浅谈高可用分布式流数据存储设
当数据规模发展到一定阶段,数据治理俨然已是企业系统建设的内在要求。伴随着业务的快速发展,多种多样结构复杂的数据给数据治理带来了巨大的考验。
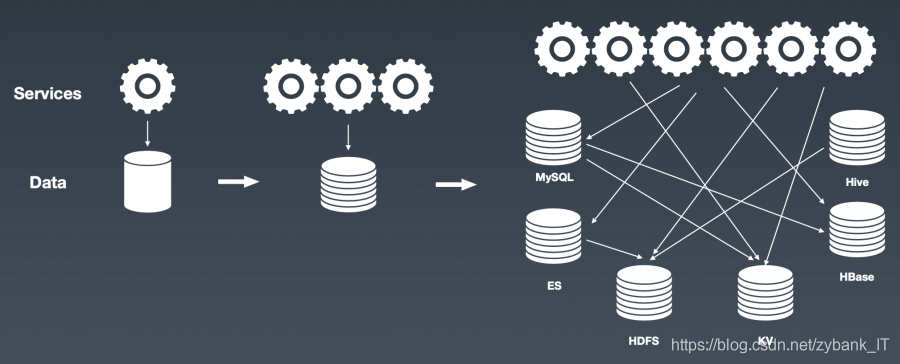
早期的小规模业务,单体服务配合单个数据库即可满足业务需求。而当下,数据库分库分表,并采用读写分离和分布式的架构模型,同一份数据被转换成各种特定的数据格式,存放在各种各样的数据库中,会消耗大量的存储和计算资源。为解决这一数据治理乱象,分布式流数据存储应运而生。
数据存储的进化史
起初,单体服务应用只需一个数据库存储数据就足够了。随着业务需求的增多,服务从1个增长到N个,数据也需要分库分表来存储,若基于容灾等方面考虑,还需要做多个副本。此外不同的业务场景需要用到不同结构的数据存储,比如搜索需要用到ElasticSearch,存储分析需要用到Hive集群,在线业务需要用到K-V(键-值,NoSQL)存储和MySQL存储,同时这些数据还要在一定的业务场景下做到实时同步。![在这里插入图片描述]()
在这种情况下,数据就存在诸多问题:
- 当数据在各种场景下ETL(Extract-Transform-Load,数据抽取、转换和加载)会造成严重的资源浪费;
- 每份数据都有快照备份,占用极大的存储空间;
- 当某一份数据不止服务于一个微服务时,一旦业务调整,一份数据的变动将会影响下游的数据变动,就会出现严重的耦合问题。
冗杂数据随业务扩张而呈指数增长,数据治理显得尤为重要。分布式流数据存储平台,便可应对上述问题。
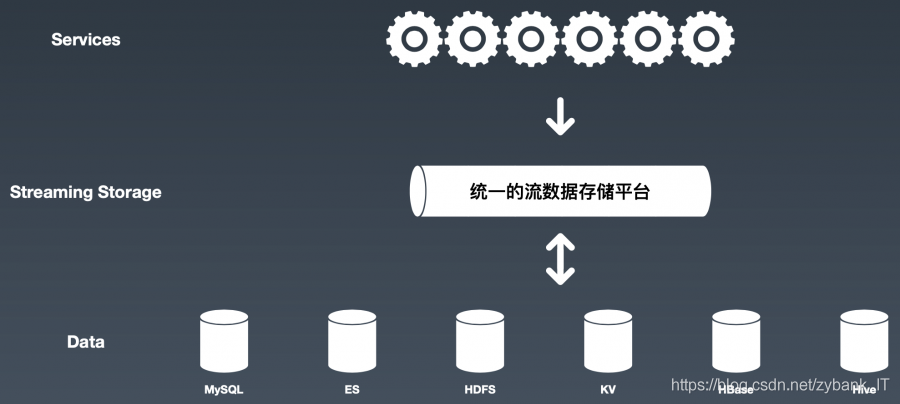
流数据存储平台的设计
![在这里插入图片描述]()
前后端数据在一个时间点产生,当我们对某个特定的数据做变更,并将其放入到流存储平台里面,其他服务调用数据时,无需经过ETL即可直接使用。需要注意的是,流数据不能服务于终端业务,因为流数据在平台中是查询不友好的,无法按照业务场景去查询。
对于以上的应用背景分析,那么其存储特性也就很显而易见了:
- 有序性:数据必须是有序的,因为数据的读取和处理是按照写入的顺序进行的;
- 扩展性:数据只能在尾部写入,写入则无法变化;
- 性能:具有高性能、可靠性等分布式系统特性;
- 一致性:不需强一致性,要求顺序一致性即可;
- 容量:因存储所有数据,要求近乎无限的容量。
基于上述存储特性,可以有针对性地设计流数据存储平台的核心组件。
1.存储结构设计
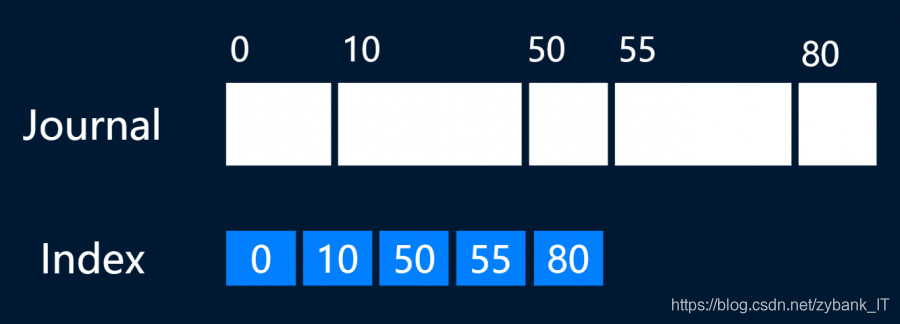
存储结构设计决定着每一个存储产品的性能。下图为流数据存储的结构设计:
![在这里插入图片描述]()
因数据长度不一,一个索引记录一条数据的位置。在这里,每个索引都是十六进制Long型的数值,也即索引的大小是固定的,指向的数据是不固定的。如上图,每一个索引都指向了每条数据的起始位置。
![在这里插入图片描述]()
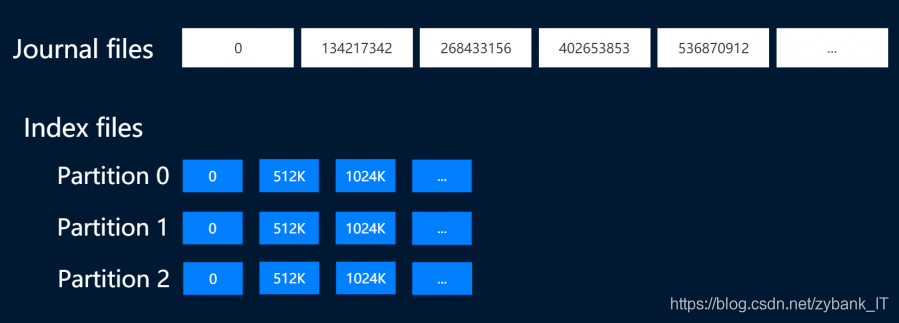
对应到文件系统,数据分为N个小文件,文件名对应文件里面第一条数据的位置,相应的索引也是一样的。根据以上设计,总结存储结构对应的时间复杂度如下:
- 写入:O(1)
写入数据时,是直接在尾部追加的,因此为O(1);
- 查找:O(logn)+O(logn)≈O(1)
在读取时,使用索引值去读取。因每个文件的名字就是文件里面第一条数据的位置,且每一个索引都是16字节,把数据的索引值乘上16即可定位索引里的全局位置。在存储时,索引文件和数据文件都存放在内存跳表中,在跳表里查找索引所在文件的时间复杂度为O(logn),其中n为跳表里面文件的数量,换算相对位置进而定位数据的索引位置。再在数据文件里做一次O(logn)的搜索找到数据所在文件,根据相对位置就可找到数据了。一般情况下,文件的数量和数据的数量相比差了很多个数量级,因此上述的搜索时间复杂度可以约等于O(1)。
2.缓存设计
缓存的设计优化主要有以下几个方面:
- PageCache(缓存页)缓存文件:流数据的一个特点是顺序读写,其随机读取的情况很少出现。因此将每一个文件对应内存的一个PageCache,直接把整个文件缓存到内存里面。这种设计的优势在于,不需要为缓存页编写单独的查找算法,只需复用文件的查找算法即可,并且缓存页和文件的对应关系也变得非常简单;
- 使用堆外内存:Java的GC机制对高并发来说并不友好,当并发上来时,很难预测GC的时间。堆外内存可防止过多的GC操作,但不合理的使用堆外内存会造成内存泄漏,所以合理的使用堆外内存可提高高并发能力;
- 异步预加载:流数据都是连续读取,当读取文件接近尾部时,就会大概率读下一个文件,因此,在文件读到接近结尾时加载下一个文件,能有效预防卡顿;
- 读写共页:写数据的时候将数据直接缓存起来,直接从缓存读取,而不是去磁盘读取文件;
- PLRU淘汰策略:当内存将满时,须进行释放,LRU可以把最近不常用的数据淘汰掉。此外,根据流数据的特点,越接近尾部的数据被访问的可能性越大,将数据根据其与尾部的距离加上权值,就能将不常用且相对老的数据淘汰掉,能很好地避免“挖坟”的情况。(备注:当某应用突然读取很古老的数据时,读取过的数据会加载至缓存里面,此时造成缓存的命中率急剧下降,即为“挖坟”)
3.写入流程优化
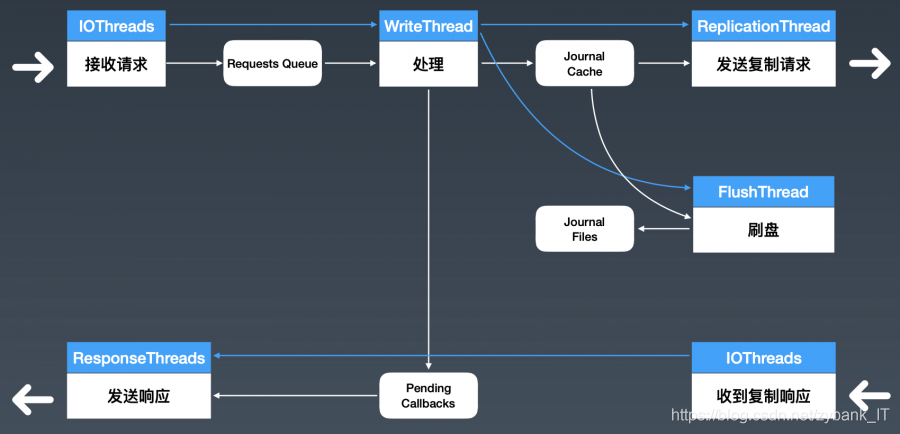
写入流程总共靠6组线程来完成。当数据写入,IOThreads将数据推至请求队列,唤醒WriteThreads,从队列中取出数据、产生索引、写入内存缓存,生成响应并放至队列,通知ReplicationThreads发送复制请求和FlushThreads进行数据的异步刷盘。需要注意的是,此时并不会将响应发回客户端。ReplicationThreads从缓存中读取数据,向节点发送复制的包,由IOThreads等待响应。当IOThreads收到超半数的响应之后,通知ResponseThreads发送之前生成的响应。
根据这种写入流程的优化,会发现每一组线程之间并不会相互等待,也并不需要锁来共享任何的数据,这样就实现了全异步化,从而达到系统的最大性能。
![在这里插入图片描述]()
4.集群架构的设计
如果说小的技巧和方法更适用于单节点的优化,则集群层面更多的是取舍问题。我们需立足实用角度,全面考虑一致性、可用性和分区容错性,且放弃一个或多个方面。
比如,使用Redis和MySQL做缓存,则意味放弃了一致性;再比如,做大促限流时,数据加载的慢,则放弃了性能,保留了一致性和可用性。
因此,在做架构设计时,应尽量将服务做成无状态的,进而更容易地实现水平扩展,且不必考虑一致性问题。当然,如果业务必须是有状态的、计算是无状态的,则可将计算和存储分离,存储可放到MySQL或者ZooKeeper里面。
思维沉淀
通过高性能分布式流数据存储平台的设计分析,可以发现,很多思想值得借鉴。
系统的设计一定要结合实际需求。在设计存储数据的文件结构时,根据流数据的特点来优化存储方法,可达到读写都是O(1)的时间复杂度;
使用异步模型提升系统性能。同步模式下,若系统涉及到数据读取或其他阻塞操作时,大量线程处于等待状态,会出现资源利用率低且性能无法提升的情况。而在异步模型下,系统能够协调线程之间的运行时间,减少或避免线程等待,用很少的线程就可达到超高的吞吐能力,从而使系统工作效率的最大化。需要注意的是,异步并不会加快程序本身的运行速度。
使用缓存加速数据的读写。众所周知,缓存的I/O性能是磁盘无法比拟的,因此可使用缓存减少磁盘的I/O,加速应用程序的访问速度。但是在构建缓存时,需要注意两个问题:缓存数据的命中率的保持和缓存的置换策略。其实,这两个问题本质上是一个问题,缓存置换的目的就是为了保持缓存数据的命中率。对于系统来说,只有缓存命中率的提升,使用缓存才会有显著的效果。
结合实际充分考虑CAP理论。在分布式系统架构设计时,必须根据业务特点在一致性©、可用性(A)和分区容错性§之间做出取舍。比如一个分布式系统中不存在数据副本,此时该系统必然满足强一致性和分区容错性,但如果发生网络分区或者宕机,就会导致部分数据无法访问,此时可用性就会降低。因此,世界上本没有最好的分布式架构,只有适合当前业务需求的架构,才是最优秀的架构。
参考书目资料清单:
- Qcon北京2019大会,李玥《高可用分布式流数据存储设计》演讲;
- 极客时间,李玥《从源码角度全面解析MQ的设计与实现》;
- 钟林森,《分布式中间件技术实战》。
作者:白小迪,应用开发中心技术平台组
指导老师:王东、马姿