![]()
Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处理引擎,也可以通过流处理的方式来读写Hive中的表,从而为实时数仓的应用和流批一体的落地实践奠定了坚实的基础。本文将以Flink1.12为例,介绍Flink集成Hive的另外一个非常重要的方面——Hive维表JOIN(Temporal Table Join)与Flink读写Hive表的方式。以下是全文,希望本文对你有所帮助。
Flink写入Hive表
Flink支持以批处理(Batch)和流处理(Streaming)的方式写入Hive表。当以批处理的方式写入Hive表时,只有当写入作业结束时,才可以看到写入的数据。批处理的方式写入支持append模式和overwrite模式。
批处理模式写入
向非分区表写入数据
- Flink SQL> use catalog myhive; -- 使用catalog
- Flink SQL> INSERT INTO users SELECT 2,'tom';
- Flink SQL> set execution.type=batch; -- 使用批处理模式
- Flink SQL> INSERT OVERWRITE users SELECT 2,'tom';
向分区表写入数据
- -- 向静态分区表写入数据
- Flink SQL> INSERT OVERWRITE myparttable PARTITION (my_type='type_1', my_date='2019-08-08') SELECT 'Tom', 25;
- -- 向动态分区表写入数据
- Flink SQL> INSERT OVERWRITE myparttable SELECT 'Tom', 25, 'type_1', '2019-08-08';
流处理模式写入
流式写入Hive表,不支持Insert overwrite 方式,否则报如下错误:
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Streaming mode not support overwrite.
下面的示例是将kafka的数据流式写入Hive的分区表
-- 使用流处理模式
Flink SQL> set execution.type=streaming;
-- 使用Hive方言
Flink SQL> SET table.sql-dialect=hive;
-- 创建一张Hive分区表
CREATE TABLE user_behavior_hive_tbl (
`user_id` BIGINT, -- 用户id
`item_id` BIGINT, -- 商品id
`cat_id` BIGINT, -- 品类id
`action` STRING, -- 用户行为
`province` INT, -- 用户所在的省份
`ts` BIGINT -- 用户行为发生的时间戳
) PARTITIONED BY (dt STRING,hr STRING,mi STRING) STORED AS parquet TBLPROPERTIES (
'partition.time-extractor.timestamp-pattern'='$dt $hr:$mi:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file'
);
-- 使用默认SQL方言
Flink SQL> SET table.sql-dialect=default;
-- 创建一张kafka数据源表
CREATE TABLE user_behavior (
`user_id` BIGINT, -- 用户id
`item_id` BIGINT, -- 商品id
`cat_id` BIGINT, -- 品类id
`action` STRING, -- 用户行为
`province` INT, -- 用户所在的省份
`ts` BIGINT, -- 用户行为发生的时间戳
`proctime` AS PROCTIME(), -- 通过计算列产生一个处理时间列
`eventTime` AS TO_TIMESTAMP(FROM_UNIXTIME(ts, 'yyyy-MM-dd HH:mm:ss')), -- 事件时间
WATERMARK FOR eventTime AS eventTime - INTERVAL '5' SECOND -- 定义watermark
) WITH (
'connector' = 'kafka', -- 使用 kafka connector
'topic' = 'user_behaviors', -- kafka主题
'scan.startup.mode' = 'earliest-offset', -- 偏移量
'properties.group.id' = 'group1', -- 消费者组
'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092',
'format' = 'json', -- 数据源格式为json
'json.fail-on-missing-field' = 'true',
'json.ignore-parse-errors' = 'false'
);
关于Hive表的一些属性解释:
partition.time-extractor.timestamp-pattern
- 默认值:(none)
- 解释:分区时间抽取器,与 DDL 中的分区字段保持一致,如果是按天分区,则可以是$dt,如果是按年(year)月(month)日(day)时(hour)进行分区,则该属性值为:$year-$month-$day $hour:00:00,如果是按天时进行分区,则该属性值为:$day $hour:00:00;
sink.partition-commit.trigger
- process-time:不需要时间提取器和水位线,当当前时间大于分区创建时间 + sink.partition-commit.delay 中定义的时间,提交分区;
- partition-time:需要 Source 表中定义 watermark,当 watermark > 提取到的分区时间 +sink.partition-commit.delay 中定义的时间,提交分区;
- 默认值:process-time
- 解释:分区触发器类型,可选 process-time 或partition-time。
sink.partition-commit.delay
- 默认值:0S
- 解释:分区提交的延时时间,如果是按天分区,则该属性的值为:1d,如果是按小时分区,则该属性值为1h;
sink.partition-commit.policy.kind
- metastore:添加分区的元数据信息,仅Hive表支持该值配置
- success-file:在表的存储路径下添加一个_SUCCESS文件
- 默认值:(none)
- 解释:提交分区的策略,用于通知下游的应用该分区已经完成了写入,也就是说该分区的数据可以被访问读取。可选的值如下:
可以同时配置上面的两个值,比如metastore,success-file
执行流式写入Hive表
-- streaming sql,将数据写入Hive表
INSERT INTO user_behavior_hive_tbl
SELECT
user_id,
item_id,
cat_id,
action,
province,
ts,
FROM_UNIXTIME(ts, 'yyyy-MM-dd'),
FROM_UNIXTIME(ts, 'HH'),
FROM_UNIXTIME(ts, 'mm')
FROM user_behavior;
-- batch sql,查询Hive表的分区数据
SELECT * FROM user_behavior_hive_tbl WHERE dt='2021-01-04' AND hr='16' AND mi = '46';
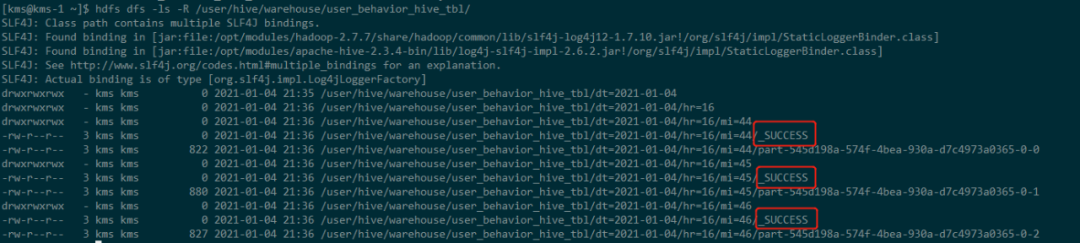
同时查看Hive表的分区数据:
![]()
![]()
尖叫提示:
-Flink读取Hive表默认使用的是batch模式,如果要使用流式读取Hive表,需要而外指定一些参数,见下文。
-只有在完成 Checkpoint 之后,文件才会从 In-progress 状态变成 Finish 状态,同时生成_SUCCESS文件,所以,Flink流式写入Hive表需要开启并配置 Checkpoint。对于Flink SQL Client而言,需要在flink-conf.yaml中开启CheckPoint,配置内容为:
state.backend: filesystem
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
execution.checkpointing.interval: 60s
execution.checkpointing.mode: EXACTLY_ONCE
state.savepoints.dir: hdfs://kms-1:8020/flink-savepoints
Flink读取Hive表
Flink支持以批处理(Batch)和流处理(Streaming)的方式读取Hive中的表。批处理的方式与Hive的本身查询类似,即只在提交查询的时刻查询一次Hive表。流处理的方式将会持续地监控Hive表,并且会增量地提取新的数据。默认情况下,Flink是以批处理的方式读取Hive表。
关于流式读取Hive表,Flink既支持分区表又支持非分区表。对于分区表而言,Flink将会监控新产生的分区数据,并以增量的方式读取这些数据。对于非分区表,Flink会监控Hive表存储路径文件夹里面的新文件,并以增量的方式读取新的数据。
Flink读取Hive表可以配置一下参数:
streaming-source.enable
- 默认值:false
- 解释:是否开启流式读取 Hive 表,默认不开启。
streaming-source.partition.include
- 默认值:all
- 解释:配置读取Hive的分区,包括两种方式:all和latest。all意味着读取所有分区的数据,latest表示只读取最新的分区数据。值得注意的是,latest方式只能用于开启了流式读取Hive表,并用于维表JOIN的场景。
streaming-source.monitor-interval
- 默认值:None
- 解释:持续监控Hive表分区或者文件的时间间隔。值得注意的是,当以流的方式读取Hive表时,该参数的默认值是1m,即1分钟。当temporal join时,默认的值是60m,即1小时。另外,该参数配置不宜过短 ,最短是1 个小时,因为目前的实现是每个 task 都会查询 metastore,高频的查可能会对metastore 产生过大的压力。
streaming-source.partition-order
- 默认值:partition-name
- 解释:streaming source的分区顺序。默认的是partition-name,表示使用默认分区名称顺序加载最新分区,也是推荐使用的方式。除此之外还有两种方式,分别为:create-time和partition-time。其中create-time表示使用分区文件创建时间顺序。partition-time表示使用分区时间顺序。指的注意的是,对于非分区表,该参数的默认值为:create-time。
streaming-source.consume-start-offset
- 默认值:None
- 解释:流式读取Hive表的起始偏移量。
- partition.time-extractor.kind
- 默认值:default
- 分区时间提取器类型。用于从分区中提取时间,支持default和自定义。如果使用default,则需要通过参数partition.time-extractor.timestamp-pattern配置时间戳提取的正则表达式。
- 在 SQL Client 中需要显示地开启 SQL Hint 功能
Flink SQL> set table.dynamic-table-options.enabled= true;
使用SQLHint流式查询Hive表
SELECT * FROM user_behavior_hive_tbl /*+ OPTIONS('streaming-source.enable'='true', 'streaming-source.consume-start-offset'='2021-01-03') */;
Hive维表JOIN
Flink 1.12 支持了 Hive 最新的分区作为时态表的功能,可以通过 SQL 的方式直接关联 Hive 分区表的最新分区,并且会自动监听最新的 Hive 分区,当监控到新的分区后,会自动地做维表数据的全量替换。
Flink支持的是processing-time的temporal join,也就是说总是与最新版本的时态表进行JOIN。另外,Flink既支持非分区表的temporal join,又支持分区表的temporal join。对于分区表而言,Flink会监听Hive表的最新分区数据。值得注意的是,Flink尚不支持 event-time temporal join。
Temporal Join最新分区
对于一张随着时间变化的Hive分区表,Flink可以读取该表的数据作为一个无界流。如果Hive分区表的每个分区都包含全量的数据,那么每个分区将做为一个时态表的版本数据,即将最新的分区数据作为一个全量维表数据。值得注意的是,该功能特点仅支持Flink的STREAMING模式。
使用 Hive 最新分区作为 Tempmoral table 之前,需要设置必要的两个参数:
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest'
除此之外还有一些其他的参数,关于参数的解释见上面的分析。我们在使用Hive维表的时候,既可以在创建Hive表时指定具体的参数,也可以使用SQL Hint的方式动态指定参数。一个Hive维表的创建模板如下:
-- 使用Hive的sql方言
SET table.sql-dialect=hive;
CREATE TABLE dimension_table (
product_id STRING,
product_name STRING,
unit_price DECIMAL(10, 4),
pv_count BIGINT,
like_count BIGINT,
comment_count BIGINT,
update_time TIMESTAMP(3),
update_user STRING,
...
) PARTITIONED BY (pt_year STRING, pt_month STRING, pt_day STRING) TBLPROPERTIES (
-- 方式1:按照分区名排序来识别最新分区(推荐使用该种方式)
'streaming-source.enable' = 'true', -- 开启Streaming source
'streaming-source.partition.include' = 'latest',-- 选择最新分区
'streaming-source.monitor-interval' = '12 h',-- 每12小时加载一次最新分区数据
'streaming-source.partition-order' = 'partition-name', -- 按照分区名排序
-- 方式2:分区文件的创建时间排序来识别最新分区
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.partition-order' = 'create-time',-- 分区文件的创建时间排序
'streaming-source.monitor-interval' = '12 h'
-- 方式3:按照分区时间排序来识别最新分区
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '12 h',
'streaming-source.partition-order' = 'partition-time', -- 按照分区时间排序
'partition.time-extractor.kind' = 'default',
'partition.time-extractor.timestamp-pattern' = '$pt_year-$pt_month-$pt_day 00:00:00'
);
有了上面的Hive维表,我们就可以使用该维表与Kafka的实时流数据进行JOIN,得到相应的宽表数据。
-- 使用default sql方言
SET table.sql-dialect=default;
-- kafka实时流数据表
CREATE TABLE orders_table (
order_id STRING,
order_amount DOUBLE,
product_id STRING,
log_ts TIMESTAMP(3),
proctime as PROCTIME()
) WITH (...);
-- 将流表与hive最新分区数据关联
SELECT *
FROM orders_table AS orders
JOIN dimension_table FOR SYSTEM_TIME AS OF orders.proctime AS dim
ON orders.product_id = dim.product_id;
除了在定义Hive维表时指定相关的参数,我们还可以通过SQL Hint的方式动态指定相关的参数,具体方式如下:
SELECT *
FROM orders_table AS orders
JOIN dimension_table
/*+ OPTIONS('streaming-source.enable'='true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '1 h',
'streaming-source.partition-order' = 'partition-name') */
FOR SYSTEM_TIME AS OF orders.proctime AS dim -- 时态表(维表)
ON orders.product_id = dim.product_id;
Temporal Join最新表
对于Hive的非分区表,当使用temporal join时,整个Hive表会被缓存到Slot内存中,然后根据流中的数据对应的key与其进行匹配。使用最新的Hive表进行temporal join不需要进行额外的配置,我们只需要配置一个Hive表缓存的TTL时间,该时间的作用是:当缓存过期时,就会重新扫描Hive表并加载最新的数据。
lookup.join.cache.ttl
尖叫提示:
- 当使用此种方式时,Hive表必须是有界的lookup表,即非Streaming Source的时态表,换句话说,该表的属性streaming-source.enable = false。
- 如果要使用Streaming Source的时态表,记得配置streaming-source.monitor-interval的值,即数据更新的时间间隔。
默认值:60min
解释:表示缓存时间。由于 Hive 维表会把维表所有数据缓存在 TM 的内存中,当维表数据量很大时,很容易造成 OOM。当然TTL的时间也不能太短,因为会频繁地加载数据,从而影响性能。
-- Hive维表数据使用批处理的方式按天装载
SET table.sql-dialect=hive;
CREATE TABLE dimension_table (
product_id STRING,
product_name STRING,
unit_price DECIMAL(10, 4),
pv_count BIGINT,
like_count BIGINT,
comment_count BIGINT,
update_time TIMESTAMP(3),
update_user STRING,
...
) TBLPROPERTIES (
'streaming-source.enable' = 'false', -- 关闭streaming source
'streaming-source.partition.include' = 'all', -- 读取所有数据
'lookup.join.cache.ttl' = '12 h'
);
-- kafka事实表
SET table.sql-dialect=default;
CREATE TABLE orders_table (
order_id STRING,
order_amount DOUBLE,
product_id STRING,
log_ts TIMESTAMP(3),
proctime as PROCTIME()
) WITH (...);
-- Hive维表join,Flink会加载该维表的所有数据到内存中
SELECT *
FROM orders_table AS orders
JOIN dimension_table FOR SYSTEM_TIME AS OF orders.proctime AS dim
ON orders.product_id = dim.product_id;
尖叫提示:
-每一个子任务都需要缓存一份维表的全量数据,一定要确保TM的task Slot 大小能够容纳维表的数据量;
-推荐将streaming-source.monitor-interval和lookup.join.cache.ttl的值设为一个较大的数,因为频繁的更新和加载数据会影响性能。
-当缓存的维表数据需要重新刷新时,目前的做法是将整个表进行加载,因此不能够将新数据与旧数据区分开来。
Hive维表JOIN示例
假设维表的数据是通过批处理的方式(比如每天)装载至Hive中,而Kafka中的事实流数据需要与该维表进行JOIN,从而构建一个宽表数据,这个时候就可以使用Hive的维表JOIN。
创建一张kafka数据源表,实时流
SET table.sql-dialect=default;
CREATE TABLE fact_user_behavior (
`user_id` BIGINT, -- 用户id
`item_id` BIGINT, -- 商品id
`action` STRING, -- 用户行为
`province` INT, -- 用户所在的省份
`ts` BIGINT, -- 用户行为发生的时间戳
`proctime` AS PROCTIME(), -- 通过计算列产生一个处理时间列
`eventTime` AS TO_TIMESTAMP(FROM_UNIXTIME(ts, 'yyyy-MM-dd HH:mm:ss')), -- 事件时间
WATERMARK FOR eventTime AS eventTime - INTERVAL '5' SECOND -- 定义watermark
) WITH (
'connector' = 'kafka', -- 使用 kafka connector
'topic' = 'user_behaviors', -- kafka主题
'scan.startup.mode' = 'earliest-offset', -- 偏移量
'properties.group.id' = 'group1', -- 消费者组
'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092',
'format' = 'json', -- 数据源格式为json
'json.fail-on-missing-field' = 'true',
'json.ignore-parse-errors' = 'false'
);
创建一张Hive维表
SET table.sql-dialect=hive;
CREATE TABLE dim_item (
item_id BIGINT,
item_name STRING,
unit_price DECIMAL(10, 4)
) PARTITIONED BY (dt STRING) TBLPROPERTIES (
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '12 h',
'streaming-source.partition-order' = 'partition-name'
);
关联Hive维表的最新数据
SELECT
fact.item_id,
dim.item_name,
count(*) AS buy_cnt
FROM fact_user_behavior AS fact
LEFT JOIN dim_item FOR SYSTEM_TIME AS OF fact.proctime AS dim
ON fact.item_id = dim.item_id
WHERE fact.action = 'buy'
GROUP BY fact.item_id,dim.item_name;
使用SQL Hint方式,关联非分区的Hive维表:
set table.dynamic-table-options.enabled= true;
SELECT
fact.item_id,
dim.item_name,
count(*) AS buy_cnt
FROM fact_user_behavior AS fact
LEFT JOIN dim_item1
/*+ OPTIONS('streaming-source.enable'='false',
'streaming-source.partition.include' = 'all',
'lookup.join.cache.ttl' = '12 h') */
FOR SYSTEM_TIME AS OF fact.proctime AS dim
ON fact.item_id = dim.item_id
WHERE fact.action = 'buy'
GROUP BY fact.item_id,dim.item_name;
总结
本文以最新版本的Flink1.12为例,介绍了Flink读写Hive的不同方式,并对每种方式给出了相应的使用示例。在实际应用中,通常有将实时数据流与 Hive 维表 join 来构造宽表的需求,Flink提供了Hive维表JOIN,可以简化用户使用的复杂度。本文在最后详细说明了Flink进行Hive维表JOIN的基本步骤以及使用示例,希望对你有所帮助。
![]()