部署 完全分布式高可用 Hadoop hdfs HA + yarn HA
标签(空格分隔): 大数据运维专栏
- 一:hadoop HDFS HA 与 yarn HA 的 概述
- 二:部署环境概述
- 三:部署zookeeper
- 四:部署HDFS HA 与 yarn HA
- 五:关于 HA 的测试
一:hadoop HDFS HA 与 yarn HA 的 概述
1.1 HA 的概述
HA概述
1)所谓HA(High Available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4)NameNode主要在以下两个方面影响HDFS集群:
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
HDFS HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
1.2 HDFS-HA 的工作机制
HDFS-HA工作机制
通过双NameNode消除单点故障。
HDFS-HA工作要点
1、元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现)。
2、需要一个状态管理功能模块
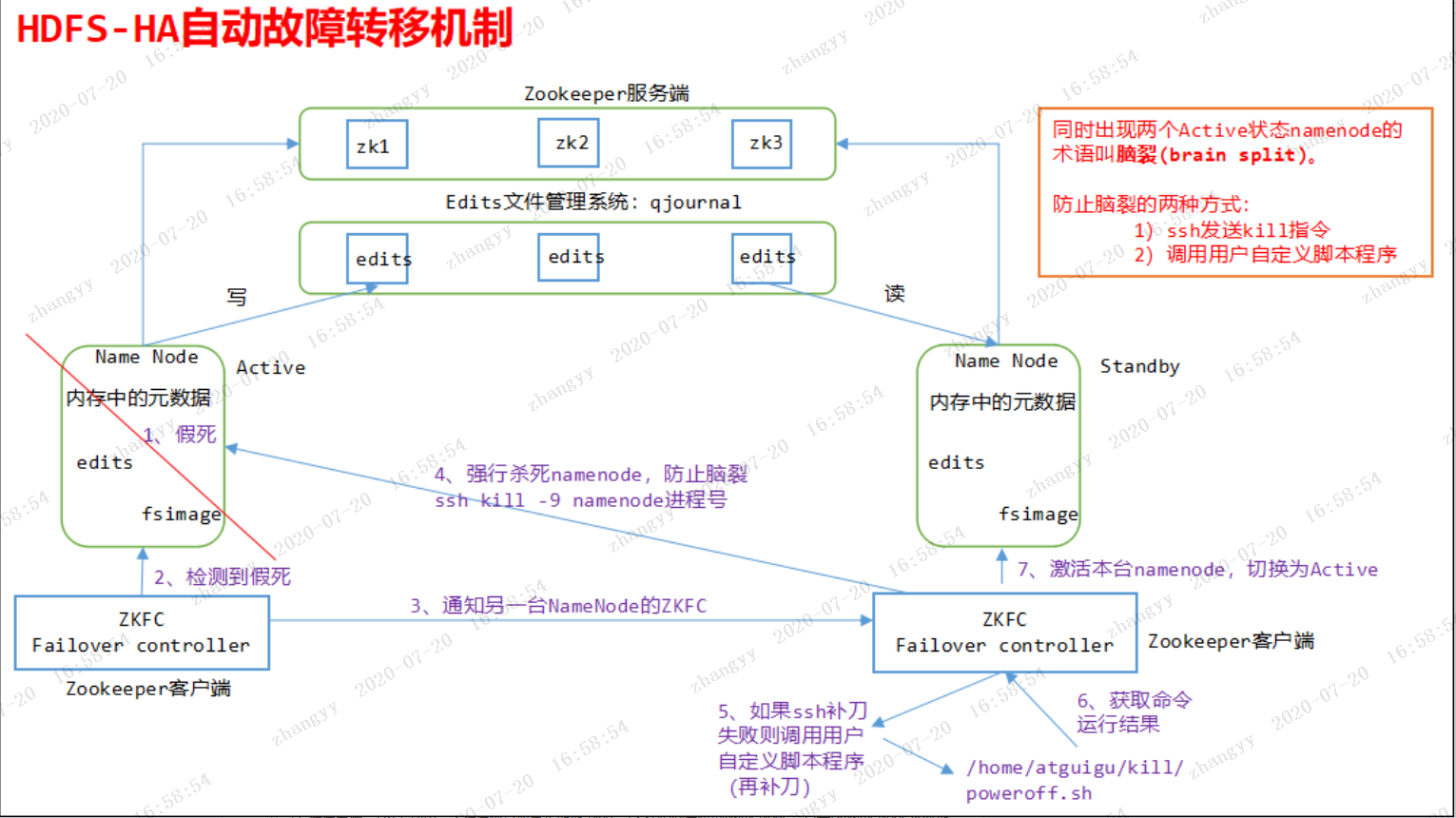
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split(脑裂)现象的发生。
3、必须保证两个NameNode之间能够ssh无密码登录。
4、隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务。
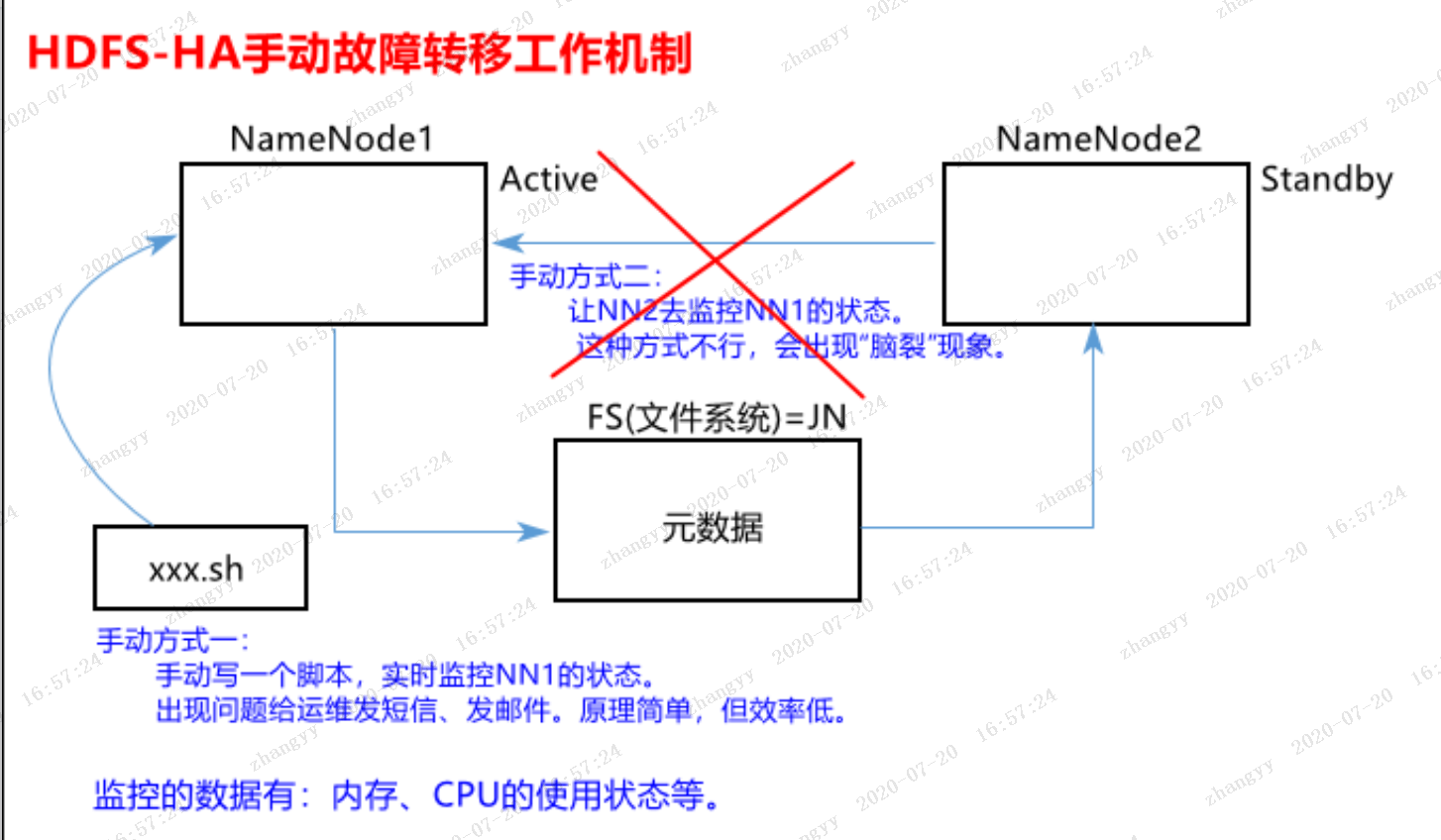
1.3 HDFS-HA手动故障转移工作机制
![图片.png-262.7kB]()
1.4 HDFS-HA自动故障转移工作机制
![图片.png-288.6kB]()
二: 部署环境概述
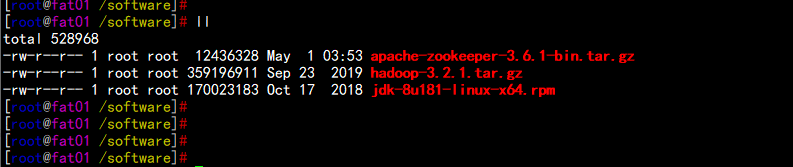
2.1:所需安装配置包
1. 系统:CentOS 7.5 X64
2. 软件:Hadoop-3.2.1.tar.gz
apache-zookeeper-3.6.1-bin.tar.gz
jdk-8u181-linux-x64.rpm
将所有软件安装上传到/software下面
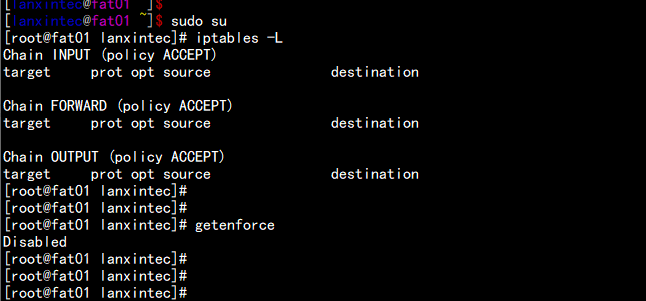
3. 系统关闭SELINUX 与清空iptables 防火墙规则
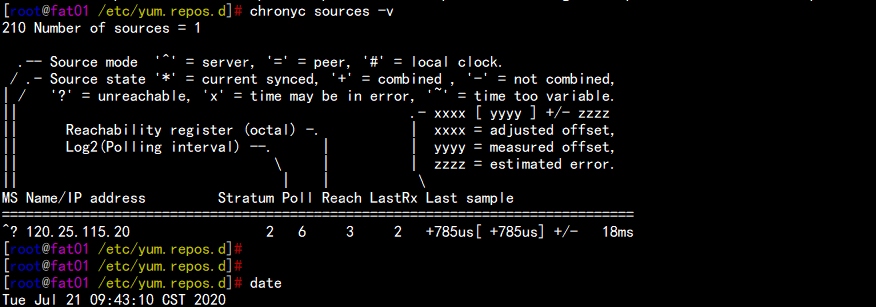
4. 系统配置好 时间同步服务器
ntp1.aliyun.com
![图片.png-16.1kB]()
![图片.png-19.3kB]()
![图片.png-25.2kB]()
三:部署zookeeper
fat01.flyfish.com 节点操作
tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz
mv apache-zookeeper-3.6.1-bin /opt/bigdata/zookeeper
cd /opt/bigdata/zookeeper/conf
cp -p zoo_sample.cfg zoo.cfg
vim zoo.cfg
-----
dataDir=/opt/bigdata/zookeeper/data/
server.1=fat01.flyfish.com:2888:3888
server.2=fat02.flyfish.com:2888:3888
server.3=fat03.flyfish.com:2888:3888
----
mkdir -p /opt/bigdata/zookeeper/data/
echo "1" > /opt/bigdata/zookeeper/data/myid
打包zookeeper 目录
cd /opt/bigdata/
tar -zcvf zookeeper.tar.gz zookeeper
scp zookeeper.tar.gz root@192.168.11.195:/opt/bigdata/
scp zookeeper.tar.gz root@192.168.11.197:/opt/bigdata/
fat02.flyfish.com 节点操作
cd /opt/bigdata/
tar -zxvf zookeeper.tar.gz
echo 2 > /opt/bigdata/zookeeper/data/myid
fat03.flyfish.com 节点操作
cd /opt/bigdata/
tar -zxvf zookeeper.tar.gz
echo 3 > /opt/bigdata/zookeeper/data/myid
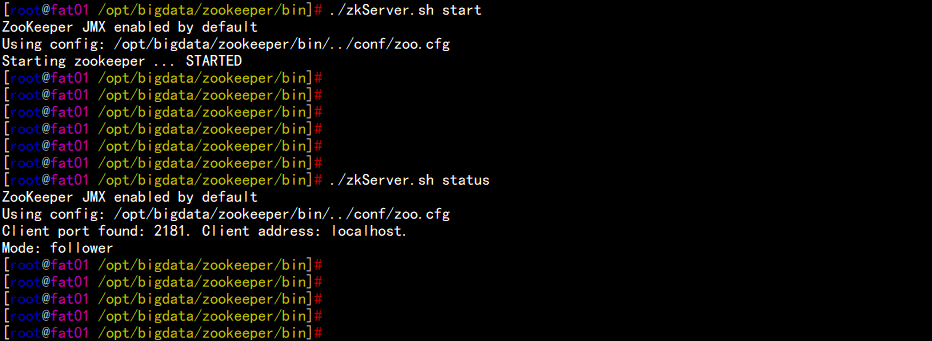
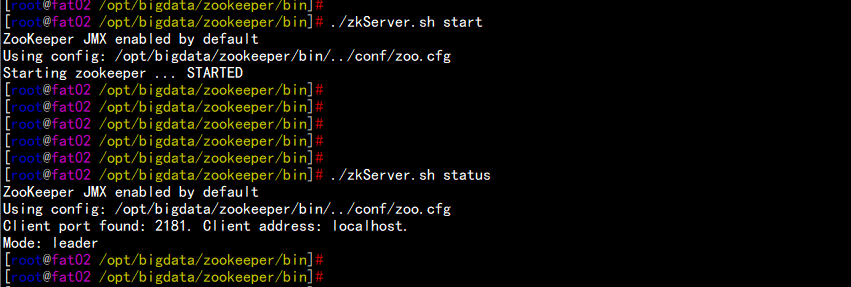
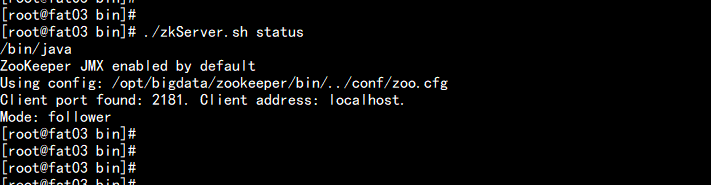
启动所有节点的zookeeper
cd /opt/bigdata/zookeeper/bin
./zkstart.sh
![图片.png-37.7kB]()
![图片.png-31.4kB]()
![图片.png-12.9kB]()
四:部署HDFS HA 与 yarn HA
4.1 部署解压Hadoop
tar –zxvf hadoop-3.2.1.tar.gz
mv hadoop-3.2.1 /opt/bigdata/hadoop/
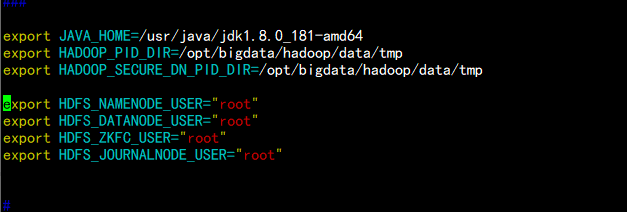
4.2 编辑Hadoop-env.sh 配置文件
vim hadoop-env.sh
---
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export HADOOP_PID_DIR=/opt/bigdata/hadoop/data/tmp
export HADOOP_SECURE_DN_PID_DIR=/opt/bigdata/hadoop/data/tmp
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_ZKFC_USER="root"
export HDFS_JOURNALNODE_USER="root"
----
![图片.png-12.7kB]()
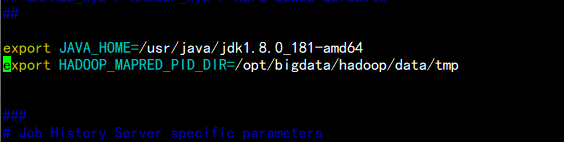
vim mapred-env.sh
增加jdk 的环境
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export HADOOP_MAPRED_PID_DIR=/opt/bigdata/hadoop/data/tmp
-----
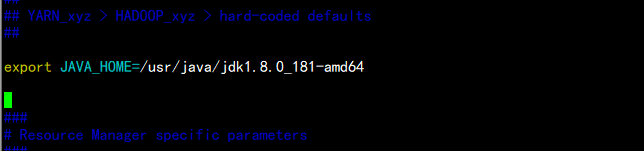
vim yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
![图片.png-6.7kB]()
![图片.png-5.8kB]()
4.3 编辑core-site.xml 文件
cd /opt/bigdata/hadoop/etc/hadoop
vim core-site.xml
---
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://myNameService1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/bigdata/hadoop/data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>fat01.flyfish.com:2181,fat02.flyfish.com:2181,fat03.flyfish.com:2181</value>
</property>
</configuration>
----
4.4 编辑 hdfs-site.xml
vim hdfs-site.xml
----
<configuration>
<!--指定hdfs的nameservice为myNameService1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>myNameService1</value>
</property>
<!-- myNameService1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myNameService1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myNameService1.nn1</name>
<value>fat01.flyfish.com:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myNameService1.nn1</name>
<value>fat01.flyfish.com:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myNameService1.nn2</name>
<value>fat02.flyfish.com:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.myNameService1.nn2</name>
<value>fat02.flyfish.com:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://fat01.flyfish.com:8485;fat02.flyfish.com:8485;fat03.flyfish.com:8485/myNameService1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/bigdata/hadoop/data/jn</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.myNameService1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,Failover后防止停掉的Namenode启动,造成两个服务,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆,注意换成自己的用户名 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/bigdata/hadoop/data/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/bigdata/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
-----
4.5 编辑 yarn-site.xml
vim yarn-site.xml
----
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>fat01.flyfish.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>fat02.flyfish.com</value>
</property>
<!-- RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>fat01.flyfish.com:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>fat02.flyfish.com:8088</value>
</property>
<!-- 指定zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>fat01.flyfish.com:2181,fat02.flyfish.com:2181,fat03.flyfish.com:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/bigdata/hadoop/etc/hadoop:/opt/bigdata/hadoop/share/hadoop/common/lib/*:/opt/bigdata/hadoop/share/hadoop/common/*:/opt/bigdata/hadoop/share/hadoop/hdfs:/opt/bigdata/hadoop/share/hadoop/hdfs/lib/*:/opt/bigdata/hadoop/share/hadoop/hdfs/*:/opt/bigdata/hadoop/share/hadoop/mapreduce/lib/*:/opt/bigdata/hadoop/share/hadoop/mapreduce/*:/opt/bigdata/hadoop/share/hadoop/yarn:/opt/bigdata/hadoop/share/hadoop/yarn/lib/*:/opt/bigdata/hadoop/share/hadoop/yarn/*</value>
</property>
</configuration>
-----
4.5 编辑 mapred-site.xml
vim mapred-site.xml
-----
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>fat01.flyfish.com:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>fat01.flyfish.com:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/bigdata/hadoop/share/hadoop/mapreduce/*,/opt/bigdata/hadoop/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
-----
4.6 修改works 文件
fat01.flyfish.com
fat02.flyfish.com
fat03.flyfish.com
4.8 打包 同步所有节点
fat01.flyfish.com 节点:
cd /opt/bigdata/
tar -zcvf hadoop.tar.gz hadoop
scp hadoop.tar.gz root@192.168.11.195:/opt/bigdata/
scp hadoop.tar.gz root@192.168.11.197:/opt/bigdata/
fat02.flyfish.com 节点:
cd /opt/bigdata/
tar -zxvf hadoop.tar.gz
fat03.flyfish.com 节点操作
cd /opt/bigdata/
tar -zxvf hadoop.tar.gz
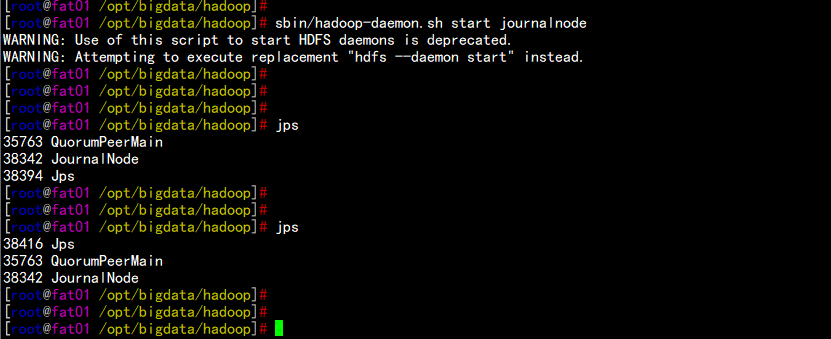
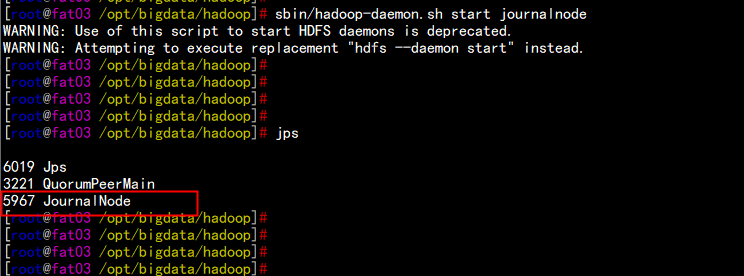
4.9 启动所有节点的journalnode服务
cd /opt/bigdata/hadoop/
sbin/hadoop-daemon.sh start journalnode
![图片.png-32.6kB]()
![图片.png-16.1kB]()
![图片.png-26.8kB]()
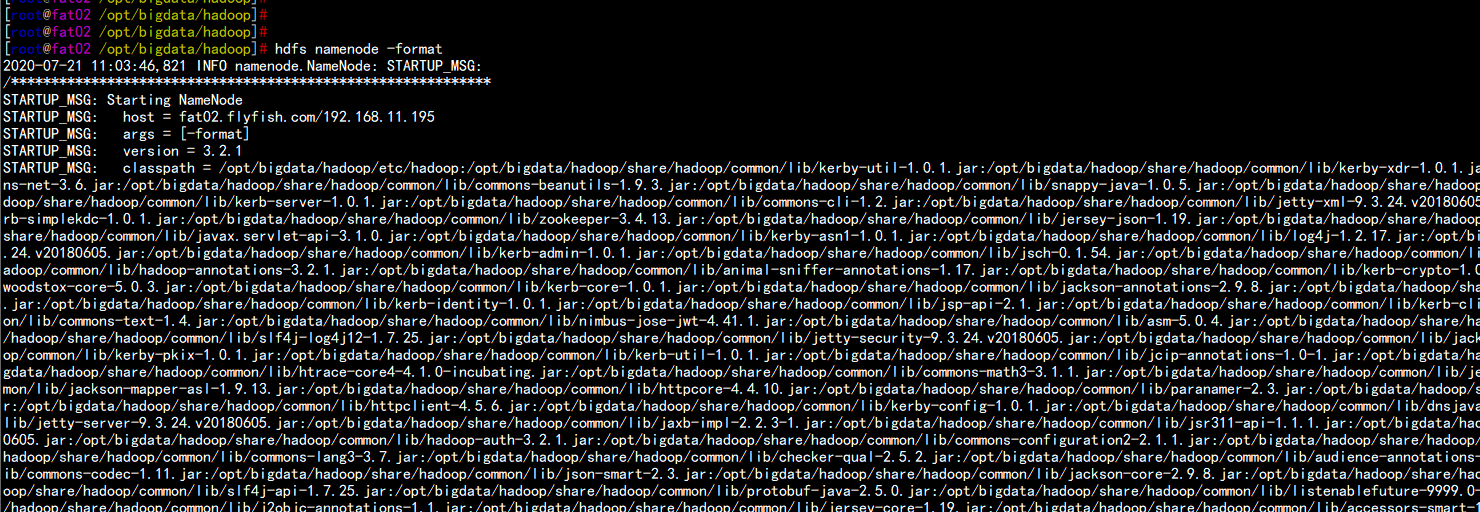
4.10 启动namenode 节点的HDFS
格式化hdfs
hdfs namenode -format
![图片.png-91.4kB]()
![图片.png-50.3kB]()
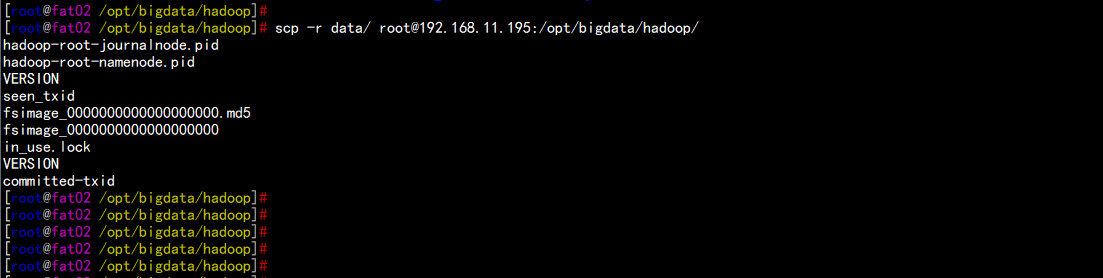
将fat01.flyfish.com上生成的data文件夹复制到fat02.flyfish.com的相同目录下
cd /opt/bigdata/hadoop/
scp -r data/ root@192.168.11.195:/opt/bigdata/hadoop/
启动namenode
hdfs --daemon start namenode
![图片.png-22.1kB]()
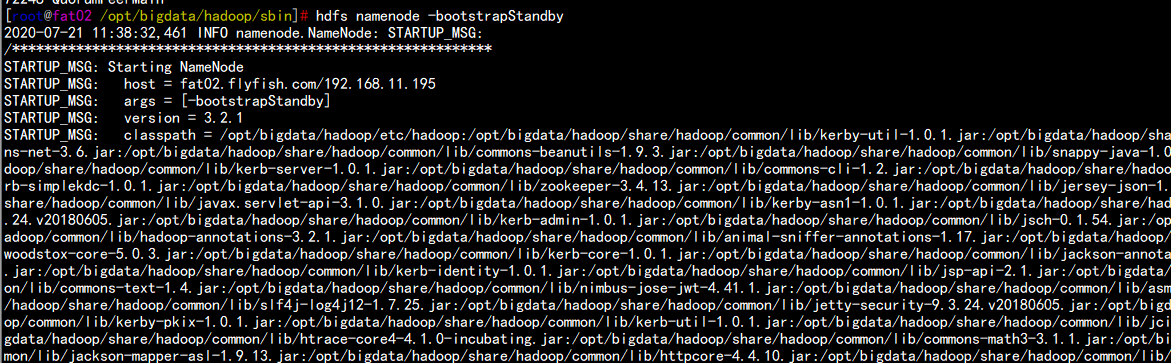
fat02.flyfish.com
执行 备用节点:
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode
![图片.png-57.1kB]()
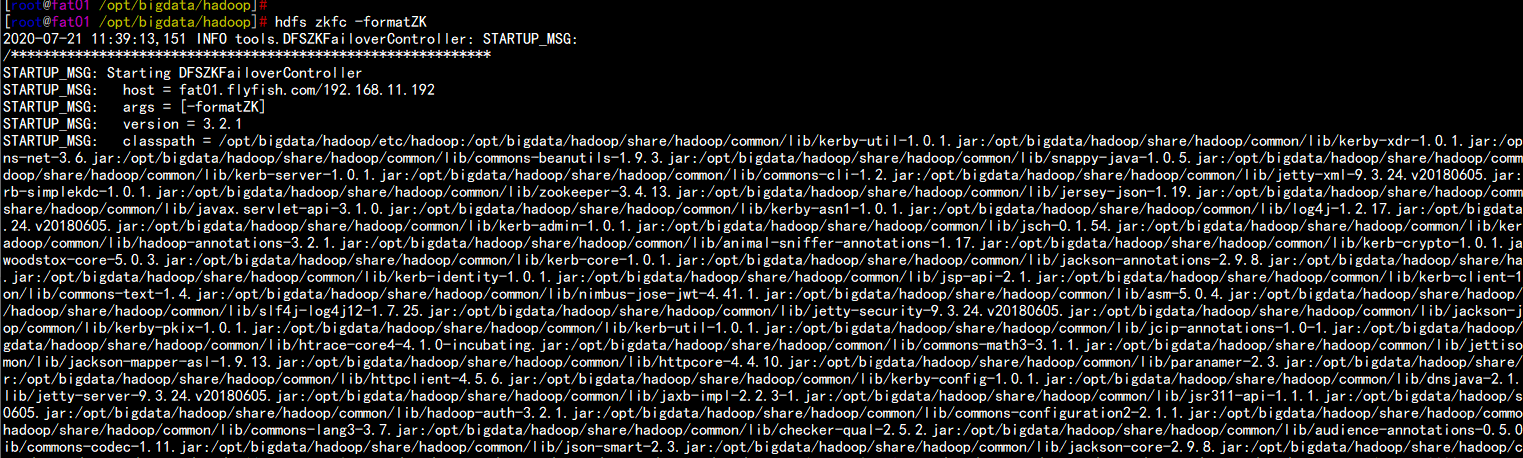
4.11格式化ZK 在fat01.flyfish.com上面执行
cd /opt/bigdata/hadoop/bin
./hdfs zkfc –formatZK
![图片.png-84.6kB]()
4.12 停掉/启动 hdfs 的所有 服务
cd /opt/bigdata/hadoop/sbin/
./stop-dfs.sh
./start-dfs.sh
![图片.png-41.7kB]()
![图片.png-38.9kB]()
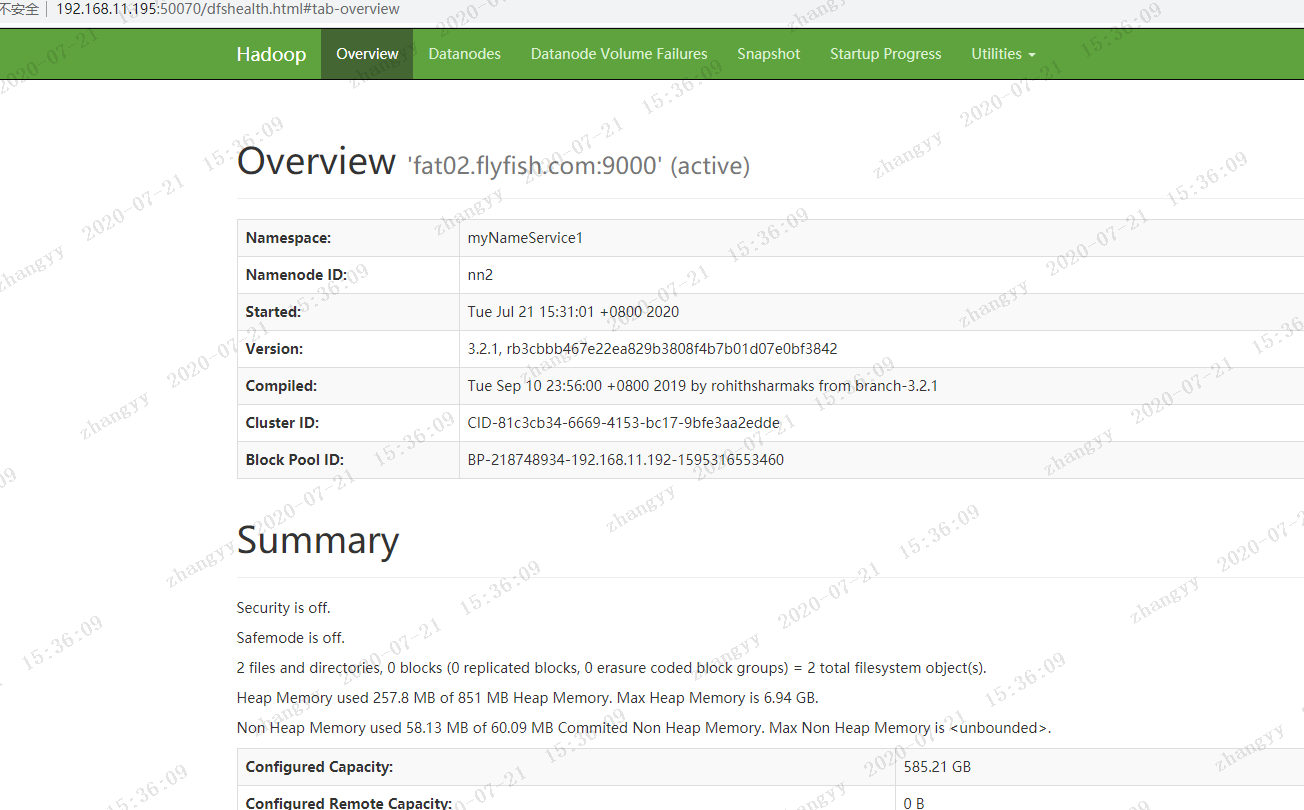
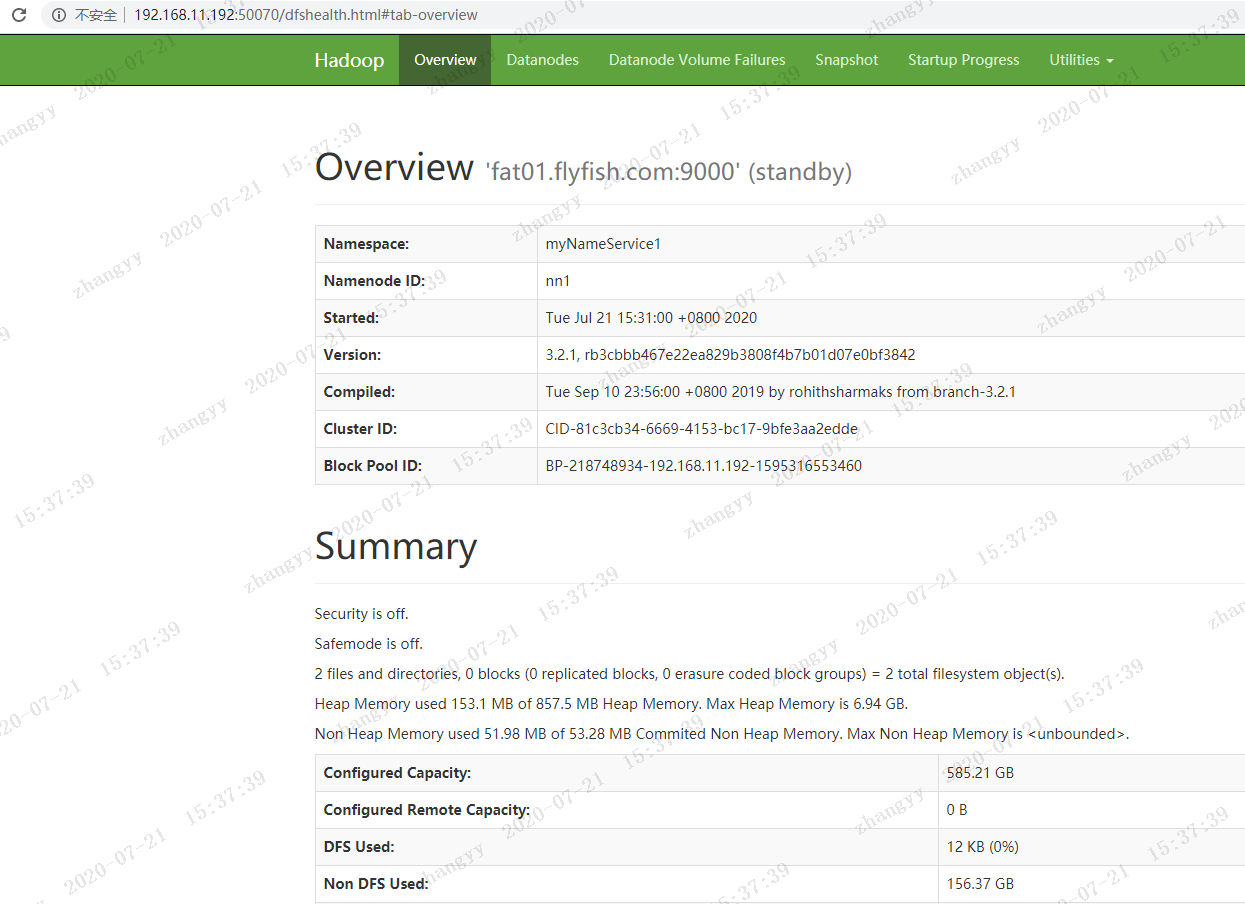
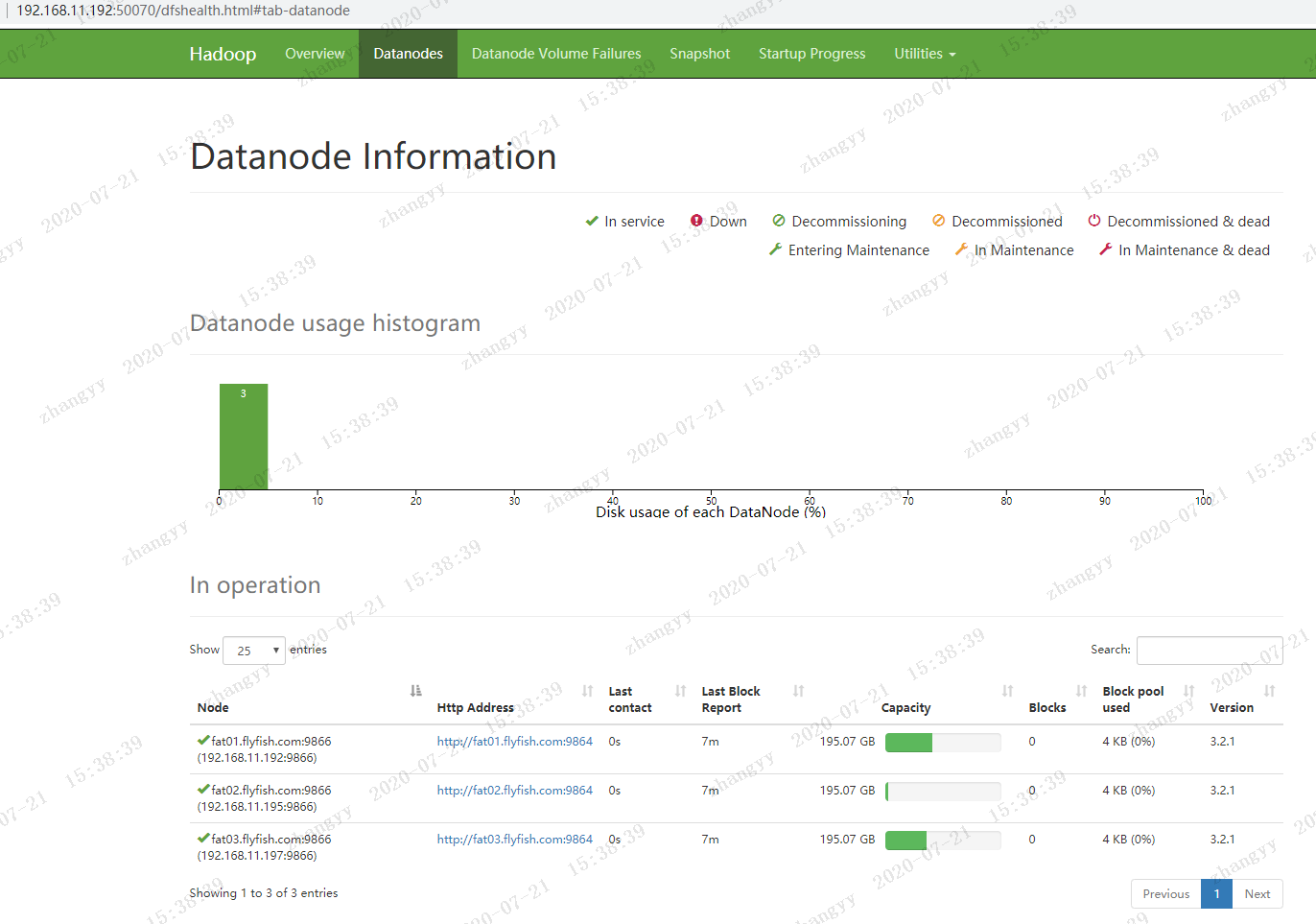
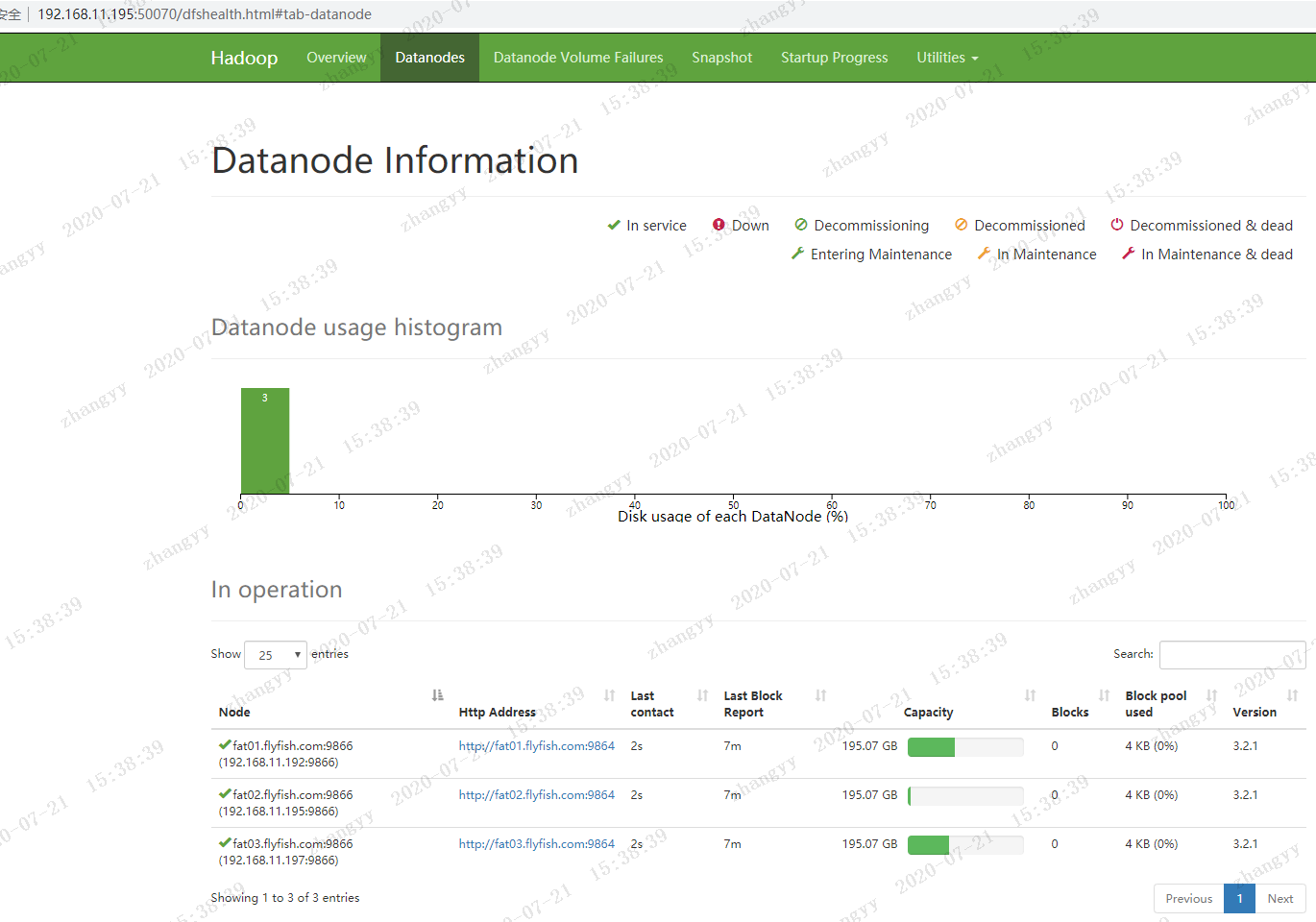
打开hdfs 的web页面
![图片.png-65kB]()
![图片.png-69.9kB]()
![图片.png-68.7kB]()
![图片.png-68.6kB]()
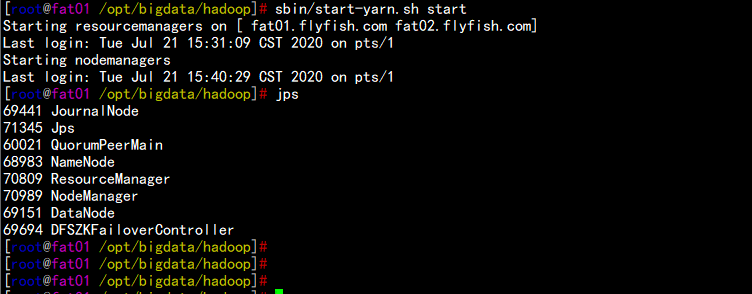
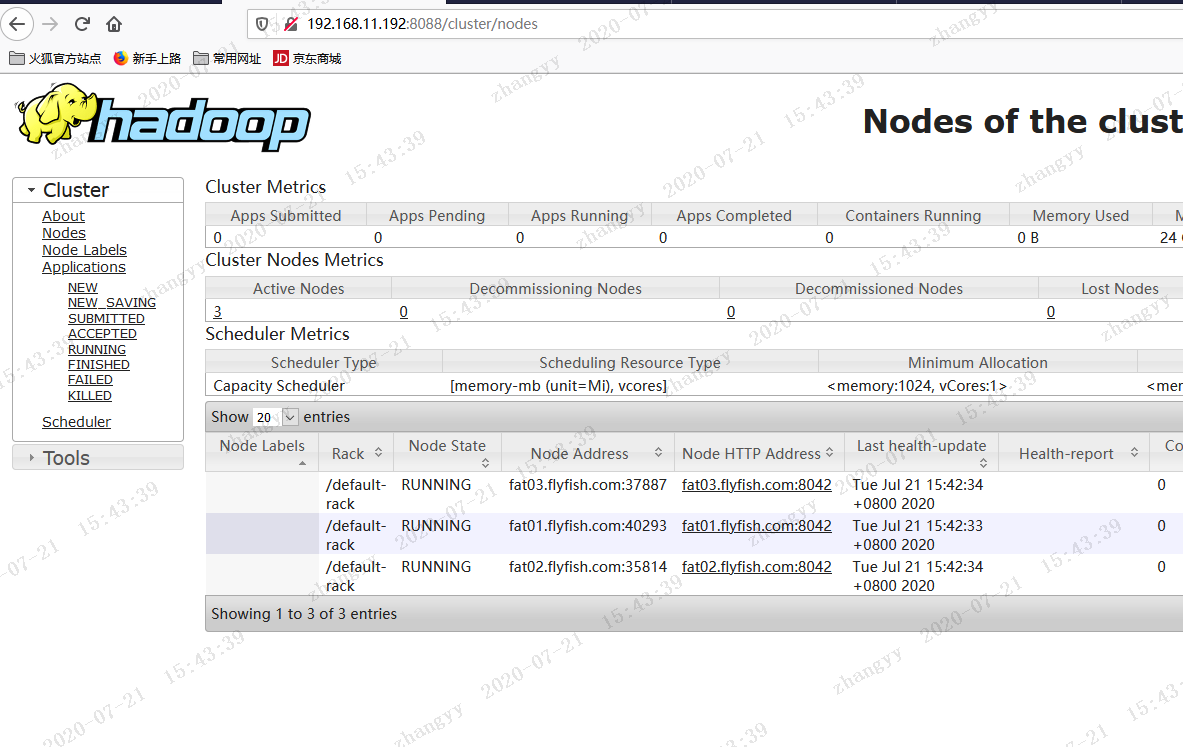
4.12 启动yarn
cd /opt/bigdata/hadoop/
sbin/start-yarn.sh 启动 yarn
sbin/stop-yarn.sh 停掉 yarn
![图片.png-24.8kB]()
![图片.png-14.1kB]()
![图片.png-12.3kB]()
![图片.png-91.1kB]()
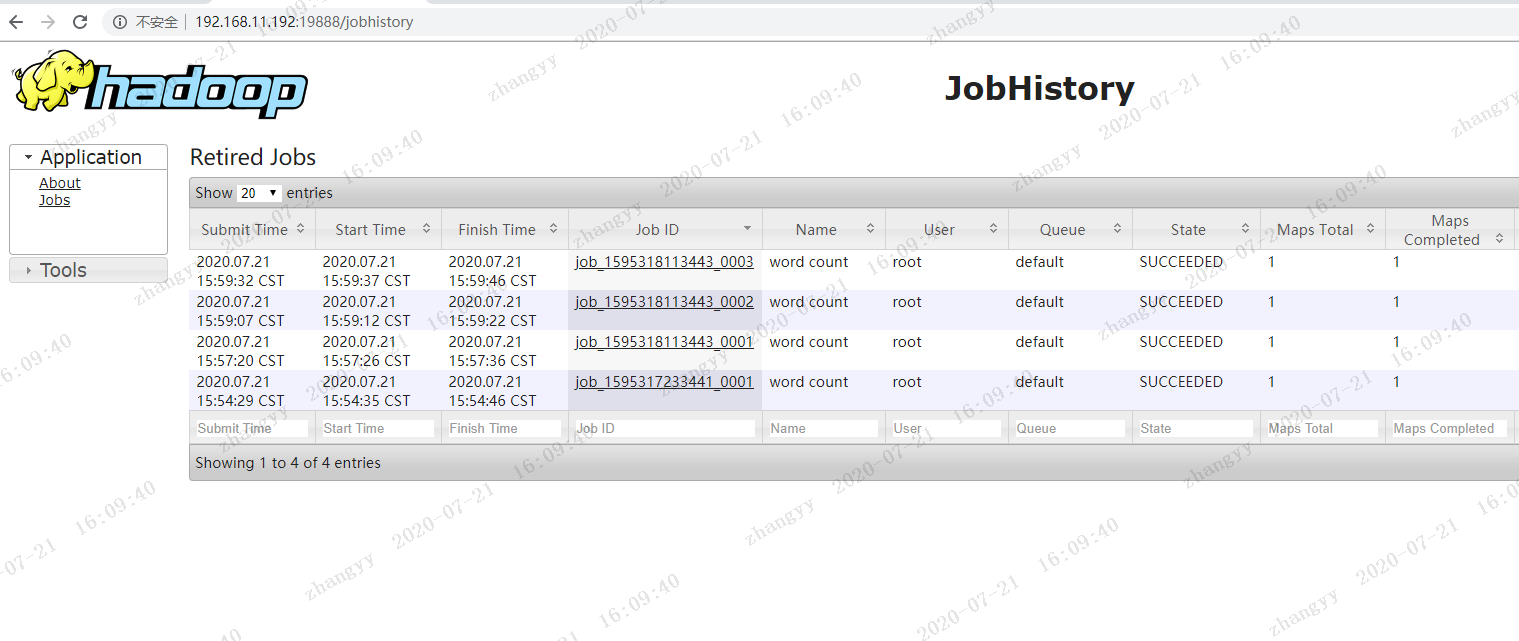
启动日志聚合功能:
cd /opt/bigdata/hadoop/sbin/
./mr-jobhistory-daemon.sh start historyserver
![图片.png-80.2kB]()
五:关于 HA 的测试
5.1 hdfs HA 测试
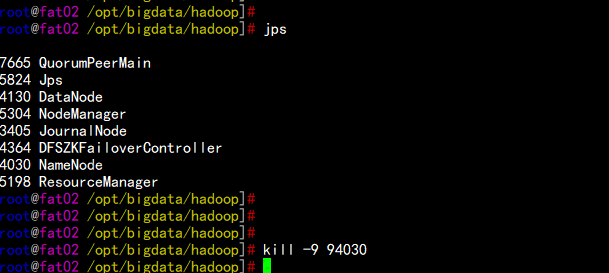
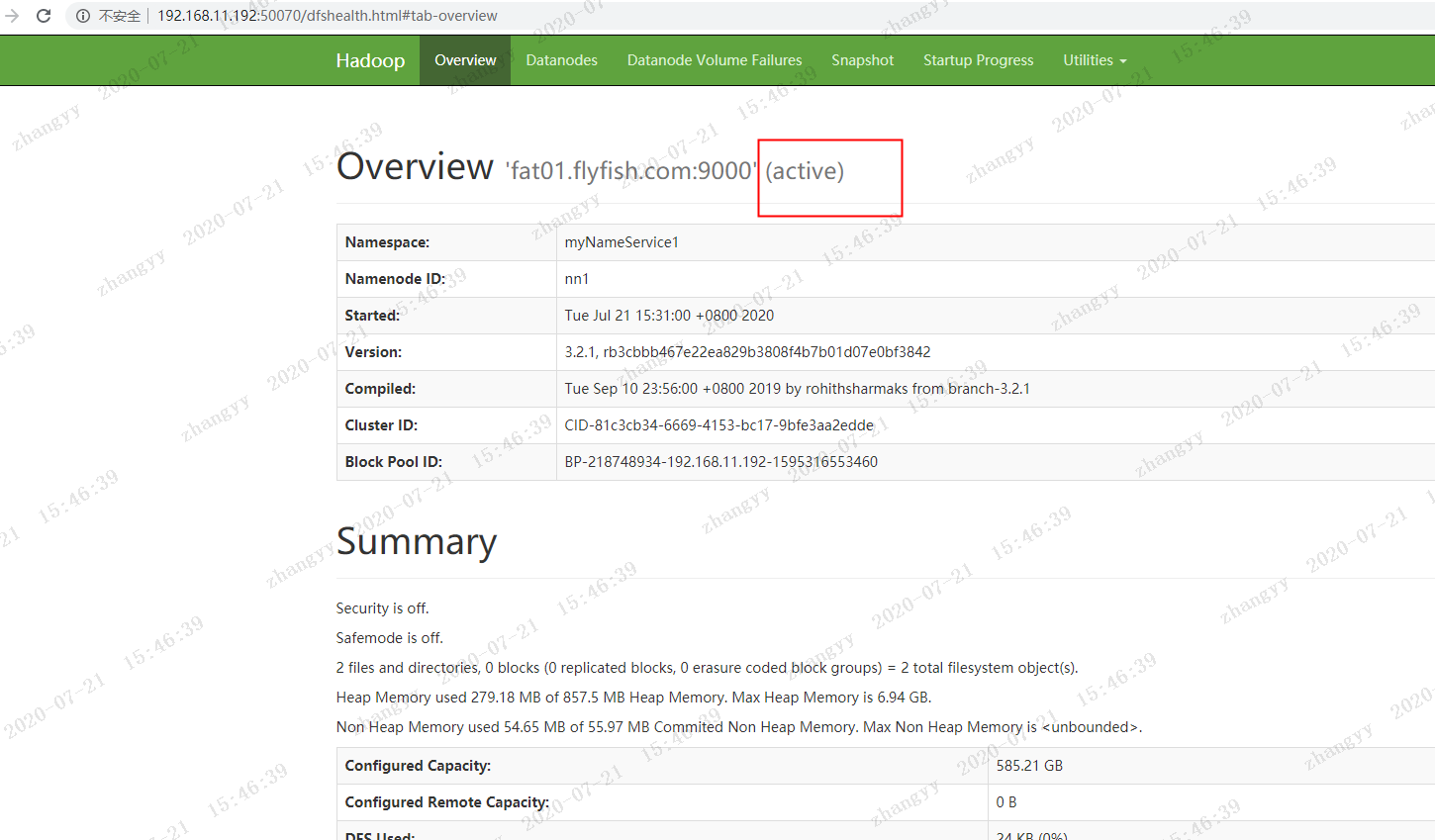
当前节点fat02.flyfish.com 的hdfs 是active 状态
把 fat02.flyfish.com 的 NN 服务停掉
jps
kill -9 94030
fat01.flyfish.com 上的 NN 节点立马变为 active 状态
![图片.png-19.8kB]()
![图片.png-71.4kB]()
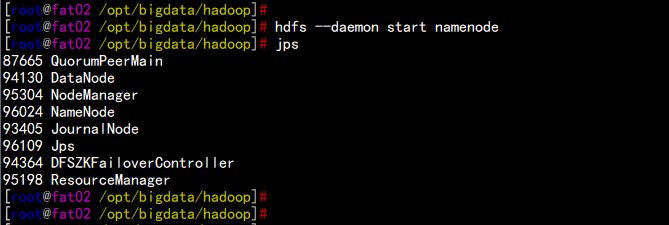
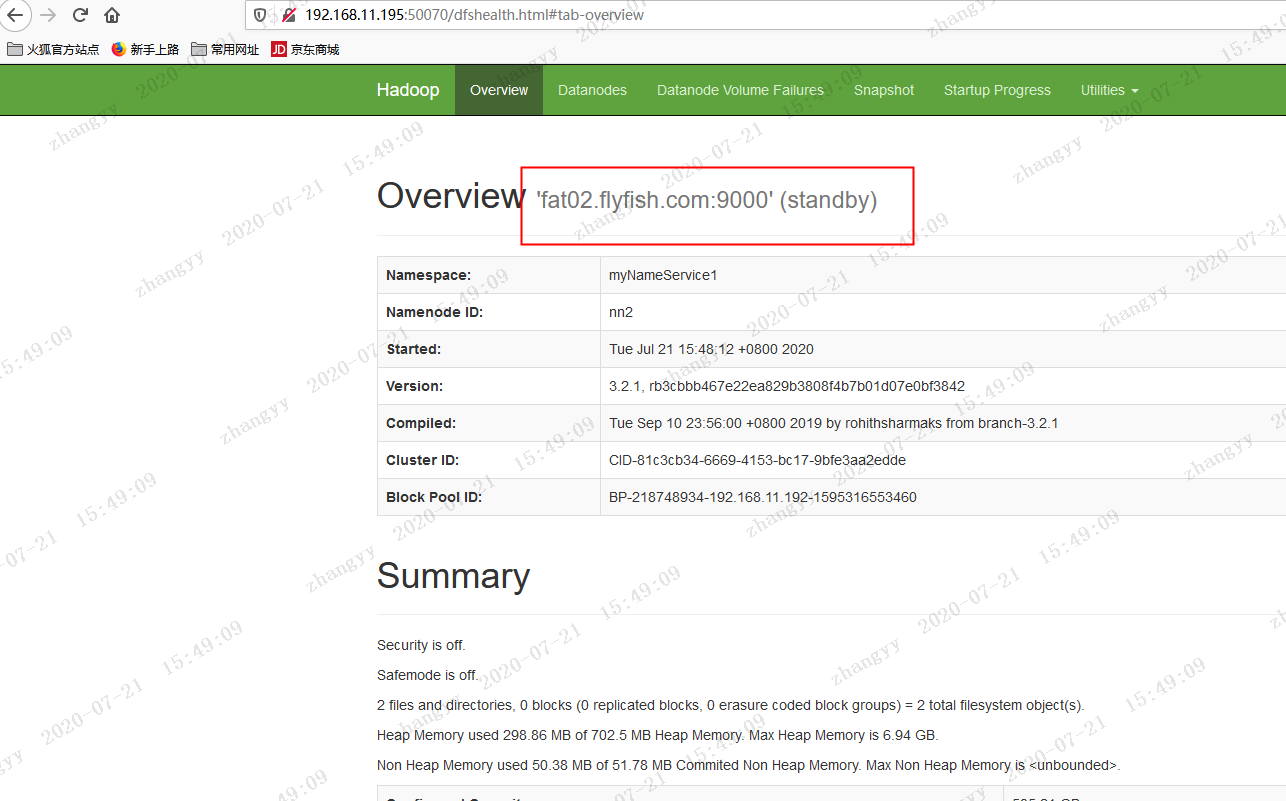
然后启动fat02.flyfish.com 的NN 节点
hdfs --daemon start namenode
fat02.flyfish.com 上面的NN 变为standby
![图片.png-17.8kB]()
![图片.png-61.4kB]()
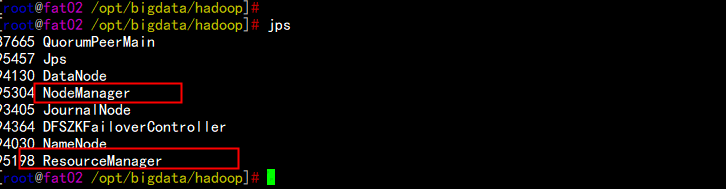
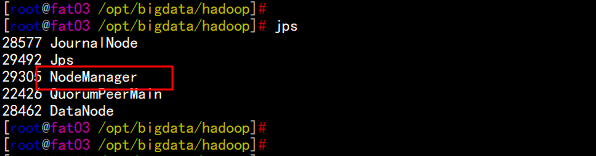
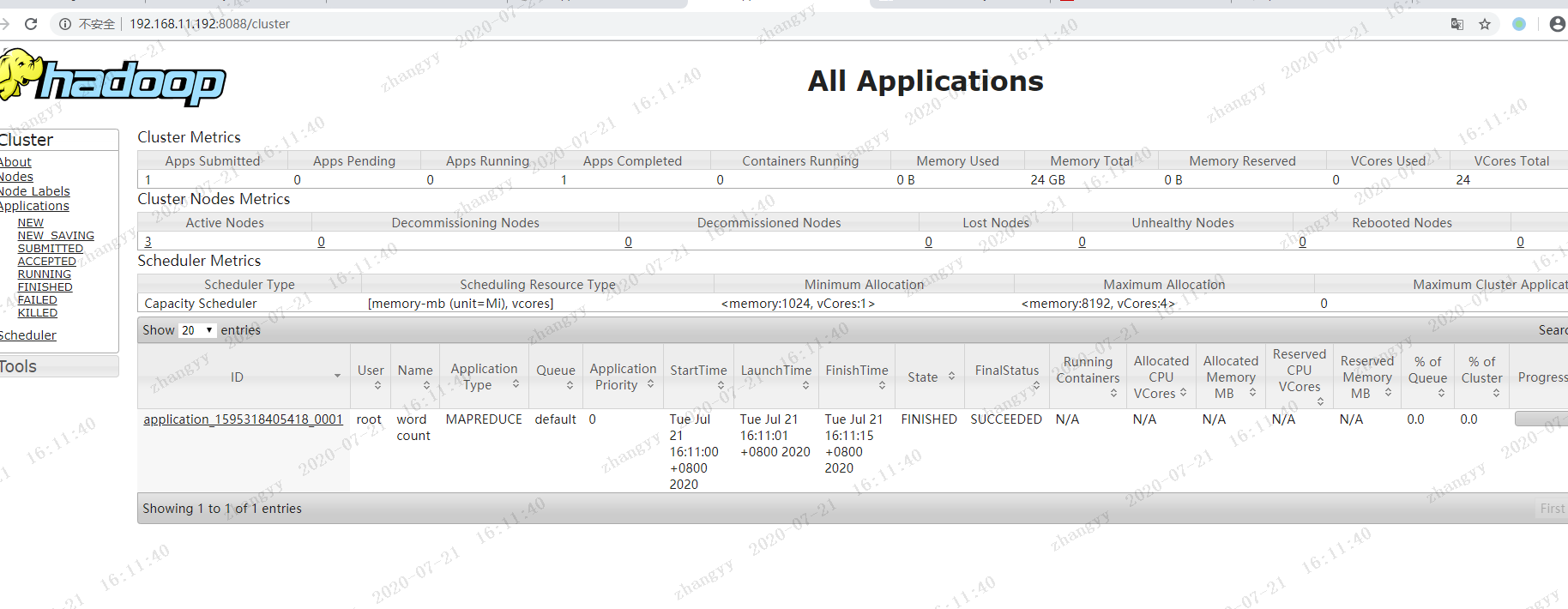
5.2 yarn 的HA 测试
提交一个job
hdfs dfs -mkdir /input
hdfs dfs -put word.txt /input
cd /opt/bigdata/hadoop/
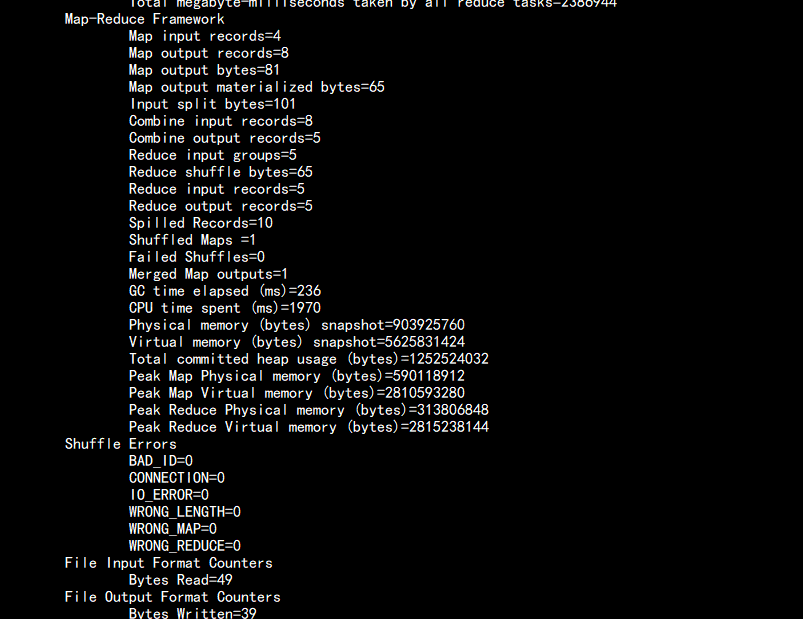
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output1
![图片.png-51.3kB]()
![图片.png-43.4kB]()
![图片.png-102.6kB]()