前提回顾
经过了之前的【Kafka技术专题系列(上)】和【Kafka技术专题系列(中)】的学习,相信您对Kafka的基本原理应该已经有了一个简单的介绍和认识了,接下来需要对总体做个收尾。下篇结束之后,我会对Kafka所有相关的技术板块做细化,做每一个技术板块做深入和扩展。
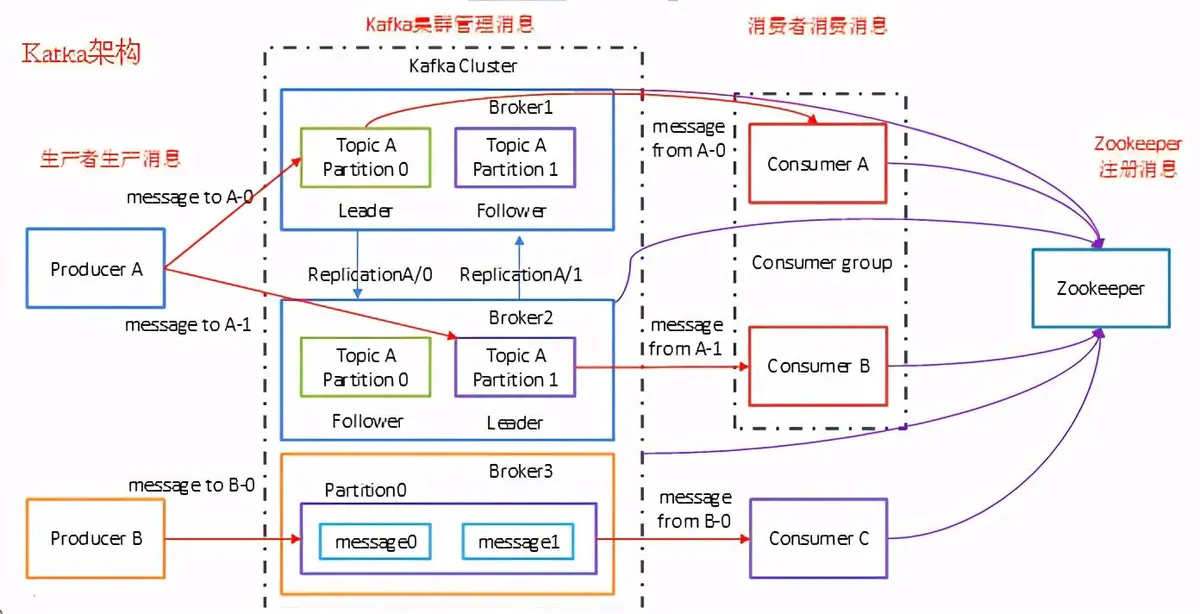
总体架构
![]()
核心优势
kafka被设计成通用的数据流处理平台,日志收集器和消息队列。
-
高吞吐(日志聚合):
-
大型数据块的整合(offline 平台的拉取)
-
低延迟(消息队列)
-
分区、分布式的实时流处理,从一个流派生新的流;
-
容错(当被投喂非日志数据时)
为了支持这些特性,一系列组件被开发,使得kafka更像是一个DB的日志收集系统,而不是消息队列。
持久性
选择用文件系统,而不是把日志存进进程的缓存再统一flush,有以下理由:
最重要的是,这里和数据量的大小不再有关系。因此,kafka可以将消息持久化保持7天,以供重复读。
效率
由于消费是规模最大的操作,所以我们要尽可能把消费做的“轻”。
disk efficiency
类似系统问题主要在两方面:I/O操作太多+Bytes过度拷贝。
-
I/O操作太多,kafka的解决方案是利用消息组的抽象概念,用大块的消息读写(生产/消费)来均摊网络代价。
-
Bytes过度拷贝问题,kafka让producer, comsumer, broker采用同样的序列化协议,开辟了优化空间,然后利用Sendfile系统调用减少Copy。
End-to-end Batch Compression
-
保证传输效率的另一点就是压缩。
-
kafka支持批压缩,主要因为不同log之间经常会产生大量的重复。
-
相比于端上的单条日志压缩,可以有更好的压缩比。
-
压缩的消息会被写入磁盘,会被发送给Consumer,最终由消费者解压缩。
-
支持的压缩方案有GZIP, Snappy, LZ4 and ZStandard等。
Producer(生产者)
负载均衡
异步发送
- 批量发送,可配置的定时/定量进行buffer batch send。
Consumer(消费者)
Push vs. pull
-
push-fashion的系统,比如flume,难点在于对于多个消费者,没有办法根据消费者的接收能力控制消费速度。
-
pull-fashion在这点要灵活的多。
- 可以由consumer主动去进行批量拉取(用户配置),而不是靠broker猜测。
- 如果broker暂时没数据,consumer不会忙等,会把自己阻塞掉,定期轮询。
Consumer Position
Offline Data Load
Static Memebership
消息传递语义
- 在kafka中,日志是有提交的概念的,如果日志提交了,只要复制了这个分区的broker有一个活着的,日志就还在。
- 假设broker本身不会丢失数据,以便理解对producer/consumer的消息传递保证。
Producer Delivery
对于producer来说,如果出现网络错误,是没法知道传输的日志是否已经提交了。
-
在0.11.0版本以前,如果没有收到ack,那么没有别的办法,只能重传,这实际上就是至少一次的语义。
-
在0.11.0版本之后,kafka为每个消息提供了Sequence number,为每个producer分发id,这样broker的接收操作,可以设置为幂等的,就完成了对producer的确切一次的语义。
-
而且也是从0.11.0开始,producer对多个topic partitions发送数据也可以保证事务性,要么全部接收,要么全都没接收。
-
具体到使用的时候,producer可以根据消息类型自主选择持久化级别。log信息可以完全异步发送,当有重要数据时也可以选择有回调函数的Send,等待commit时block掉,commit的级别也可以设置,是leader收到即可或者需要多少个follower副本。一般来说,同步的Send在10ms这个级别。
Consumer Delivery
-
由于上面我们说,producer可以对多个topic partitions进行事务性的写。
-
这给kafka的一个场景带来了极大的便利:流处理。流处理就是通过一个topic经过一些变换产出到另一个topic中去,整个过程都在kafka集群中完成。
-
我们把两条消息组成一个事务:转换后的消息+消费的offset。利用producer的事务写,要么offset和数据同时写入,要么同时没有被写入,这就达成了消费端的确切一次语义。
-
如果事务中途abort掉了,对于consumer有两种可见性,取决于consumer的隔离性级别
上面说的是流处理的过程是可以达成确切一次语义。
对于consumer来自外部系统呢?
麻烦在于要把消费者的位置和实际消费的日志同步起来,一个通用的做法是进行两阶段提交(编者注:kafka集群作为coordinator,每一个consumer作为一个worker)。
然而很多外部系统(比如HDFS)并不支持两阶段提交。因此只能用一个更轻型也更通用的方案,让每一个consumer把自己的offset和实际数据放在同一个位置。有一点不妙的是,由于此时的消息没有主键,因此也无法进行去重(编者注:offset不可以作为消息的主键么?)。最终支持的是至少一次语义。
Replication
kafka判定节点是否alive有两个条件:
- 是否和zookeeper的session心跳保持联系;
- 是否和leader落后在一定范围内(用户参数)。
producer可以在持久性和吞吐率之间做权衡。可以设置mininum replica must write
producer有几个选择:
1 完全不需要ack 0
2 需要ack,但只要leader的就可以。1
3 需要ack,要至少mininum副本写入(minimum ISR)。 -1
对于2.3 这两种选择,可能只有leader写了日志,然后就被消费了。
因此kafka的保障是:对于提交的消息,只要有一个副本活着,就不会丢失。
kafka对于节点短时间宕机恢复有容错保障,但是对网络分区就不再保证可用了。
Replicated Logs: Quorums, ISRs, and State Machines (Oh my!)
-
kafka采用的是replicated log模型,即消息由leader定序,Follower无脑copy即可。
-
如果leader宕机掉了,就要在ISR中启动多数选举。(Raft, Paxos等),最接近kafka的是MS的PacificA。
-
对于宕机恢复的节点,kafka不要求它的数据完全一致,但是在加入ISR之前,它的数据必须得到全量的恢复。
trade-off between availability and duribility
上面说过producer有三种选择,对于第三种选择,即最小ISR基数,存在一个trade-off。
这里存在一个权衡,要用户把握。
Replica Management
kafka用round-robin的方式保证某个topic的partitions不会聚集在少量的节点中。
同样,也会用同样的方式保证leaders不会聚集在少量节点中。
另一方面,一般kafka由节点挂掉,是broker直接挂掉,不会是某个partition挂掉,那么一个broker挂掉,可能会触发几个甚至几十个partition的重新选举/rebalance。
此时kafka的策略是选择另外一个broker,在更高的级别上领导这些partition的leader选举,这样使得选举过程可以批量化,更为高效。
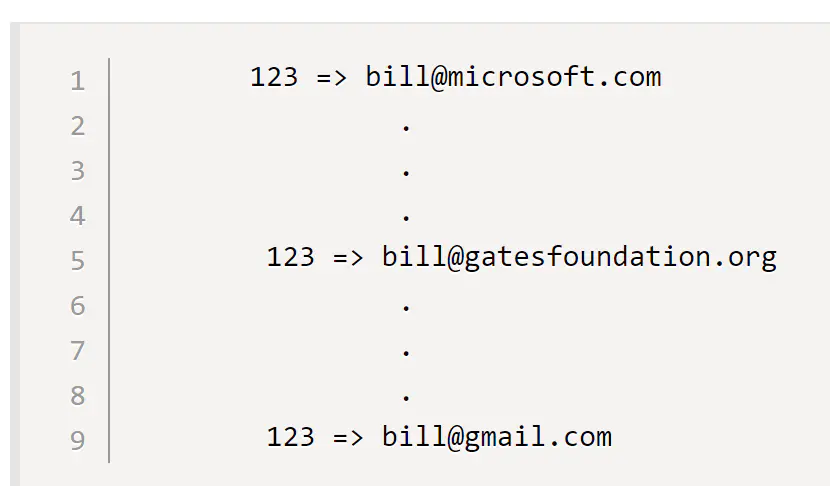
Log Compaction
kafka log压缩保证在一个topic partition内,在消息内部每个key的最新值都会被保留下来。这意味着在任意时刻,我们能拿到当前各个key的最新快照。这在一些事务型的日志中非常重要,可以用于下游的数据恢复。 比如下图这三次更改中,只有最后一条记录不会被压缩。
![]()
这样的话其实就产生了两种保留策略,一种是默认的按照时间(7天)或者大小来保留;另一种是按照压缩来保留。
Log Compaction Basics
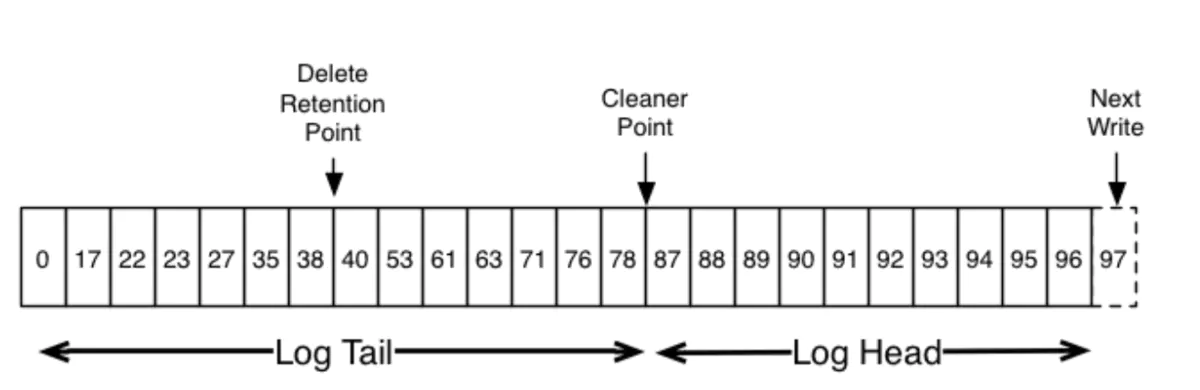
这是一个kafka log的逻辑视图。
![]()
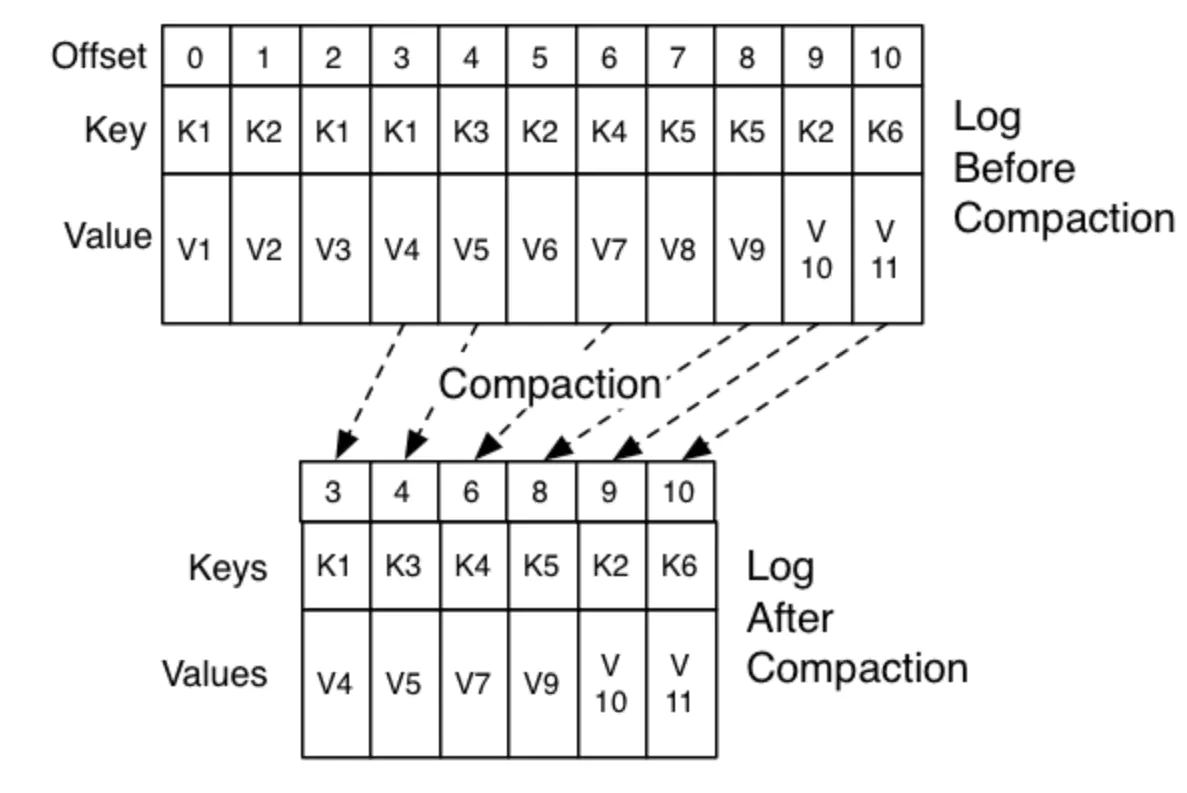
真实的log compaction大概是这个样子的。offset即使被压缩也永远不会变,以免含义混淆。
![]()
对于log compaction,kafka给出了一些保证: 消息会在一个可配置的时间之后才会进入log尾,可压缩;也就是说,如果一直在监听消费的consumer可以收到连续offset的消息,不会立即被压缩;
消息的顺序不会被打乱,只是有些消息就被删除了; 消息的offset不变;
Log Compaction Details
log compaction是由一个后台的线程池log cleaner来做的,不会block前台的produce/consume。同时也有一个用户参数来限制compaction的I/O带宽占用。一次log clean包含以下四步:
选择最大的比例:log head/log tail 用一个哈希表对log head中的每个key进行存储 从头到尾重新copy数据到一个新的位置,那些老keys会被直接删除,新的位置写满了1个segment file就会copy回去,所以只会有1个Segment file的额外空间占用。
Quota
这个是kafka在消费组/消费者之间的调度系统,放止某些消费者故意捣乱频繁拉取数据,占据了大量broker的资源而产生的。可以按照带宽/请求量进行分配,这里偏运维不细说,遇到再补充。
接下来,将要进行相关的各个部分的详细介绍。