1 背景
在CTR预估任务中, 线性模型仍占有半壁江山。利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,而且可解释性强。但这种方式有着较为明显的缺点:首先,特征工程需要耗费太多精力。其次,因为模型是强行记住这些组合特征的,所以对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式减轻了特征工程的负担,而且能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的嵌入向量是不准确的,这便会造成模型泛化过度,当基础query-item矩阵稀疏且评分较高时,例如具有特定偏好的用户或具有狭窄吸引力的商品,很难学习有效的query和item的低维表示形式。在这种情况下,大多数query-item对之间不应存在任何交互,但是密集的嵌入向量将导致所有query-item组合的预测都不为零,因此可能泛化过度,做出的推荐的相关性也比较小。
2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式。
2 模型结构及原理
![]()
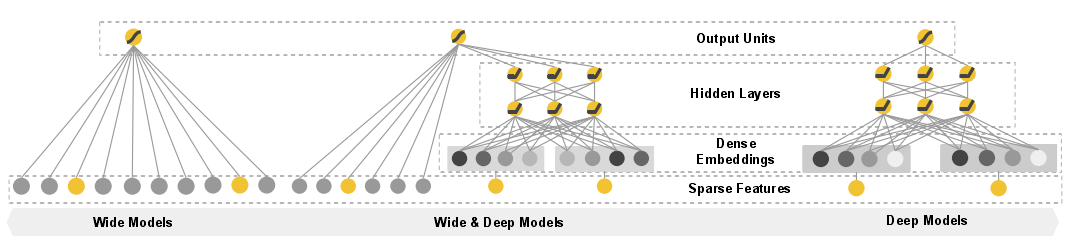
图中最左边是模型的Wide部分,这个部分可以使用广义线性模型来替代,如LR便是最简单的一种。模型的Deep部分是一个简单的基于Embedding的全连接网络,结构与FNN一致。
2.1 Wide部分
这部分是一个广义线性模型 ![]() ,其中
,其中 ![]() 是
是 ![]() 维特征向量,特征集合包括原始输入特征和转换后的特征。最常用的特征转换函数便是特征交叉函数
维特征向量,特征集合包括原始输入特征和转换后的特征。最常用的特征转换函数便是特征交叉函数 ![]() , 当且仅当
, 当且仅当 ![]() 是第
是第 ![]() 个特征变换的一部分时,
个特征变换的一部分时, ![]() 。否则为0。例如,对于一个二值特征,特征交叉函数为
。否则为0。例如,对于一个二值特征,特征交叉函数为 ![]() ,当且仅当构成特征中
,当且仅当构成特征中 ![]() 和
和 ![]() 时该函数值为1,否则为0,即同时具有这两个特征,那么转换后的新特征才为1。这捕获了二元特征之间的相互作用,并为广义线性模型增加了非线性。
时该函数值为1,否则为0,即同时具有这两个特征,那么转换后的新特征才为1。这捕获了二元特征之间的相互作用,并为广义线性模型增加了非线性。
Wide部分只能学习这些模式的权重,做一些筛选,而不能自己发现新的模式,需要根据人工经验、业务背景,来将我们认为有价值的、显而易见的特征及特征组合喂入Wide部分。
2.2 Deep部分
Deep部分是全连接网络: ![]() 。输入的特征分为两类:一类是数值特征(可直接输入DNN);一类是类别特征(需要经过Embedding之后才能输入到DNN中)。通过增加模型的层数,使要素发生更深层次的交互,提高模型的泛化能力。
。输入的特征分为两类:一类是数值特征(可直接输入DNN);一类是类别特征(需要经过Embedding之后才能输入到DNN中)。通过增加模型的层数,使要素发生更深层次的交互,提高模型的泛化能力。
2.3 Wide与Deep的结合
将两部分的输出结合起来联合训练,将Wide和Deep部分的输出使用逻辑回归模型做最终的预测: ![]() 。 需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是Adagrad。
。 需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是Adagrad。
3 思考
- 适用于Wide部分的特征:高维稀疏特征、人工手动交叉特征;适用于Deep部分的特征:数值类特征、类别特征等
- 使用L1 FTRL是应对稀疏性一种很好的方法,方法非常注重稀疏性,采用L1 FTRL可以让Wide部分更加稀疏。
- Deep部分的输入要么是数值型特征,要么是嵌入向量,不存在严重的稀疏性问题,所以不用特别考虑Deep部分的稀疏性问题。
4 代码实现
模型的实现与模型结构类似由deep和wide两部分组成,这两部分结构所需要的特征在上面已经说过了,针对当前数据集实现,我们在wide部分加入了所有可能的一阶特征,包括数值特征和类别特征的onehot都加进去了,其实也可以加入一些与wide&deep原论文中类似交叉特征。只要能够发现高频、常见模式的特征都可以放在wide侧,对于Deep部分,在本数据中放入了数值特征和类别特征的embedding特征,实际应用也需要根据需求进行选择。
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
def WideNDeep(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layer = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layer)
return model
![]()
参考资料