@[toc] 本文是松哥所录视频教程的一个笔记,笔记简明扼要,完整内容小伙伴们可以参考视频,视频下载链接:https://pan.baidu.com/s/1NHoe0_52ut9fDUh0A6UQLA 提取码: kzv7
![]()
1.ElasticSearch 分词器介绍
1.1 内置分词器
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤:
- 词条化:分词器将输入的文本转为一个一个的词条流。
- 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等。
ElasticSearch 中内置了多种分词器可以供使用。
内置分词器:
| 分词器 |
作用 |
| Standard Analyzer |
标准分词器,适用于英语等。 |
| Simple Analyzer |
简单分词器,基于非字母字符进行分词,单词会被转为小写字母。 |
| Whitespace Analyzer |
空格分词器。按照空格进行切分。 |
| Stop Analyzer |
类似于简单分词器,但是增加了停用词的功能。 |
| Keyword Analyzer |
关键词分词器,输入文本等于输出文本。 |
| Pattern Analyzer |
利用正则表达式对文本进行切分,支持停用词。 |
| Language Analyzer |
针对特定语言的分词器。 |
| Fingerprint Analyzer |
指纹分析仪分词器,通过创建标记进行重复检测。 |
1.2 中文分词器
在 Es 中,使用较多的中文分词器是 elasticsearch-analysis-ik,这个是 es 的一个第三方插件,代码托管在 GitHub 上:
1.2.1 安装
两种使用方式:
第一种:
- 首先打开分词器官网:https://github.com/medcl/elasticsearch-analysis-ik。
- 在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到最新的正式版,下载下来。我们这里的下载链接是 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip。
- 将下载文件解压。
- 在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
- 重启 es 服务。
第二种:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
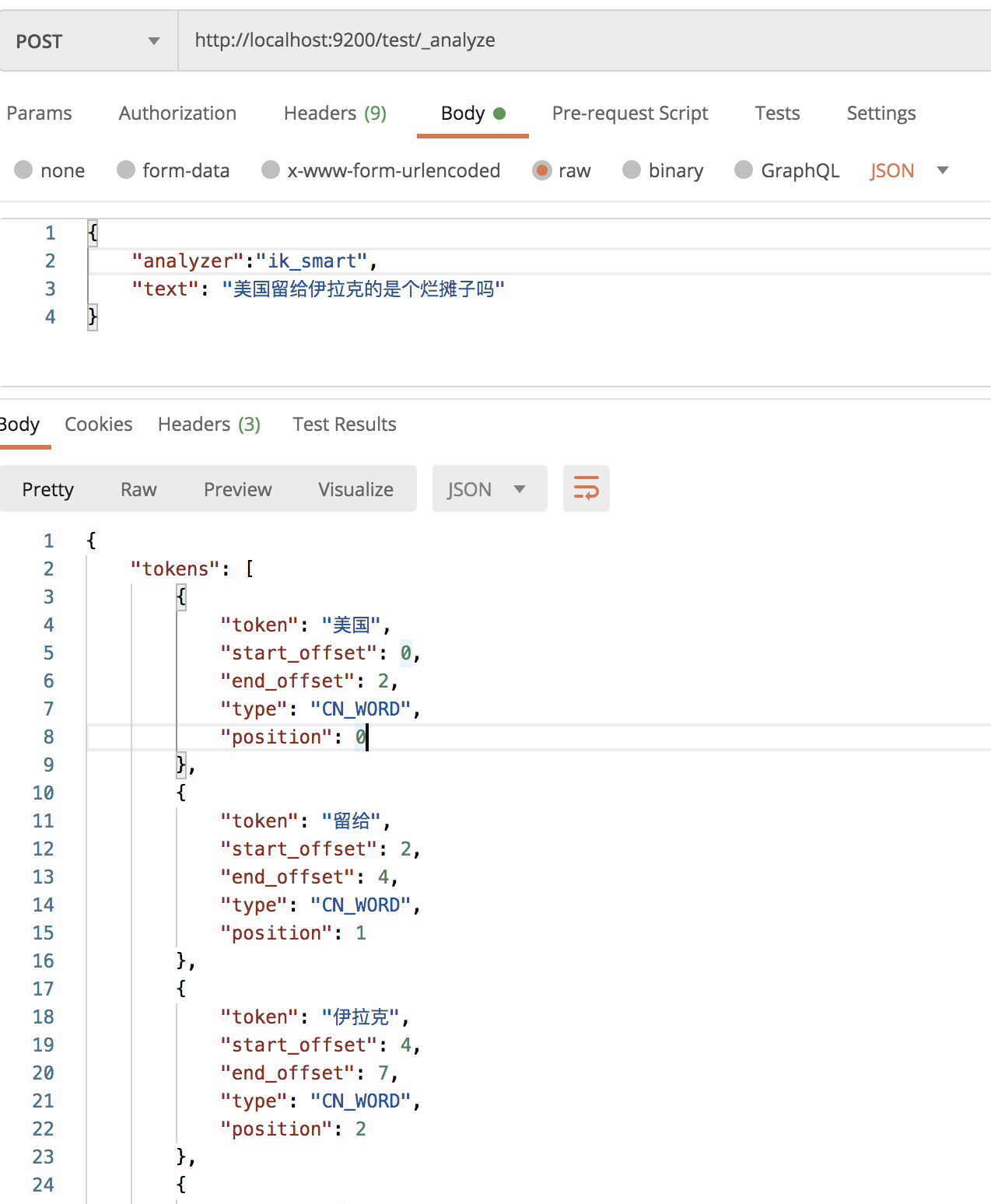
1.2.2 测试
es 重启成功后,首先创建一个名为 test 的索引:
![]()
接下来,在该索引中进行分词测试:
![]()
1.2.3 自定义扩展词库
1.2.3.1 本地自定义
在 es/plugins/ik/config 目录下,新建 ext.dic 文件(文件名任意),在该文件中可以配置自定义的词库。
![]()
如果有多个词,换行写入新词即可。
然后在 es/plugins/ik/config/IKAnalyzer.cfg.xml 中配置扩展词典的位置:
![]()
1.2.3.2 远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件,写入扩展词:
![]()
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:
![]()
配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展辞典。
视频笔记,在公众号江南一点雨后台回复 elasticsearch04 获取下载链接。
2. ElasticSearch 索引管理
微信公众号江南一点雨后台回复 elasticsearch05 下载本笔记。
启动一个 master 节点和两个 slave 节点进行测试(参考第二集的视频搭建)。
2.1 新建索引
2.1.1 通过 head 插件新建索引
在 head 插件中,选择 索引选项卡,然后点击新建索引。新建索引时,需要填入索引名称、分片数以及副本数。
![]()
索引创建成功后,如下图:
![]()
0、1、2、3、4 分别表示索引的分片,粗框表示主分片,细框表示副本(点一下框,通过 primary 属性可以查看是主分片还是副本)。.kibana 索引只有一个分片和一个副本,所以只有 0。
2.1.2 通过请求创建
可以通过 postman 发送请求,也可以通过 kibana 发送请求,由于 kibana 有提示,所以这里采用 kibana。
创建索引请求:
PUT book
创建成功后,可以查看索引信息:
![]()
需要注意两点:
![]()
![]()
2.2 更新索引
索引创建好之后,可以修改其属性。
例如修改索引的副本数:
PUT book/_settings
{
"number_of_replicas": 2
}
修改成功后,如下:
![]()
更新分片数也是一样。
2.3 修改索引的读写权限
索引创建成功后,可以向索引中写入文档:
PUT book/_doc/1
{
"title":"三国演义"
}
写入成功后,可以在 head 插件中查看:
![]()
默认情况下,索引是具备读写权限的,当然这个读写权限可以关闭。
例如,关闭索引的写权限:
PUT book/_settings
{
"blocks.write": true
}
关闭之后,就无法添加文档了。关闭了写权限之后,如果想要再次打开,方式如下:
PUT book/_settings
{
"blocks.write": false
}
其他类似的权限有:
- blocks.write
- blocks.read
- blocks.read_only
2.4 查看索引
head 插件查看方式如下:
![]()
请求查看方式如下:
GET book/_settings
也可以同时查看多个索引信息:
GET book,test/_settings
也可以查看所有索引信息:
GET _all/_settings
2.5 删除索引
head 插件可以删除索引:
![]()
请求删除如下:
DELETE test
删除一个不存在的索引会报错。
5.6 索引打开/关闭
关闭索引:
POST book/_close
打开索引:
POST book/_open
当然,可以同时关闭/打开多个索引,多个索引用 , 隔开,或者直接使用 _all 代表所有索引。
2.7 复制索引
索引复制,只会复制数据,不会复制索引配置。
POST _reindex
{
"source": {"index":"book"},
"dest": {"index":"book_new"}
}
复制的时候,可以添加查询条件。
2.8 索引别名
可以为索引创建别名,如果这个别名是唯一的,该别名可以代替索引名称。
POST /_aliases
{
"actions": [
{
"add": {
"index": "book",
"alias": "book_alias"
}
}
]
}
添加结果如下:
![]()
将 add 改为 remove 就表示移除别名:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "book",
"alias": "book_alias"
}
}
]
}
查看某一个索引的别名:
GET /book/_alias
查看某一个别名对应的索引(book_alias 表示一个别名):
GET /book_alias/_alias
可以查看集群上所有可用别名:
GET /_alias
最后,松哥还搜集了 50+ 个项目需求文档,想做个项目练练手的小伙伴不妨看看哦~
![]()
![]()
![]()
需求文档地址:https://github.com/lenve/javadoc