Pokémon GO 也就是《精灵宝可梦》,任天堂和谷歌 Niantic Labs 合作开发的现实增强(AR)游戏,也是谷歌云罕见的支持的大型的游戏,就目前来看,Pokémon GO目前在线用户可以达到数百万人次,谷歌云平台是如何支持 Pokémon GO 容纳如此多的用户的呢?
Pokémon GO 的扩展
Pokémon GO 的扩展性主要是基于 Google Kubernetes Engine(谷歌云上的kubernetes的全面托管工具) 和 Cloud Spanner(全球分布式企业级数据库),前端服务托管在 GKE上,可以通过 GKE 这个托管平台轻松扩展结点,直接使用谷歌云平台上的管理k8s集群所需的工具。目前在流量庞大的时间点,会有数千个专门为 Pokémon GO 运行的 kubernetes 节点,以及运行有助于增强游戏体验的各种微服务的 GKE 节点,在特定时间支撑世界各地的数百万玩家,与其他大型多人在线游戏不同的是, Pokémon GO 上的游戏玩家共享一个“realm”,玩家可以相互交互并共享相同的游戏状态。
除了GKE外,谷歌云平台提供 Goggle Cloud Monitoring来搜索日志、构建仪表板,并在出现紧急情况时发出警报。同时还有大型用户数据库,在 Pokémon GO 刚发行的时候,使用的数据库为 Google Datastore,这是个简单的入门数据库,管理简单。随着游戏的成熟,团队开始使用 Cloud Spanner,方便扩展,且可以提供一致索引,允许团队使用带有主键和辅助键的更复杂的数据库架构,且 Cloud Spanner 是具有完全一致性的关系型数据库。
后台工作流向
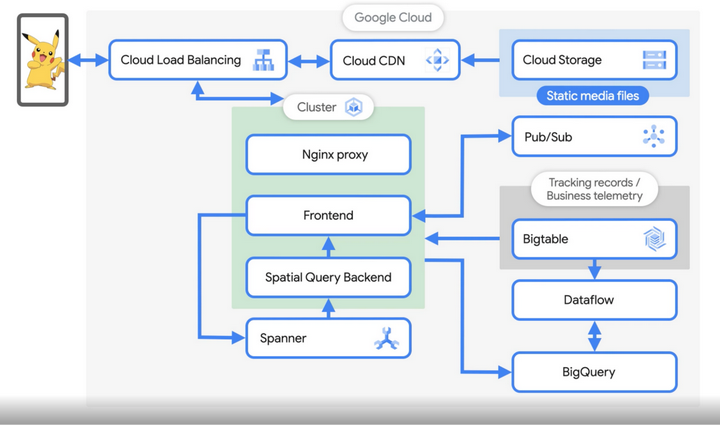
当一名用户打开 Pokémon GO 的时候,会通过 Cloud Load Balancing 收到用户请求,收到后存储在 Cloud Storage 中的所有静态媒体都会在应用程序第一次启动时下载到手机。同时 Cloud Load Balancing 会启用 Cloud CDN缓存和提供内容。当来自用户手机的流量到达 Global Load Balancer 后,将请求发送到 NGINX 反向代理,然后反向代理将流量发送到前端游戏服务。
集群中的第三个 pod 是空间查询后端。此服务保留按位置分片的缓存。然后,此缓存和服务决定地图上显示哪些 Pokémon、用户周围有哪些体育馆和 PokéStops、用户所在的时区,以及基本上任何其他基于位置的功能。前端管理玩家及其与游戏的交互,而空间查询后端处理地图。前端从空间查询后端作业中检索信息以发送回用户。
![]()
当用户捕捉到 Pokémon 的时候,会通过 API 从 GKE 前端向 Spanner 发送一个事件,从前端到 Spanner 的写入请求完成时,比如执行更新地图操作时,该请求会发送缓存更新并转发到空间查询后端。
Spanner最终是一致的:一旦接收到更新,空间数据就会在内存中更新,然后用于服务来自前端的请求,然后前端从空间查询后端检索信息并将其发送回用户。团队还将每个用户操作的 protobuf 表示写入Bigtable,以使用严格的保留策略记录和跟踪数据。我们还将消息从前端发布到用于分析管道的Pub/Sub主题。
通过前后端的输入和输出,实现了游戏在不同用户上的同步。
游戏数据分析管道
游戏用户每天生成 5-10TB 的数据,团队会将所有数据存储在 BigQuery 和 BigTable 中。数据科学团队会对这些游戏事件感兴趣,以分析玩家行为、验证诸如确保口袋妖怪的分布符合团队对给定事件的预期、营销报告等功能。
团队还使用 BigQuery - 它可扩展且完全托管,可以专注于分析和构建复杂的查询,而无需过多担心数据的结构或表的架构。用户想要查询的任何字段都以一种允许用户构建自己在整个团队中共享的各种仪表板、报告和图表的方式进行索引。
游戏团队使用 Dataflow 作为数据处理引擎,因此运行 Dataflow 批处理作业来处理存储在 Bigtable 中的玩家日志。 还有一些流媒体作业,用于检测作弊、寻找和响应不正确的玩家信号。
随着事务的增加,整个系统的负载也会增加,比如数据管道(pub sub、BigQuery Streaming 等)。Niantic SRE 团队唯一需要确保的是他们对这些事件有正确的配额,而且由于这些是托管服务,Niantic 团队的运营开销要少得多。
文章参考:Google Cloud Blog
11月4日Cloud Ace工程师将分享关于谷歌推出的Cloud Spanner——全球分布且强一致性的企业级数据库服务,欢迎各位报名参加。
![]()