一、前端路由解决什么问题?
每个技术点的出现,都是为了解决当前的某一些问题,那么,前端路由的出现,又是解决了什么问题呢?
1、问题背景
从历史的发展总能找到些蛛丝马迹,让我们在当前的阶段往前推一下,拎出那个时代的背景以及它的问题
![]()
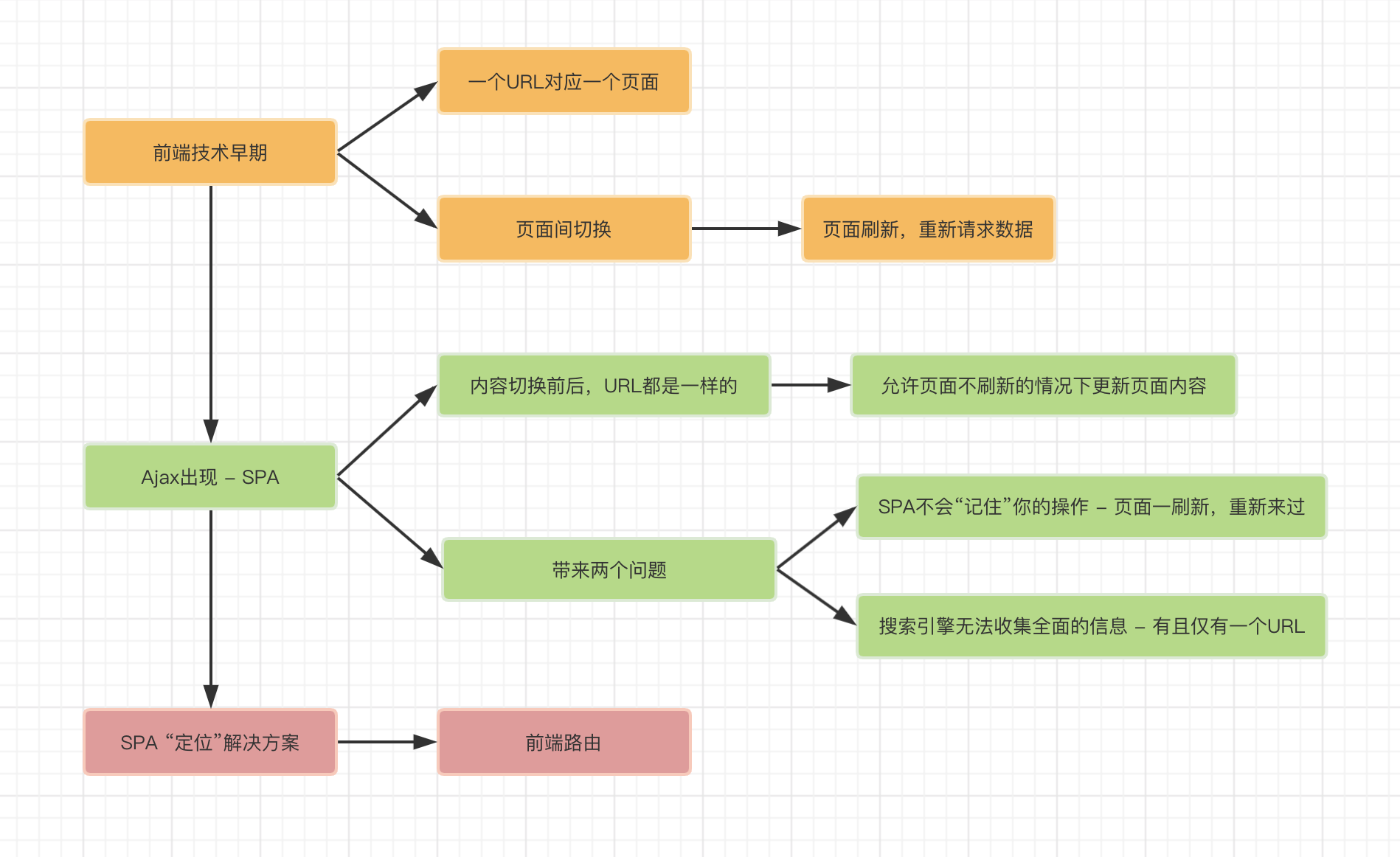
不难看出,前端路由的出现,是要帮助我们在仅有一个页面的情况下,“记住”用户当前走到了哪一步。因此,它需要为SPA(单页面应用)中的各个视图配置一个唯一标识,这意味着用户前进、后退触发的内容,都会映射到不同的URL上去。此时即便刷新页面,内容也不会消失,因为当前的URL已经有能力识别到它所处的位置了。
2、SPA“定位”两大痛点
我们还是回到上图,细细解剖下SPA下的两大痛点:
- 当用户刷新页面时,浏览器会默认根据当前
URL对资源重新定位(回到最初的状态) - 这个动作不仅使得用户的前进后退操作无法被记录,而且它是不必要的,你想想:SPA作为单页面,本身也只会有一个资源与之对应
SPA对服务端而言,就是一个URL、一个资源。如何将其改变为“多个URL” 映射多个视图内容呢?
3、SPA“定位”解决思路
问题已经摆出来了,那么,解决问题的思路是如何呢?
- 首先:拦截用户的刷新操作,避免服务端盲目响应,返回不符合预期的资源内容,把刷新这个动作完全放到前端逻辑里消化掉
- 感知
URL的变化。前端给URL做些不会影响其本身性质的微小处理,不会影响服务器对它的识别,只有前端能感知到,进而通过JS去生成不同的内容
4、hash 与 history 实践
思路清晰了,那么目前前端界对此有哪些实现思路呢?
hash模式
通过增加和改变哈希值,从而让页面感知到路由变化,换句话说就是改变URL后面以#分隔的字符串,比如下面这样一个URL
https://www.huamu.com/
改变URL后面以#分隔的字符串,即哈希值
// 主页
https://www.huamu.com/#index
// 博客页
https://www.huamu.com/#blog
那么,在hash模式下,JS是如何捕获到哈希值的内容呢?
hash的改变 - 通过location暴露出来的属性,直接修改当前URL的hash值
window.location.hash = 'index';
hash的感知 - JS通过监听hashchange事件来捕捉hash值的变化,进而决定页面内容是否需要更新
// 监听hash变化
window.addEventListener('hashchange',()=>{
// 根据hash值的变化更新内容
},false)
history模式
点击浏览器的前进后退会触发hash的感知,同时,浏览器的history API也给我们提供了接口来操作它的历史
在HTML 4阶段提供了“切换”的三个接口,如下:
// 前进到下一页
window.history.forward()
// 前进两页
window.history.go(2)
// 后退到上一页
window.history.back()
// 后退两页
window.history.go(-2)
到HTML 5阶段新增了“改变”的两个接口
// 向浏览历史中追加一条记录
history.pushState(data[,title][,url])
// 更新当前页在浏览历史中的信息
history.replaceState(data[,title][,url])
history的感知 - forward、back和go方法的调用会触发popstate,但pushState和replaceState不会,需通过自定义事件和全局事件总线来触发事件,进而每当浏览历史发生改变时,popstate事件都会被触发
// 监听history变化
window.addEventListener('popstate',(e)=>{
console.log(e)
},false)
二、React-Router 如何实现路由跳转
了解了背后的机制,再看表面现象,或许有不一样的认识。接下来,我们来回顾一下React-Router中的3个核心角色
1、3个核心角色
-
导航,比如 Link、NavLink 和 Redirect(以Link为代表)负责触发路径的改变
-
路由,比如 Route和Switch(以Route为代表)负责定义路径与组件之间的映射关系
-
路由器,比如BrowserRouter和HashRouter,根据Route定义出来的映射关系,为新的路径匹配它对应的逻辑
2、路由器
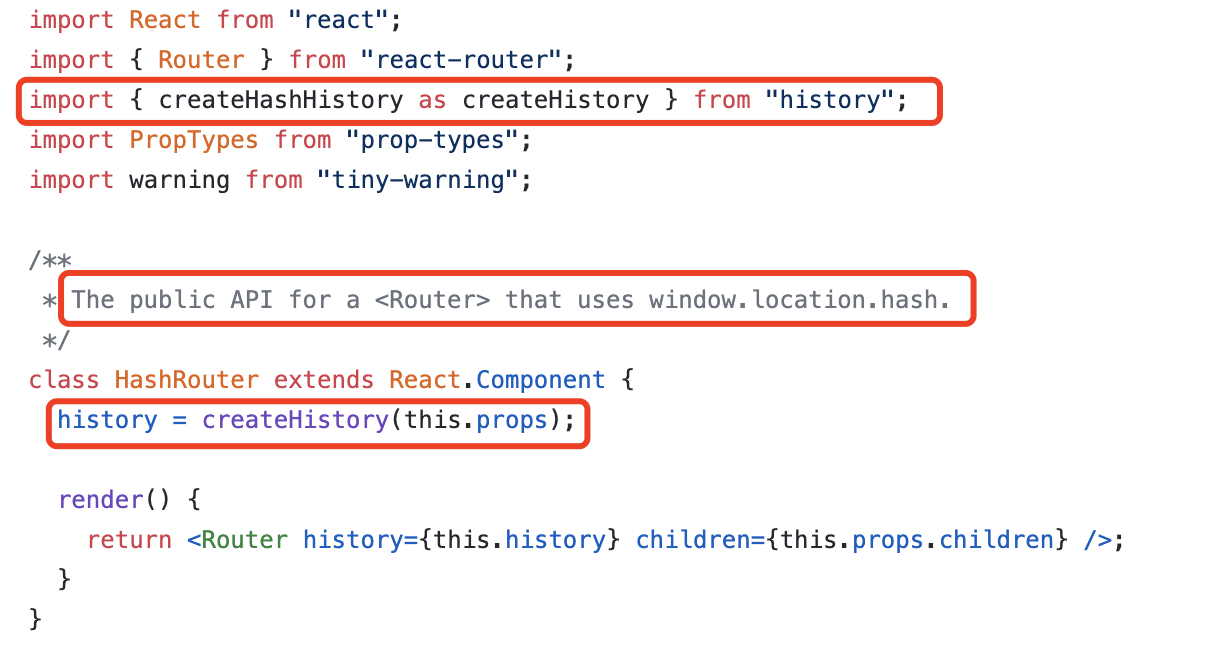
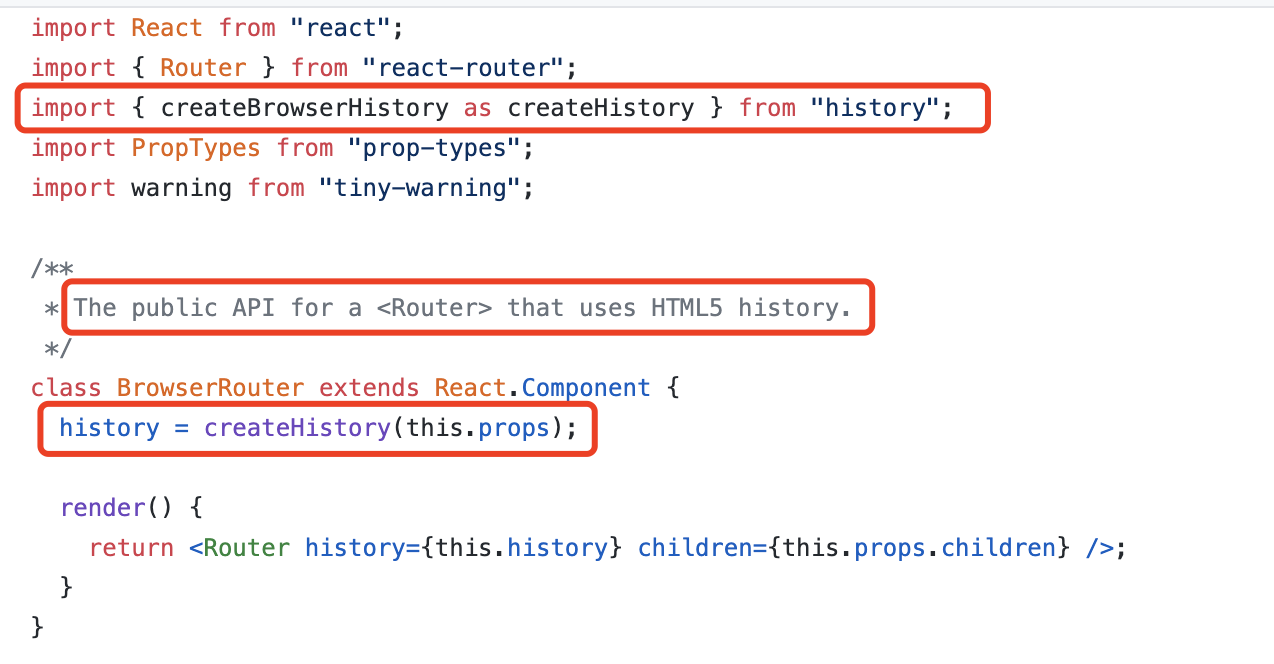
其中,负责感知路由的变化并作出反应的路由器,是整个路由系统中最为重要的一环。在React-Router中支持两种路由规则:HashRouter和BrowserRouter分别对应了hash和history两种背后模式,让我们透过源码,揭开这层面纱
![]()
![]()
在图中,我们标识出关键的区别,即调用的history实例化方法是不同的:
HashRouter 调用 createHashHistory
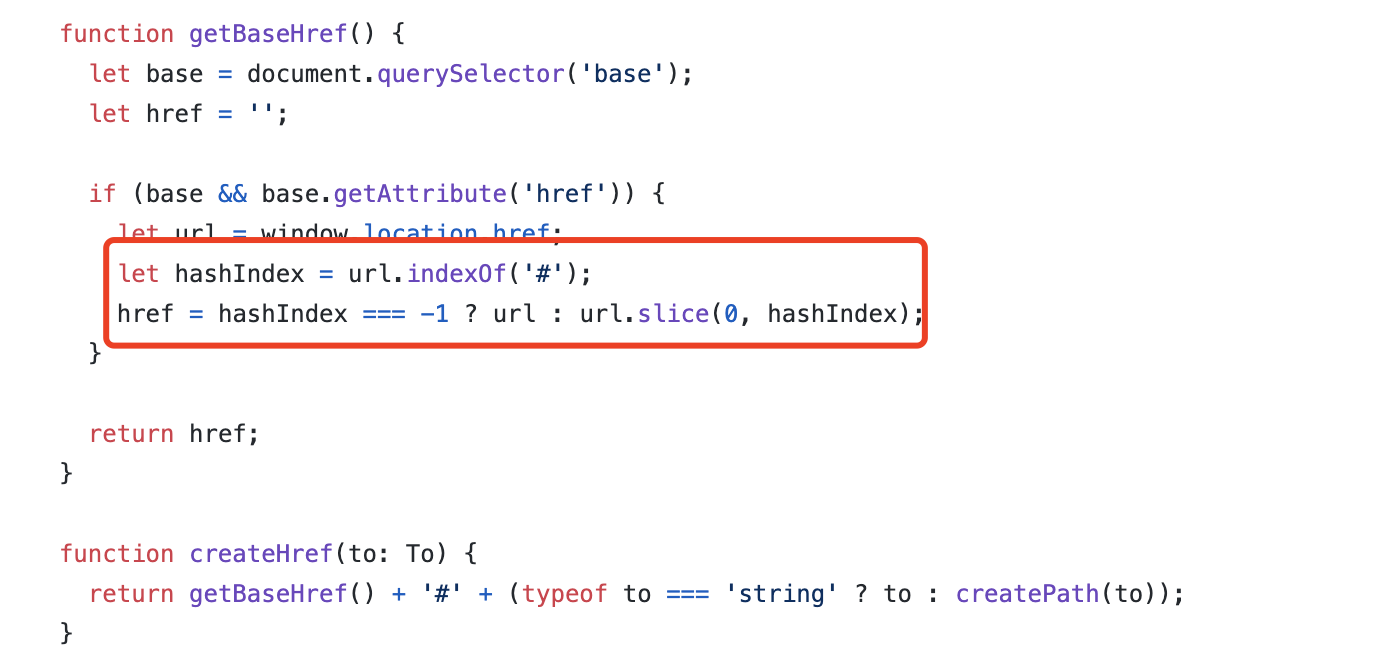
createHashHistory通过使用hash tag(#) 来处理形如https://www.huamu.com/#index 的 URL,即通过 URL 的 hash 属性来控制路由跳转
证据如下
![]()
BrowserRouter调用 createBrowserHistory
createBrowserHistory 它将在浏览器中使用 HTML 5 的 history API 来处理形如 https://www.huamu.com/index的 URL,即通过 HTML 5的 history API 来控制路由跳转