
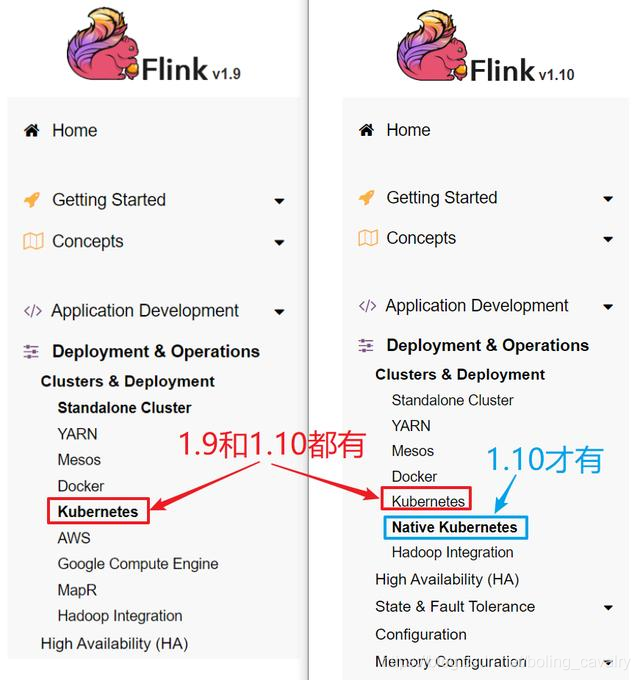


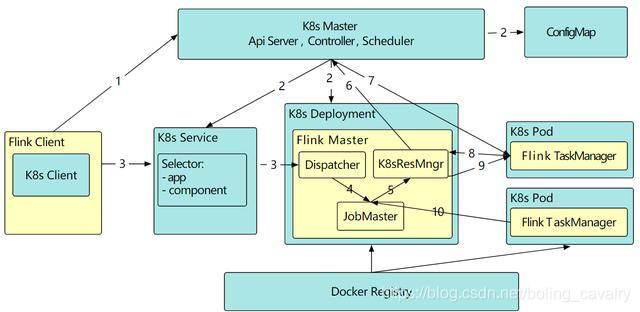
 准备完毕,开始实战了~
准备完毕,开始实战了~
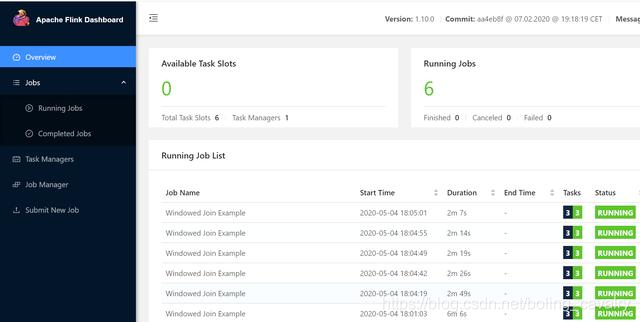
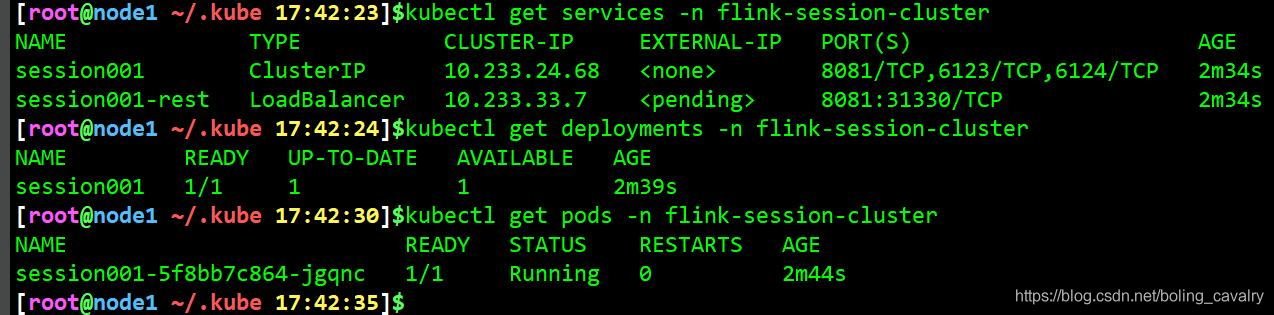 9. pod启动成功后访问flink web,如下图,此时还没有创建TaskManager,因此Slot为零:
9. pod启动成功后访问flink web,如下图,此时还没有创建TaskManager,因此Slot为零: 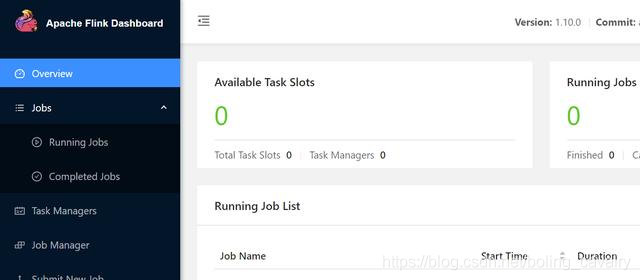 10. 回到CentOS7电脑,在flink目录下执行以下命令,将官方自带的<font color="blue">WindowJoin</font>任务提交到session cluster:
10. 回到CentOS7电脑,在flink目录下执行以下命令,将官方自带的<font color="blue">WindowJoin</font>任务提交到session cluster:
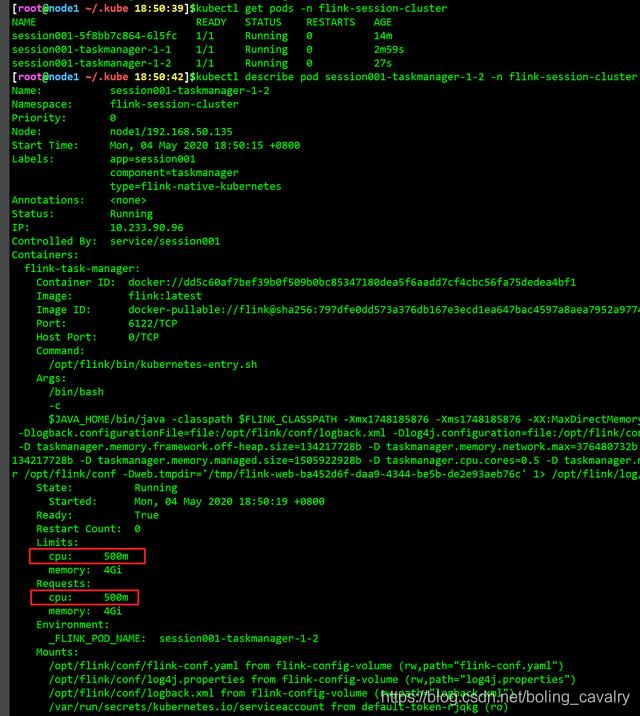
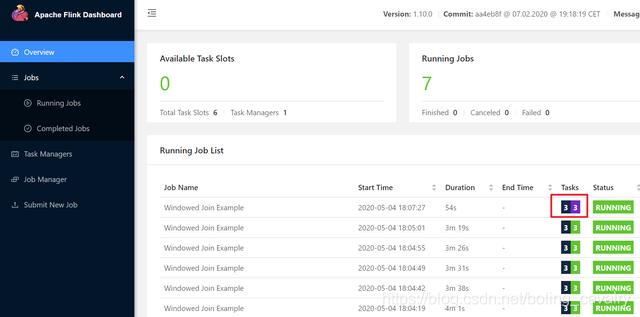 15. 在kubernetes环境查看pod情况,如下图红框所示,有个新建的pod状态是Pending,看来这就是第七个任务不能执行就是因为这个新建的pod无法正常工作导致的:
15. 在kubernetes环境查看pod情况,如下图红框所示,有个新建的pod状态是Pending,看来这就是第七个任务不能执行就是因为这个新建的pod无法正常工作导致的:  16. 再看看这个namespace的事件通知,如下图红框所示,名为session001-taskmanager-1-2的pod有一条通知信息:<font color="blue">由于CPU资源不足导致pod创建失败</font>:
16. 再看看这个namespace的事件通知,如下图红框所示,名为session001-taskmanager-1-2的pod有一条通知信息:<font color="blue">由于CPU资源不足导致pod创建失败</font>:  17. 穷到没钱配置kubernetes环境,连一核CPU都凑不齐:
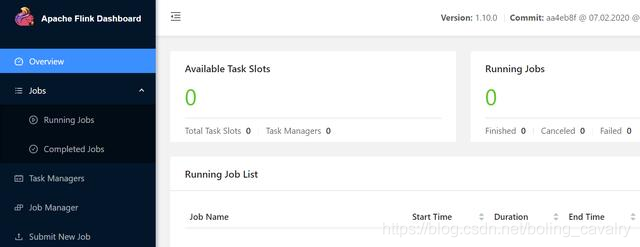
17. 穷到没钱配置kubernetes环境,连一核CPU都凑不齐: 18. 一时半会儿也找不出多余的CPU资源,唯一能做的就是降低TaskManager的CPU要求,刚才配置的是一个TaskManager使用一核CPU,我打算降低一半,即<font color="red">0.5核</font>,这样就够两个TaskManager用了; 19. 您可能会疑惑:怎么会有0.5个CPU这样的配置?这个和kubernetes的资源限制有关,kubernetes对pod的CPU限制粒度是千分之一个CPU,也是就是在kubernetes中,配置1000单位的CPU表示使用1核,我们配置0.5核,不过是配置了500单位而已(所以我还可以更穷....) 20. 接下来的操作是先停掉当前的session cluster,再重新创建一个,创建的时候参数<font color="blue">-Dkubernetes.taskmanager.cpu</font>的值从1改为<font color="red">0.5</font> 21. 在CentOS7电脑上执行以下命令,将session cluster停掉,释放所有资源:
18. 一时半会儿也找不出多余的CPU资源,唯一能做的就是降低TaskManager的CPU要求,刚才配置的是一个TaskManager使用一核CPU,我打算降低一半,即<font color="red">0.5核</font>,这样就够两个TaskManager用了; 19. 您可能会疑惑:怎么会有0.5个CPU这样的配置?这个和kubernetes的资源限制有关,kubernetes对pod的CPU限制粒度是千分之一个CPU,也是就是在kubernetes中,配置1000单位的CPU表示使用1核,我们配置0.5核,不过是配置了500单位而已(所以我还可以更穷....) 20. 接下来的操作是先停掉当前的session cluster,再重新创建一个,创建的时候参数<font color="blue">-Dkubernetes.taskmanager.cpu</font>的值从1改为<font color="red">0.5</font> 21. 在CentOS7电脑上执行以下命令,将session cluster停掉,释放所有资源:

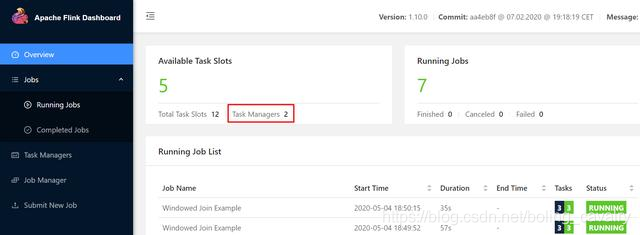
 这里再提醒一下,降低CPU用量,意味着该pod中的进程获取的CPU执行时间被降低,会导致任务执行变慢,所以这种方法不可取,正确的思路是确保硬件资源能满足业务需求(像我这样穷到一核CPU都凑不齐的情况还是不多的....)
这里再提醒一下,降低CPU用量,意味着该pod中的进程获取的CPU执行时间被降低,会导致任务执行变慢,所以这种方法不可取,正确的思路是确保硬件资源能满足业务需求(像我这样穷到一核CPU都凑不齐的情况还是不多的....)

深度揭秘垃圾回收底层,这次让你彻底弄懂她
大家好,我是 yes。 我们知道手动管理内存意味着自由、精细化地掌控,但是却极度依赖于开发人员的水平和细心程度。 如果使用完了忘记释放内存空间就会发生内存泄露,再如释放错了内存空间或者使用了悬垂指针则会发生无法预知的问题。 这时候 Java 带着 GC 来了(GC,Garbage Collection 垃圾收集,早于 Java 提出),将内存的管理交给 GC 来做,减轻了程序员编程的负担,提升了开发效率。 所以并不是用 Java 就不需要内存管理了,只是因为 GC 在替我们负重前行。 但是 GC 并不是那么万能的,不同场景适用不同的 GC 算法,需要设置不同的参数,所以我们不能就这样撒手不管了,只有深入地理解它才能用好它。 关于 GC 内容相信很多人都有所了解。我最早得知有关 GC 的知识是来自《深入理解Java虚拟机》,但是有关 GC 的内容单看这本书是不够的。 当时我以为我懂很多了,后来经过了一番教育之后才知道啥叫无知者无畏。 而且过了一段时间很多有关 GC 的内容都说不上来了,其实也有很多同学反映有些知识学了就忘,有些内容当时是理解的,过一段时间啥都不记得了。 大部分情况是因为这...