背景
TiDB 作为分库分表方案的一个 “终结者”,获得了许多用户的青睐。在切换到 TiDB 之后,用户告别了分库分表查询和运维带来的复杂度。但是在从分库分表方案切换到 TiDB 的过程中,这个复杂度转移到了数据迁移流程里。TiDB DM 工具为用户提供了分库分表合并迁移功能,在数据迁移的过程中,支持将分表 DML 事件合并迁移,并一定程度支持上游分表进行 DDL 变更。
本文以及后续文章主要介绍分库分表合并迁移时,各分表 DDL 变更的协调。DM 的分库分表 DDL 协调可配置为 “悲观协调” 和 “乐观协调”,本文主要介绍 TiDB DM 分库分表 DDL 协调的 “悲观协调” 模式。后续文章会介绍 “乐观协调” 模式。
分库分表 DDL 的问题(简略版)
本节首先以一个例子粗略介绍分库分表 DDL 对数据迁移的影响,然后就这个问题给出更加正式的定义。
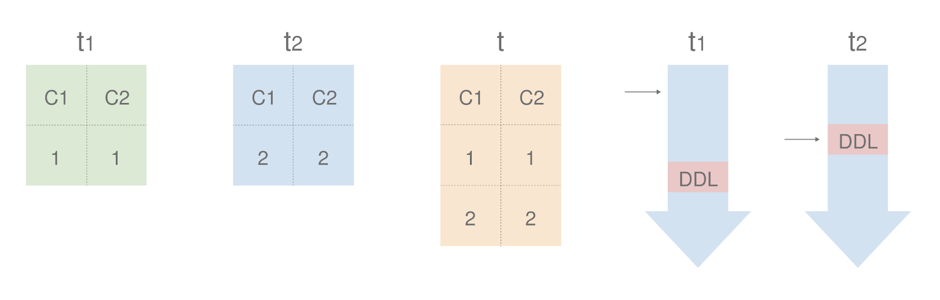
假设在两个上游有两个分表 t1、t2,下游表为 t。
![]()
t1 接下来的同步事件是 INSERT (3,3),t2 接下来的同步事件是 DROP COLUMN c2。如果 DROP COLUMN c2 先被同步到下游,在同步到 INSERT (3,3) 时就会因为缺少 c2 列而报错。
因此我们要对 DDL 同步事件进行特殊处理。
分库分表合并迁移的定义
接下来我们尝试使用更正式一点的语言来描述这个问题,从而引出如何正确解决这个问题。
从用户的角度来讲,数据库的用途主要的是查询,在分库分表合并前后,查询的结果应该是相同的(不考虑 LIMIT 等算子以及不确定性查询)。也就是说,各分表查询结果的并集应当等于迁移后的查询结果。容易得到一个满足此要求的充分条件:各分表数据的并集应当等于迁移后的表数据。考虑到同步延迟的影响,也就是当前时刻下游表的数据等于各分表在过去某时刻数据的并集。
对于这个定义而言,数据迁移就是让各分表的同步时刻不断向前推进。如果在同步某事件前,下游表与各分表满足定义,那么我们将一个分表的同步事件以相同影响的方式应用到下游,就将该分表的同步时刻正确地推进了。
分库分表 DDL 的问题(正式版)
从上面的定义来看,DDL 会造成两个方面的问题。
首先是 DDL 可能会变更表结构。参照之前的例子,如果 t1、t2 都有 DROP COLUMN c2 事件,DM 先同步到了 t2 的该事件,而同步事件需要以相同影响的方式应用到下游,我们应该只将下游 t2 对应的数据 DROP COLUMN。显然下游 t1、t2 的数据共享一个表结构,无法完成这个操作。因此 t2 的该事件暂时不能被同步。
另一个问题是,部分 DDL 即使不影响表结构,也会产生对数据产生影响。例如 ALTER TABLE DROP COLUMN c, ADD COLUMN c DEFAULT xx,会将一个分表的 c 列全部修改为 xx。目前 DM 的实现同样无法将这个事件以相同影响的方式应用到下游。
解决方法
对于上述 DDL 引入的问题并基于前文对于同步正确性的定义,我们可以得到一个满足要求的充分条件:当某分表出现 DDL 同步事件时,我们将其同步暂停;直到所有分表都出现该 DDL 同步事件时,我们将 DDL 应用到下游并恢复所有分表的同步。此时我们可以保证下游表的 DDL 产生的影响等于所有分表都进行了 DDL(不考虑非确定性 DDL,例如 DDL 新增列默认值为 current_timestamp)。
悲观协调例子
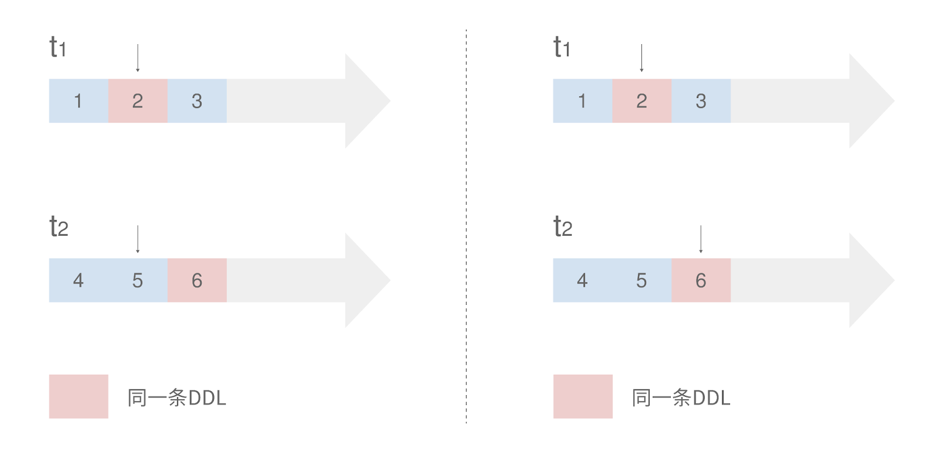
我们仍然以两张表 t1、t2 的合并迁移为例,观察 binlog 同步进度
![]()
左图中,当分表 t1 遇到 DDL 时,t2 同步事件还没有到这条 DDL,因此 t1 同步应当被暂停。当进展到右图时,t1、t2 分表都出现了相同的 DDL,因此此时可以将这条 DDL 应用到下游并恢复 t1、t2 的同步。
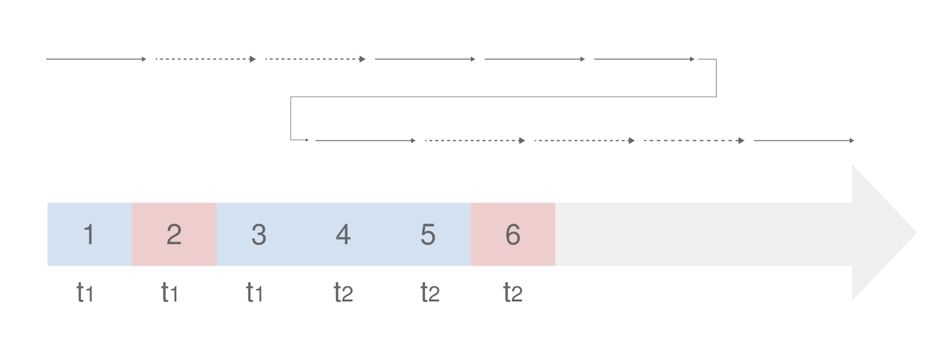
在某些情况下,t1、t2 可能位于一个 binlog 流之中,因此上图中看似独立的流的暂停与恢复,实际实现为在同一个 binlog 流中跳过事件及回滚同步位置。
![]()
如上图,我们需要在事件 1、2、4、5、6 之后同步事件 3,因此在 binlog 流中首次遇到事件 3 时跳过,并在事件 6 完成之后重新从事件 3 开始同步,并跳过已经同步的 4、5、6 事件。
悲观协调模式限制
可以看到这种协调模式解决方法有如下的限制:
因为悲观协调模式的种种限制,DM 也提供了新的乐观协调模式,我们将在后续的文章中具体介绍,希望大家能够在深入了解两种协调模式的原理和使用限制后,根据场景选择合适的模式进行分库分表的合并迁移。