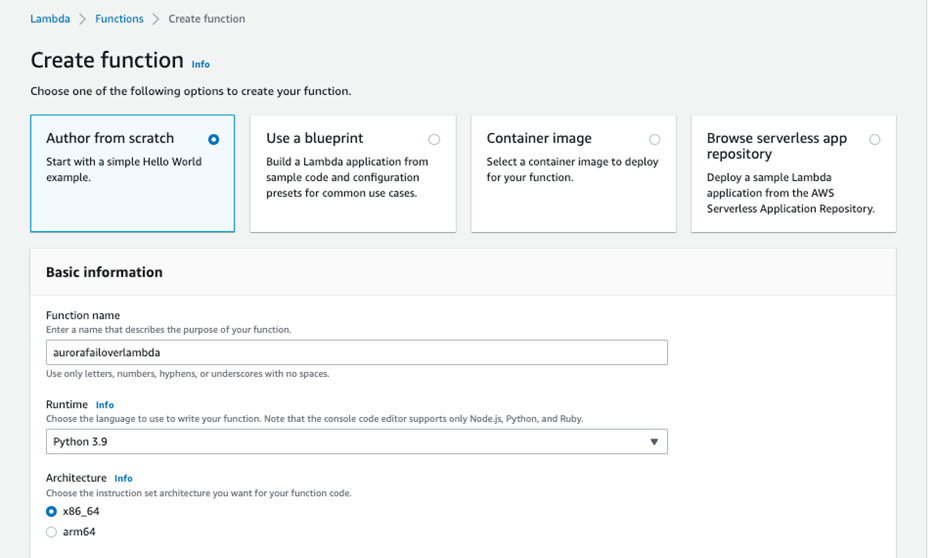
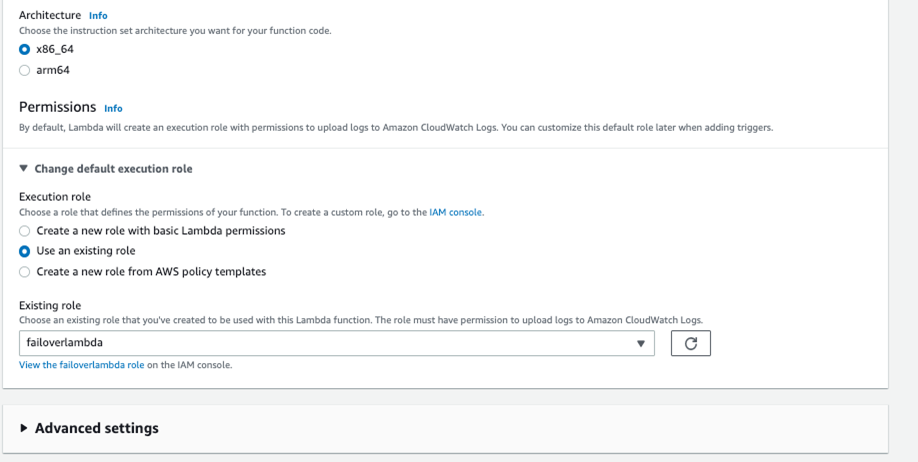
接下来按照 Lambda文档创建 Lambda 方法。
![]()
![]()
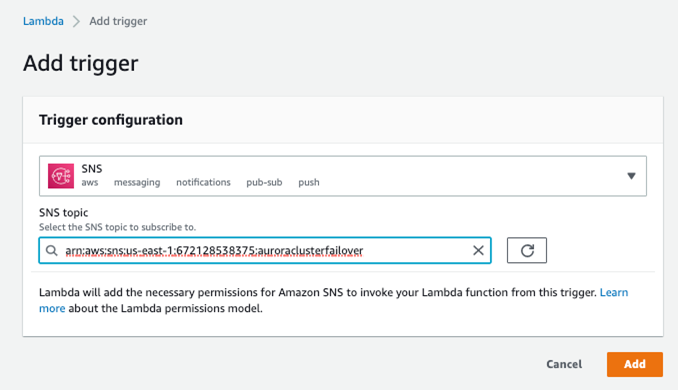
创建好 Lambda 方法以后,点击 Trigger,指明为 SNS,并指明在 4.5.1 里创建的 SNS topic。
![]()
![]()
4.5.4 编写 Lambda 方法
import os
import json
import pymysql
# connect to ShardingProxy to reset the data source
def resetDataSource():
db = pymysql.connect(host='111.22.3.123', user='root', password='root', port=3307, database='distsql_rwsplit_db')
cur = db.cursor()
SQL = "alter resource write_ds(url=\"jdbc:mysql://aurora-2-07-7-shard1.cluster-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false\",user=admin,password=12345678), read_ds(url=\"jdbc:mysql://aurora-2-07-7-shard1.cluster-ro-12345678.us-east-1.rds.amazonaws.com:3306/wr_ds?serverTimezone=UTC&useSSL=false\",user=admin,password=12345678);"
print (SQL)
cur.execute(SQL)
result = cur.fetchall()
for x in result:
print(x)
db.close()
def lambda_handler(event, context):
wholeMessage = event['Records'][0]['Sns']['Message']
print ("whole message" + wholeMessage)
wholeMessageInJson = json.loads(wholeMessage)
eventMessage = wholeMessageInJson['Event Message']
print ("event message: " + eventMessage)
isFailover = eventMessage.startswith('Completed failover to DB instance')
if isFailover == True:
print ("Failover completed! " + eventMessage)
resetDataSource()
return {
'statusCode': 200,
'body': Lambda Invocation Successful!'
}
Lambda 方法是 Python 语言书写的,在访问 ShardingSphere-Proxy 时以 MySQL 方式访问,所以需要引入 pymysql 的 lib 库。具体方法为:
1)在 Linux 上安装 pymysql,以 Amazon-Linux 虚拟机为例,会默认安装到目录 ./home/ec2-user/.local/lib/python3.7/site-packages/pymysql 下
2)将 pymysql 目录拷贝到临时目录 /tmp
3)写 Lambda 方法,存储到 lambda_function.py 文件中
4)打包 zip -r lambda.zip pymysql lambda_function.py
5) 在控制台通过 S3 或者本地上传。
4.5.5 设置 ShardingSphere-Proxy 所在 EC2 的 security group
因为 Lambda 要在 VPC 里访问 ShardingSphere-Proxy,而 ShardingSphere-Proxy 以 3307 端口运行,应该配置相应 secuity group,打开 3307 端口给同一个 VPC 内部的访问。依据安全组配置文档配置成的 security group 如下:
![]()
4.5.6 验证 failover
重复本小节开始的操作,运行 testFailover.sh,然后手动在 RDS console 页 failover Aurora 节点,会发现 testFailover.sh 持续稳定输出, 不会再出现 read-only 的错误。
update done: 13:44:44 … update done: 13:44:47 update done: 13:45:00 update done: 13:45:01 … update done: 13:45:17
去 cloudwatch 里查看 Lambda function 的日志,会发现 Lambda 被成功调用。
![]()
以上实验验证了 ShardingSphere-Proxy 对于 Aurora 集群故障切换的感知能力。尽管 ShardingSphere-Proxy 自己没有提供良好的匹配性,通过监测 Aurora 集群事件触发 Lamdba 方法来显式重置 ShardingSphere-Proxy 数据源的方式,我们可以实现 ShardingSphere-Proxy 与 Aurora 结合的故障切换能力。
5.结语
本篇文章通过数据库中间件 ShardingSphere-Proxy 拓展了 Aurora 的分库分表能力和读写分离的能力。
ShardingSphere-Proxy 内置连接池,对 MySQL 语法支持较强,在分库分表和读写分离上表现出色。它对多表 join 上,可以支持分片规则相同的表的 join,以及小表和大表的 join,基本能满足 OLTP 场景的需求。在动态分片上,ShardingSphere-Proxy 提供在线更改分片规则的能力,但需要用户在底层 Aurora 集群手动操作子表创建及数据迁移,需要一定工作量。故障切换维度,ShardingSphere-Proxy 与 Aurora 的融合不是很好,但是可以通过本文提供的 Aurora 故障切换 Event 调用 Lambda 方法来显式重置数据源的方式,实现 ShardingSphere-Proxy 对 Aurora 集群故障切换对感知。
总体而言,ShardingSphere-Proxy 这个中间件产品还是能与 Aurora 集群进行一个良好匹配,进一步提升 Aurora 集群的读写能力的。它有良好的文档,也是比较受关注的开源产品,建议读者在考虑 Aurora 分库分表实现时,评估下这个产品。后续我们会继续推出对其他中间件以及 JDBC 方面的拓展和研究系列博客。
如果大家对 Apache ShardingSphere 有任何疑问或建议,欢迎在 GitHub issue 列表提出,或可前往中文社区交流讨论。
GitHub issue:https://github.com/apache/shardingsphere/issues
贡献指南:https://shardingsphere.apache.org/community/cn/contribute/
中文社区:https://community.sphere-ex.com/
欢迎点击链接,了解更多内容:
Apache ShardingSphere 官网:https://shardingsphere.apache.org/
Apache ShardingSphere GitHub 地址:https://github.com/apache/shardingsphere
SphereEx 官网:https://www.sphere-ex.com
欢迎添加社区经理微信(ssassistant1)加入交流群,与众多 ShardingSphere 爱好者一同交流。
![]()