摘要:信息检索、分类、识别、翻译等领域两个最基本指标是准确率(precision rate)和召回率(recall rate),准确率也叫查准率,召回率也叫查全率。
本文分享自华为云社区《准确率、召回率及AUC概念分析》,作者: savioyo。
信息检索、分类、识别、翻译等领域两个最基本指标是准确率(precision rate)和召回率(recall rate),准确率也叫查准率,召回率也叫查全率。这些概念非常重要的一个前提是针对特定的分类器和测试集的,即不同的数据集也会导致不同的结果。
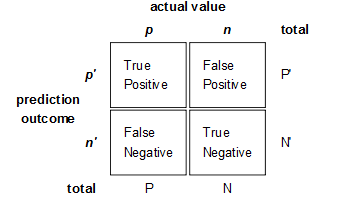
- True Positives,TP:预测为正样本,实际也为正样本的特征数
- False Positives,FP:预测为正样本,实际为负样本的特征数(错预测为正样本了,所以叫False)
- True Negatives,TN:预测为负样本,实际也为负样本的特征数
- False Negatives,FN:预测为负样本,实际为正样本的特征数(错预测为负样本了,所以叫False)
- TP+FP+FN+FN:特征总数(样本总数)
- TP+FN:实际正样本数
- FP+TN:实际负样本数
- TP+FP:预测结果为正样本的总数
- TN+FN:预测结果为负样本的总数
![]()
通过医生诊病的例子来理解和记忆。
假设下面的场景:
医生为病人看病,病人是否有病与医生是否正确诊断,两个条件两两组合就形成了四种可能性。
- 病人有病并且被医生正确诊断,属于TP,即真阳性;
- 病人有病并且被医生错误诊断,属于FN,即假阴性;
- 病人无病并且被医生正确诊断,属于TN,即真阴性;
- 病人无病并且被医生错误诊断,属于FP,即假阳性;
再举一个动作识别的例子。
假定测试集合为100条数据,其中90条数据被模型判定为驾车,10条数据被判定为步行。在被判定为驾车的90条数据中,有80条数据是被正确判断的,10条数据是被错误判断的;在被判定为步行的10条数据中,有6条数据是被正确判断的,4条数据是被错误判断的。那么,我们将这四个数据填写到表格中。
- TP = 80; FP = 10
- FN = 4; TN = 6
这些数据都是针对驾车这一个类别来分类的,也就是准确率和召回率是针对某一个特定的类别来说的。
准确率的计算为 80 / (80 + 10) = 8/9,召回率的计算为80 / (80 + 4) = 20/21。
再举一个例子,这个例子是我最初用来理解准确率和召回率的例子,但是在我真正理解了准确率和召回率之后,这个例子反而具有了迷惑性。下面是网络上传的比较多的版本。
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
如果将池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标则变化为如下:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
之所以说这个例子有迷惑性,是我们应该用什么数据来填写上述的表格呢,也就是如何找到TP、FP、FN、TN呢?其实这个例子,有一些条件被默认了,或者被隐藏了,没有直接写出来。首先,这2000个生物是我们的整体的测试集合,当我们以鲤鱼为目的来进行分类时,将其中的1000个标记为鲤鱼类,剩余的1000个标记为非鲤鱼类,其中标记为鲤鱼类的1000个中,700个是被正确标记的,300个是被错误标记的;标记为非鲤鱼类的1000个中,700个是被错误标记的,300个是被正确标记的。其次,分类器是渔网开始捕捉时的行为,而不是已经捕捉完成之后的分类行为。
- TP = 700; FP = 300
- FN = 700; TN = 300
计算公式
准确率 = 系统检索到的相关文件/系统所有检索到的文件总数 (TP/(TP+FP))
召回率 = 系统检索到的相关文件/系统所有相关的文件总数 (TP/(TP+FN))
F值 = 准确率 * 召回率 * 2 / (正确率 + 召回率),F值即为正确率和召回率的调和平均值
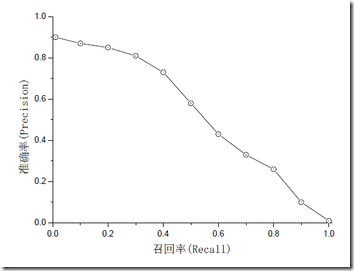
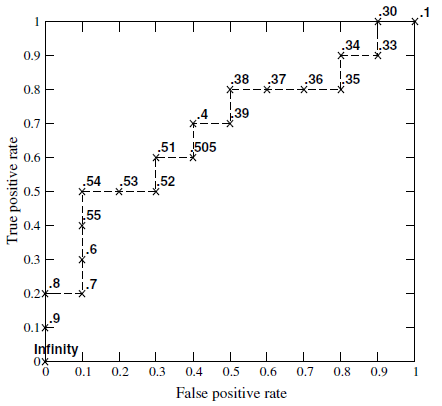
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低;召回率高、准确率就低,当然如果两者都低,那是什么地方出问题了。一般情况下,用不同的阈值(此处可认为是不同的模型),统计出一组不同阈值下的准确率和召回率,如下图:
![]()
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保证准确率的条件下,提升召回。所以,如果在两者要求都高的情况下,可以用F值来衡量。
ROC&&AUC
ROC和AUC是评价分类器的指标,ROC的全名是Receiver Operating Characteristic。
ROC关注两个指标:
True Positive Rate(TPR) = TP / (TP + FN),TPR代表能将正例分对的概率
False Positive Rate(FPR) = FP / (FP + TN),FPR代表将负例错分为正例的概率
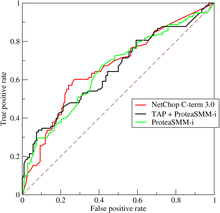
在ROC空间中,每个点的横坐标是FPR,纵坐标是TPR,这也描述了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0),(1,1),实际上(0,0),(1,1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0,0),(1,1)连线的上方。如图所示:
![]()
用ROC curve来表示分类器的performance很直观好用。可是,人们总希望能有一个数值来标识分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。
从Mann-Whitney U statistic的角度来解释,AUC就是从所有1样本中随机选取一个样本,从所有0样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把1样本预测为1的概率为p1,把0预测为1的概率为p0,p1 > p0的概率就等于AUC。所以AUC反映的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本分类,那么AUC应该接近0.5。
AUC&&PR
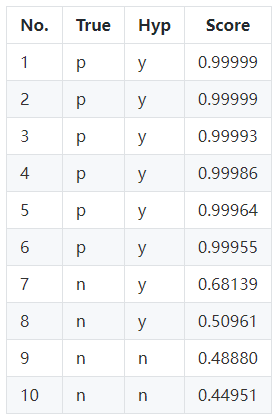
一个分类算法,找个最优的分类效果,对应到ROC空间中的一个点。通常分类器的输出都是Score,比如SVM、神经网络,有如下的预测结果:
TABLE 一般分类器的结果都是Score表
![]()
True表示实际样本属性,Hyp表示预测结果样本属性,第4列即是Score,Hyp的结果通常是设定一个阈值,比如上表就是0.5,Score>0.5为正样本,小于0.5为负样本,这样只能算出一个ROC值,为更综合的评价算法的效果,通过取不同的阈值,得到多个ROC空间的值,将这些值描绘出ROC空间的曲线,即为ROC曲线。
![]()
有了ROC曲线,更加具有参考意义的评价指标就有了,在ROC空间,算法绘制的ROC曲线越凸向左上方向效果越好,有时不同分类算法的ROC曲线存在交叉,因此很多文章里用AUC(即Area Under Curve曲线下的面积)值作为算法好坏的评判标准。
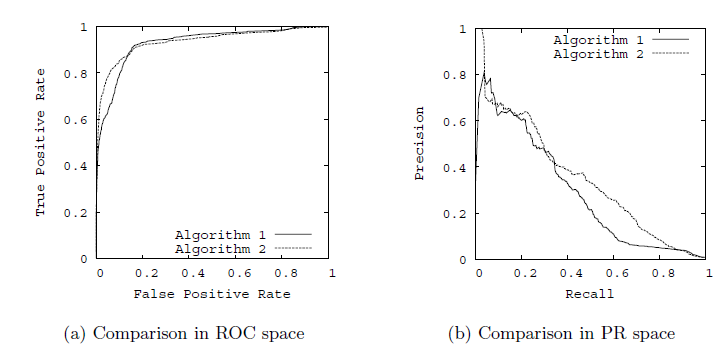
与ROC曲线左上凸不同的是,PR曲线是右上凸效果越好,下面是两种曲线凸向的简单比较:
![]()
作为衡量指标,选择ROC或PR都是可以的。但是参考资料显示,ROC和PR虽然具有相同的出发点,但并不一定能得到相同的结论,在写论文的时候也只能参考着别人已有的进行选择了。
点击关注,第一时间了解华为云新鲜技术~