前言
再次声明本章是一个系列中的其中一段,若想了解更多JVM虚拟机底层原理 点击首页,或关注博主,今天来谈方法区,对于方法区的内容今天多,各位听我慢慢说。
方法区
单单从名字上来看方法区似乎与我们的方法定义有关,确实如此,但是还不够严谨,我也在网上看了很多方法区的定义,但是五花八门,总感觉不够清晰!所以我们一起看看JVM规范中对方法是怎么定义的?
JVM规范-方法区定义 https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html
定义:
![]()
翻译:首先是所有Java虚拟机线程共享的一块区域,他存放了根类结构相关的一些信息,
有类的变量,方法信息,构造方法和构造器信息,和一些特殊方法(主要指类构造器)。
方法区在虚拟机启动时被创建,逻辑上来讲是堆的一个组成部分,但是并不强制你的具体位置,(说白了就是不同的JVM厂商在实现的时候不一定完全按照标准来创造)
最后对于内存定义:方法区在内存不足是也会抛出 OutOfMemoryError
解释:
说了半天可能有人听不懂了,那就来解释一下!
拿oracle的hospost虚拟机举例(也就是我们日常用的)
组成:
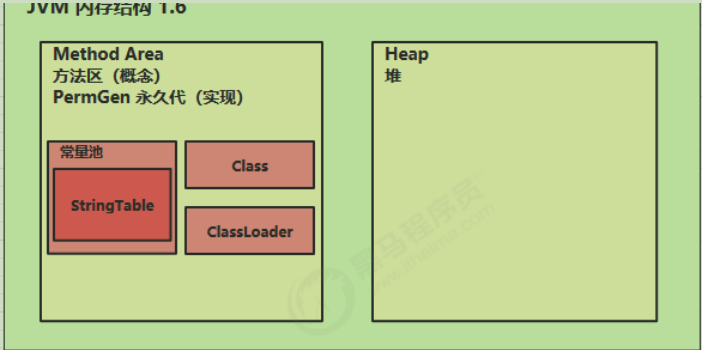
在JDK8之前hospost虚拟机对方法区的实现,叫做永久代,永久代就是使用堆的一部分空间去做实现的
![]()
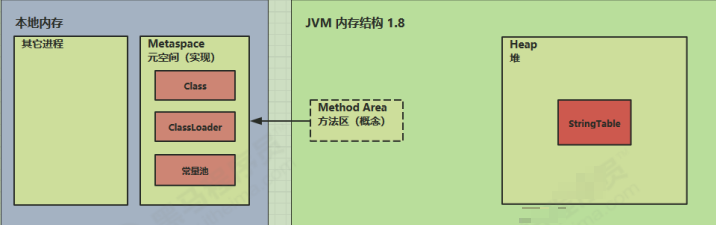
而在JDK8之后把永久代移除了,换了一个实现,叫做元空间 元空间用的不是堆的内存,而是本地内存,也就是操作系统的内存
![]()
所以不同的实现对于方法区的选择位置也不同
方法区内存溢出:
有人会疑问,方法区不就存放类的一些信息和实例吗?大小也不足以内存溢出啊,具体什么情况,拿个例子看下
/** 元空间
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
*/
public class Demo1_8 extends ClassLoader { // ClassLoader可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}
代码注释都有,自行理解,由于电脑物理内存大不方便演示效果,所以要加 -XX:MaxMetaspaceSize=8m 参数
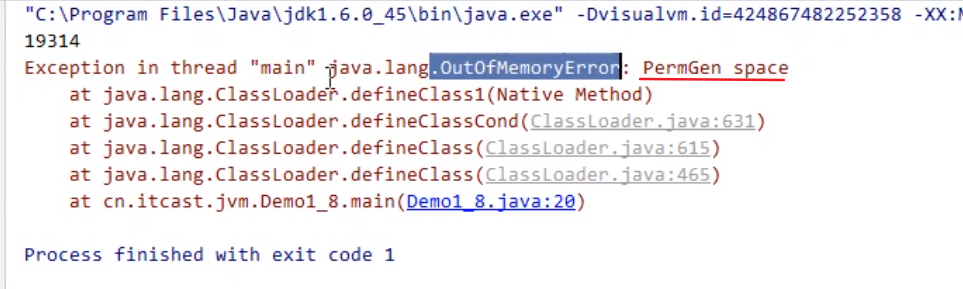
JVM1.6执行结果:永久代内存溢出导致OutOfMemoryError
![]()
JVM1.8 之后会导致元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
虽然都是OutOfMemoryError 但是可以看到1.8之前是permGen space 1.8之后是Metaspace
这种场景是非常多的, 看过spring mybatis源码的应该了解 代码使用不当是很容易造成方法区内存溢出的
运行时常量池:
在明白运行时常量池之前首先说说什么是常量池
了解运行时常量池之后,不得不说运行时常量池的一个重要组成部分StringTable
说StringTable先看几道经典面试题
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern(); // 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
讲解:
① s3 == s4 //false
s3 = "a" + "b" 两个字符串相加 stringtable会有编译期优化,结果就是 "ab"(字符串ab) 常量池没有,顺便入池。
s4 = s1 + s2 两个变量拼接在运行期使用stringbuilder拼接产生新的字符串 新的字符串相当于new String("ab")出来的 所以在堆中
所以第一题为false 理由:一个在常量池中一个在堆内存中
② s3 == s5 //true
s5 = "ab" 是一个自变量会首先检查常量池的内容,结果常量池已经有s3拼好的"ab"了,所以s5不会创建新的对象,会直接引用常量池以有的对象,因此s3和s5都是同一个对象 所以为true
③ s3 == s6 // true
s6又是调用s4.intern()方法 intern() 方法回去常量池先看有没有这个对象,如果有就返回常量池的对象,如果没有就尝试将s4进行入池,
显然常量池已有ab,没能入池成功,但他返回常量池中的对象,所以s6和s3就是一个对象 所以为true
④ x1 == x2 // false
x2 显然是堆中的对象 new String("cd") ; x1 显然是常量池中的对象
x2调用intern方法尝试将堆内存中的x2进行入池,但是常量池已经有了,所以没能入池成功,所以最终 x2是堆内存中的对象 x1 是常量池中的对象 结果为false
StringTable 特性
StringTable 位置
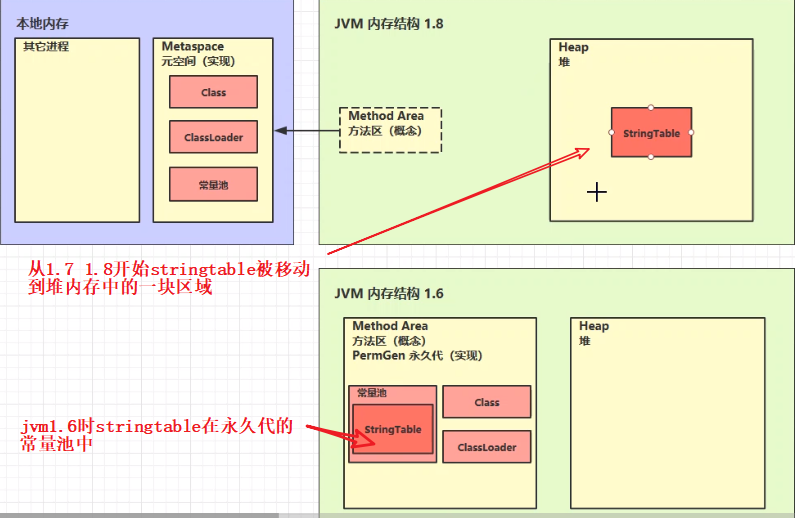
在JVM1.6之前stringtable在方法区,具体实现也就是永久代的其中一块空间 而在1.7 1.8之后 他的实现空间被移动到堆内存中
为什么更改? 原因是什么?
因为永久代内存不足,而且永久代只有触发FullGC时候才会执行他的垃圾回收,但是FullGC只有等到整个老年代的空间不足才会触发,回收时间会很晚,间接的导致stringtable的回收效率并不高,所以1.6之后的JVM厂商对此作了优化
![]()
StringTable 性能调优
最后分享StringTable的性能调优问题,由于stringtable是桶机制,所以我们需要调整桶的个数,具体数据根据自己硬件以及合适的占比去调整
调整 -XX:StringTableSize=桶个数
总结
通过本章至少了解到方法区的以下问题
1. 定义
2. 组成
3. 方法区内存溢出
4. 运行时常量池
5. StringTable 特性
6. StringTable 位置
7. StringTable 性能调优
关于方法区的详细介绍本章到此,下一篇介绍 直接内存
希望同仁志士,前来参考以及指点!共同进步,发扬文化精神!转载请标明出处!
感觉不错的点个赞关注一下吧!