摘要:什么是辅助驾驶?简而言之,就是借助汽车对周围环境的自动感知和分析,让驾驶员预先察觉可能发生的危险,有效增加汽车驾驶的舒适性和安全性。
导读:基于昇腾AI异构计算架构CANN的辅助驾驶AI应用实战开发案例,不仅可以实时检测路面车辆,还能计算出车距,辅助驾驶员进行决策。此项目源码全部开源,传送门已开启,小伙伴们快来体验吧!
引言
科幻片中光怪陆离的飞行器,寄托着人类对未来出行的无限遐想。随着科技的进步,能够自动驾驶的汽车,已经离我们越来越近。
自动驾驶带给人类的惊喜不止是酷炫的自动超车变道,还有它在缓解交通阻塞、减少空气污染、提高道路安全性方面的种种可能性。因此也引得无数汽车企业、科技企业竞相加入这条行业赛道,力求不断突破。
![]()
然而,自动驾驶并不是一蹴而就的,由于技术瓶颈和相关法律法规的限制并未真正意义落地,当下的智能汽车正处于半自动驾驶(辅助驾驶)阶段。
什么是辅助驾驶?简而言之,就是借助汽车对周围环境的自动感知和分析,让驾驶员预先察觉可能发生的危险,有效增加汽车驾驶的舒适性和安全性。
当然,辅助驾驶系统也是非常复杂的,为实现汽车在多种复杂场景下的通用性,以及技术层面的多样性,离不开人工智能技术。我们开发了一套基于昇腾AI异构计算架构CANN(Compute Architecture for Neural Networks)的简易版辅助驾驶AI应用,具备车辆检测、车距计算等基本功能,作为辅助驾驶入门级项目再合适不过啦!
话不多说,开启项目传送门:https://www.hiascend.com/zh/developer/mindx-sdk/driveassist
![]()
CANN是华为专门针对AI场景推出的异构计算架构,以提升用户开发效率和释放昇腾AI处理器澎湃算力为目的,并且提供多层次的AscendCL编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
当然,真正意义上的辅助驾驶系统远比这个AI应用更复杂,下面主要介绍如何借助AscendCL编程接口对输入视频进行预测推理,从而实现对车辆及车道线的智能检测。
典型的目标检测算法
为模仿驾驶员对车辆的辨别和分析,需要建立起一个类似人脑的算法结构,找出目标物体,确定它们的类别和位置。同时也需要解决影响检测准确性的一系列问题,比如汽车的外观和姿态、光照和遮挡等因素带来的干扰。
以YOLO(You Only Look Once)为代表的目标检测算法为各类物体的检测提供了更多可能性。从人脸检测到车流控制,从人群计数到农作物监控,目标检测算法在各领域都发挥着不可或缺的作用。
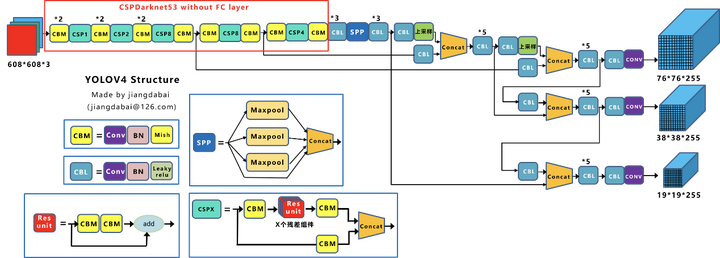
YOLO算法目前已经迭代到v5版本,本项目使用的是YOLOv4,下面我们来看看它的结构。
![]()
图片来自https://blog.csdn.net/andyjkt/article/details/107590669
从算法结构方面看,YOLOv4由三部分组成:Backbone层提取特征,Neck层提取一些更复杂的特征,最后由Head层计算预测输出。
- Backbone层:通过CSPDarknet53框架在不同图像细粒度上聚合并形成具备图像特征的卷积神经网络,主要用于图像特征提取。
- Neck层:由SPP或PAN等一系列混合和组合图像特征的网络层组成,提取一些更复杂的特性,并将图像特征传递到预测层。
- Head层:对图像特征进行预测,生成边界合并预测类别。
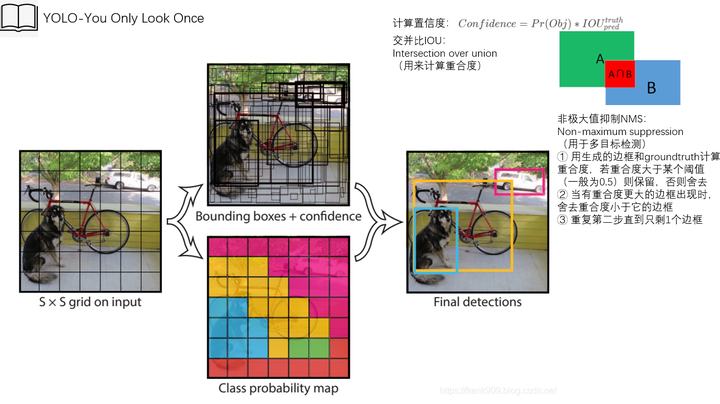
从流程方面看,YOLOv4主要分为三个处理阶段:
- 首先,将图像分割为若干个网格(grid cell),每个网格负责生成3个包围框(bounding box),以及对应置信度。
- 接着,YOLOv4会用非极大值抑制算法(NMS),将与标注数据(ground truth)重合度低的bounding box剔除。
- 经过回归处理后,最后剩下的bounding box所在的位置就是YOLOv4预测目标所在的位置。
![]()
图片源自YOLO原始论文,参见文章末尾
昇腾强大算力平台,让训练“快”到飞起
和人类掌握某项技能一样,算法模型本身也需要经过不断地训练和试错才能满足特定业务场景需求,面对成千上万的数据量和参数量,训练时间可能需要几天甚至上月,这时,一个拥有强大算力的AI计算平台简直能救你于水火。
昇腾AI基础软硬件平台,依托昇腾AI处理器强大的算力,借助异构计算架构CANN的软硬件协同优化充分释放硬件算力,为高效训练奠定了坚实的基础。
我们知道,AI算法模型可以基于不同AI框架定义。无论是华为开源AI框架昇思MindSpore,还是TensorFlow、PyTorch、Caffe等其他常用AI框架,CANN都能轻松转换成标准化的Ascend IR(Intermediate Representation)表达的图格式,屏蔽AI框架差异,让你快速搞定算法迁移,即刻体验昇腾AI 处理器的澎湃算力。
此外,在全新一代CANN 5.0版本中,更是能通过图级和算子级的编译优化、自动调优等软硬件深度协同优化,全面释放硬件澎湃算力,达到AI模型训练性能的大幅提升。针对包括分类、检测、NLP、语义分割在内的常用模型训练场景,均可实现性能翻番,让整个训练过程快到“飞”起。
本项目使用的YOLOv4原始模型是基于Pytorch框架和昇腾AI处理器训练的,开发者们可以直接下载使用,也可根据实际精度需要重训:https://www.hiascend.com/zh/software/modelzoo/detail/2/e2c648dc7ffb473fb41d687a1a490e28
AscendCL接口助力开发者高效编程
有了训练好的AI算法模型之后,就能借助AscendCL编程接口实现对视频车辆及车道线的智能检测了。
AscendCL(Ascend Computing Language)是一套用于开发深度神经网络推理应用的C语言API库,兼具运行时资源管理、模型加载与执行、图像预处理等能力,能够让开发者轻松解锁图片分类、目标检测等各类AI应用。并且为开发者屏蔽底层处理器的差异,让开发者只需要掌握一套API,就可以全面应用于昇腾全系列AI处理器。
借助AscendCL编程接口,采用如下图所示的模块化设计,便能快速实现一个基于YOLOv4算法的目标检测应用。
![]()
首先介绍一下核心代码。
在预处理阶段,主要将opencv读到的图像转换成符合模型输入标准格式和尺寸的图像(源码如下图所示,完整版代码请查看文末链接)。
- 首先将opencv每帧读到的BGR图像转换成RGB图像,并通过模型输入所需宽高与原图像宽高得到缩放系数scale、偏移量shift、偏移系数shift_ratio。
- 将原图像resize到新的宽高得到image_,构建一个全0的新图像,宽高和模型输入宽高相同。将image_以np.array的形式填充到全0的图像中,不在偏移范围内的则都是0,将的图像的数据类型转换成np中32位浮点型。
- 为了消除奇异样本数据的影像,进一步做归一化处理。
- 最后将通道数换到图像的第一维度,返回新生成的图像和原始图像。
![]()
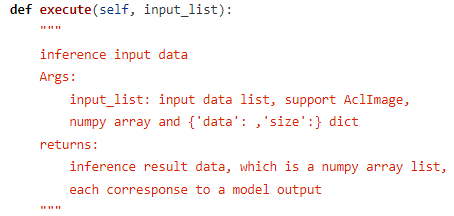
在推理阶段,调用acl_model中的execute函数执行模型(完整版代码请查看文末链接),预处理后的图像会被送至转成om的YOLOv4模型,返回推理结果。
![]()
![]()
在后处理阶段中,后处理包括根据推理结果获取检测框坐标和置信度,使用NMS消除多余的边框,使用透视变换矩阵计算车距,用opencv检测车道线,最终绘制带有车辆检测框、检测框类别、车距和车道线的新图像。
![]()
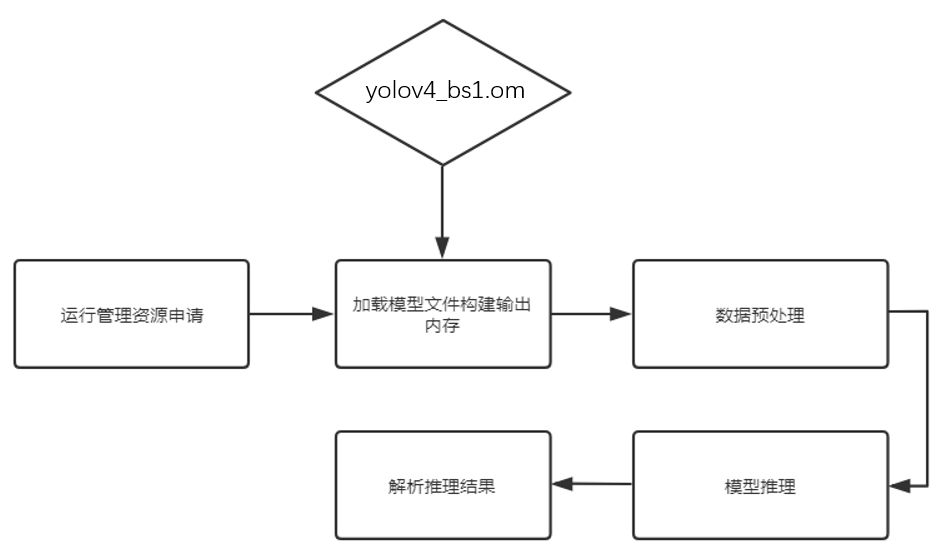
梳理一下整体开发流程:
- 运行管理资源申请:用于初始化系统内部资源,此部分为固定的调用流程。
- 加载模型文件并构建输出的内存:将训练好的模型转换成om离线模型并且从文件加载。此时需要由用户自行管理模型运行的内存,根据内存中加载的模型获取模型的基本信息包括模型输入、输出数据的buffer大小。由模型的基本信息构建模型输出内存,为接下来的模型推理做准备。
- 数据预处理:对读入的图像数据进行预处理,然后构建模型的输入数据。首先会对输入视频中的图像画面按每帧进行处理;然后由BGR转成RGB格式;接着使用resize将图像大小变成416x416,最后除以255进行归一化处理以消除奇异数据的影响。
- 模型推理:根据构建好的模型输入数据进行模型推理。
- 解析推理结果:基于推理得到的检测边框和各边框的置信度,使用NMS消除多余的边框,将新的边框和类别绘制在输出图像上。
这样,一个基于CANN开发的简易版AI辅助驾驶小应用就开发完成了,小伙伴们点击如下链接就能直接体验效果啦!https://www.hiascend.com/zh/developer/mindx-sdk/driveassist
![]()
可能有人会问,车距是怎么算出来的?其实车距计算采用的是透视变换原理,使用opencv的getPerspectiveTransform方法通过将驾驶过程中拍摄的直视图转换成俯视图计算车距。此外,用来拍摄行驶画面的相机也影响车距的计算。需要查找相机的内外参矩阵,结合畸变系数用相机标定技术将图像中的距离信息映射为客观世界中的真实距离,从而计算出与其他车的距离。这几个参数如何查找可以参考文末的视频链接。
我们的项目代码全部开源,感兴趣的小伙伴可以下拉到文末直接访问源码。
当前开发的这个AI辅助驾驶小应用,针对分辨率1280x720、帧率29.97、时长16秒的视频,单帧图像在昇腾AI处理器上的纯推理时长为14.19毫秒,但由于图像的前处理和后处理是在CPU上进行的,因此影响整体性能,可通过以下方式改进:
- 前处理和后处理根据CPU数量和处理时长使用多个线程并行处理,提高昇腾AI处理器使用率。
![]()
- 使用多个昇腾AI处理器进行多路推理,进一步提升性能。
- 优化代码算法,将后处理部分由CPU下沉到昇腾AI处理器减少后处理耗时,如何下沉可参考
https://gitee.com/ascend/samples/tree/master/python/level2_simple_inference/2_object_detection/YOLOV3_coco_detection_picture_with_postprocess_op
- 使用Auto Tune工具,对模型进行调优,减少模型单次推理时长
- 使用Profiling工具,分析模型中耗时算子,对算子进行优化
欢迎小伙伴一起参与项目改进,如有疑问也欢迎在gitee互动留言!
总结
如今很多汽车、高铁和飞机上都搭载了辅助驾驶系统,不仅可以减轻驾驶员的负担,同时还降低了事故发生的概率。随着越来越多的行业汇入AI这条道路,昇腾CANN也将凭借技术优势大大降低企业和个人开发者的使用门槛,通过不断创新打造昇腾AI极致性能体验,加速AI应用行业落地步伐,助力合作伙伴在未来AI之路上越走越远!
相关链接:
在线体验链接:https://www.hiascend.com/zh/developer/mindx-sdk/driveassist
Gitee源码链接:https://gitee.com/ascend/samples/tree/master/python/level2_simple_inference/2_object_detection/YOLOV4_coco_detection_car_video
YOLOv4原论文:https://arxiv.org/abs/2004.10934
YOLO原论文:https://arxiv.org/pdf/1506.02640.pdf
YOLOv4模型实现:https://github.com/AlexeyAB/darknet
相机参数查找方法:https://www.bilibili.com/video/BV1Fq4y1H7sx/
点击关注,第一时间了解华为云新鲜技术~