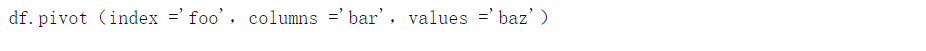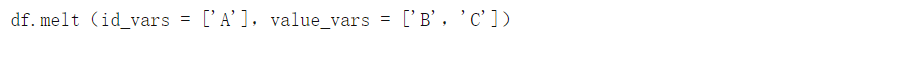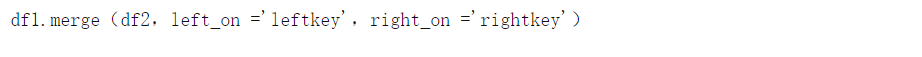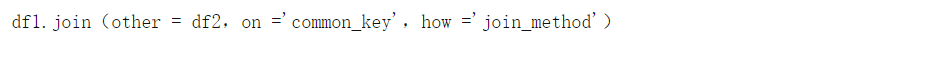大多数数据科学家可能会赞扬Pandas进行数据准备的能力,但许多人可能无法利用所有这些能力。操作数据帧可能很快会成为一项复杂的任务,因此在Pandas中的八种技术中均提供了说明,可视化,代码和技巧来记住如何做。
Pandas提供了各种各样的DataFrame操作,但是其中许多操作很复杂,而且似乎不太平易近人。本文介绍了8种基本的DataFrame操作方法,它们涵盖了数据科学家需要知道的几乎所有操作功能。每种方法都将包括说明,可视化,代码以及记住它的技巧。
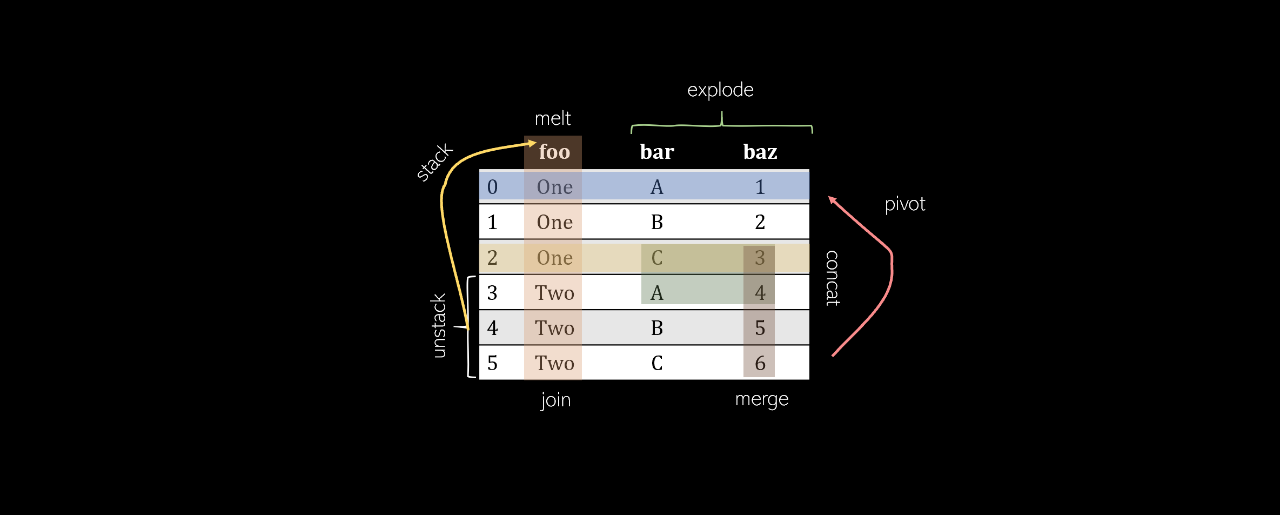
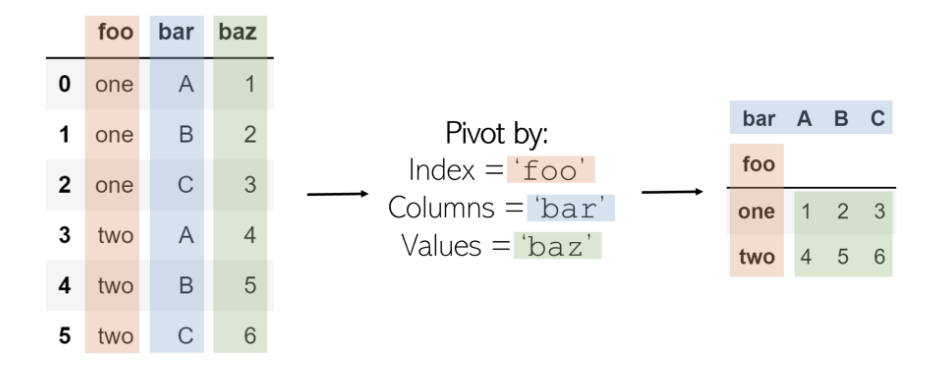
Pivot
透视表将创建一个新的“透视表”,该透视表将数据中的现有列投影为新表的元素,包括索引,列和值。初始DataFrame中将成为索引的列,并且这些列显示为唯一值,而这两列的组合将显示为值。这意味着Pivot无法处理重复的值。
旋转名为df 的DataFrame的代码 如下:
记住:Pivot——是在数据处理领域之外——围绕某种对象的转向。在体育运动中,人们可以绕着脚“旋转”旋转:大熊猫的旋转类似于。原始DataFrame的状态围绕DataFrame的中心元素旋转到一个新元素。有些元素实际上是在旋转或变换的(例如,列“ bar ”),因此很重要。
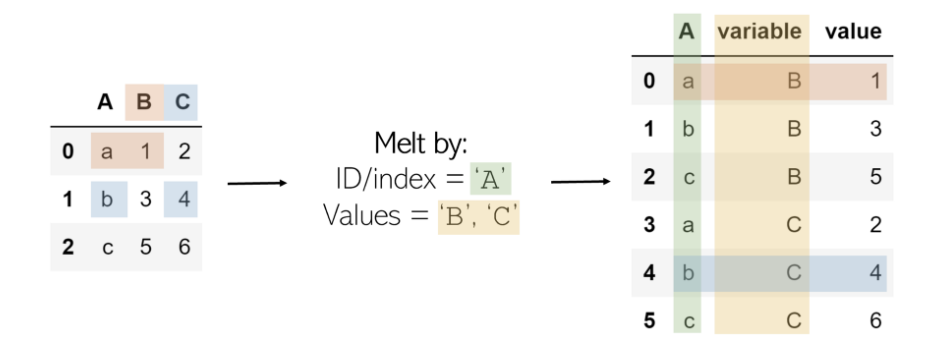
Melt
Melt可以被认为是“不可透视的”,因为它将基于矩阵的数据(具有二维)转换为基于列表的数据(列表示值,行表示唯一的数据点),而枢轴则相反。考虑一个二维矩阵,其一维为“ B ”和“ C ”(列名),另一维为“ a”,“ b ”和“ c ”(行索引)。
我们选择一个ID,一个维度和一个包含值的列/列。包含值的列将转换为两列:一列用于变量(值列的名称),另一列用于值(变量中包含的数字)。
结果是ID列的值(a,b,c)和值列(B,C)及其对应值的每种组合,以列表格式组织。
可以像在DataFrame df上一样执行Mels操作 :
记住:像蜡烛一样融化(Melt)就是将凝固的复合物体变成几个更小的单个元素(蜡滴)。融合二维DataFrame可以解压缩其固化的结构并将其片段记录为列表中的各个条目。
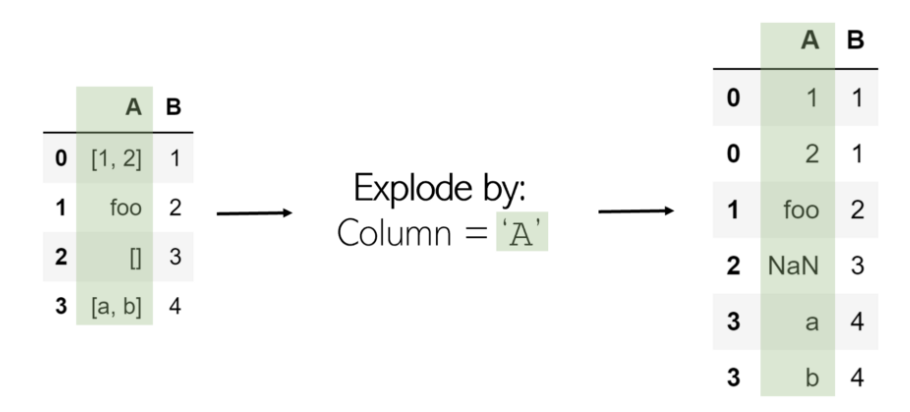
Explode是一种摆脱数据列表的有用方法。当一列爆炸时,其中的所有列表将作为新行列在同一索引下(为防止发生这种情况, 此后只需调用 .reset_index()即可)。诸如字符串或数字之类的非列表项不受影响,空列表是NaN值(您可以使用.dropna()清除它们 )。
在DataFrame df中Explode列“ A ” 非常简单:
要记住:Explode某物会释放其所有内部内容-Explode列表会分隔其元素。
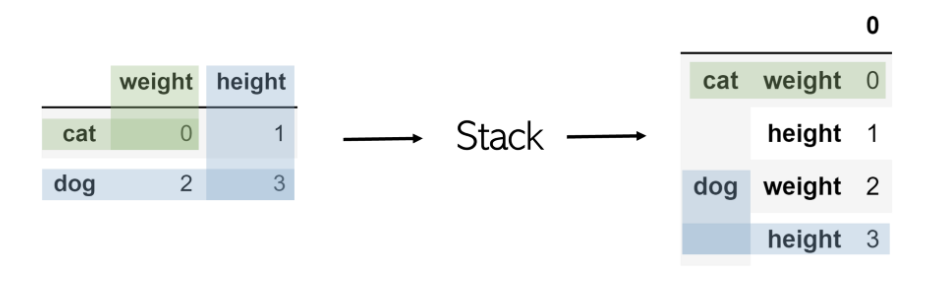
Stack
堆叠采用任意大小的DataFrame,并将列“堆叠”为现有索引的子索引。因此,所得的DataFrame仅具有一列和两级索引。
堆叠名为df的表就像df.stack()一样简单 。
为了访问狗的身高值,只需两次调用基于索引的检索,例如 df.loc ['dog']。loc ['height']。
要记住:从外观上看,堆栈采用表的二维性并将列堆栈为多级索引。
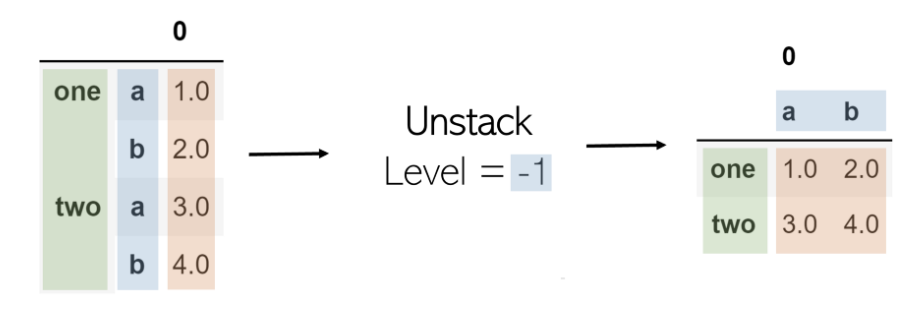
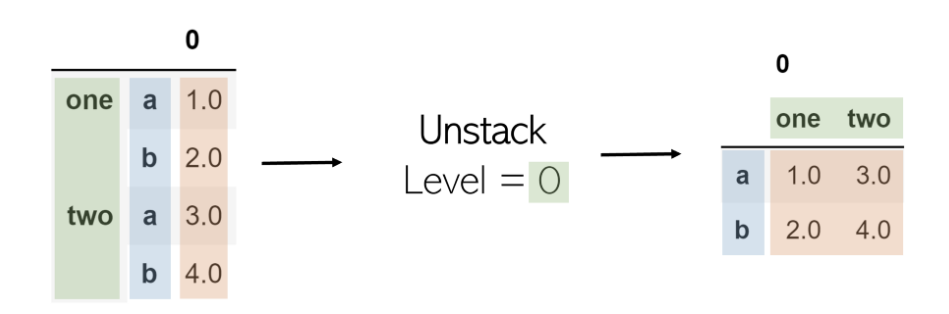
Unstack
取消堆叠将获取多索引DataFrame并对其进行堆叠,将指定级别的索引转换为具有相应值的新DataFrame的列。在表上调用堆栈后再调用堆栈不会更改该堆栈(原因是存在“ 0 ”)。
堆叠中的参数是其级别。在列表索引中,索引为-1将返回最后一个元素。这与水平相同。级别-1表示将取消堆叠最后一个索引级别(最右边的一个)。作为另一个示例,当级别设置为0(第一个索引级别)时,其中的值将成为列,而随后的索引级别(第二个索引级别)将成为转换后的DataFrame的索引。
可以按照与堆叠相同的方式执行堆叠,但是要使用level参数: df.unstack(level = -1)。
Merge
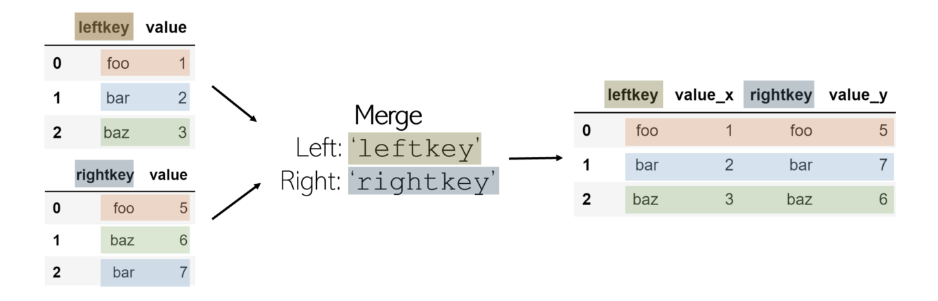
合并两个DataFrame是在共享的“键”之间按列(水平)组合它们。此键允许将表合并,即使它们的排序方式不一样。完成的合并DataFrame 默认情况下会将后缀_x 和 _y添加 到value列。
为了合并两个DataFrame df1 和 df2 (其中 df1 包含 leftkey, 而 df2 包含 rightkey),请调用:
合并不是pandas的功能,而是附加到DataFrame。始终假定合并所在的DataFrame是“左表”,在函数中作为参数调用的DataFrame是“右表”,并带有相应的键。
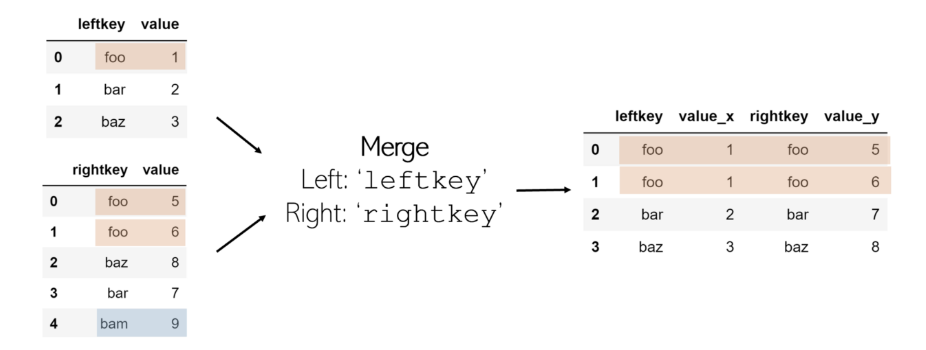
默认情况下,合并功能执行内部联接:如果每个DataFrame的键名均未列在另一个键中,则该键不包含在合并的DataFrame中。另一方面,如果一个键在同一DataFrame中列出两次,则在合并表中将列出同一键的每个值组合。例如,如果 df1 具有3个键foo 值, 而 df2 具有2个相同键的值,则 在最终DataFrame中将有6个条目,其中 leftkey = foo 和 rightkey = foo。
记住:合并数据帧就像在水平行驶时合并车道一样。想象一下,每一列都是高速公路上的一条车道。为了合并,它们必须水平合并。
Join
通常,联接比合并更可取,因为它具有更简洁的语法,并且在水平连接两个DataFrame时具有更大的可能性。连接的语法如下:
使用联接时,公共键列(类似于 合并中的right_on 和 left_on)必须命名为相同的名称。how参数是一个字符串,它表示四种连接 方法之一, 可以合并两个DataFrame:
-
' left ':包括df1的所有元素, 仅当其键为df1的键时才 包含df2的元素 。否则,df2的合并DataFrame的丢失部分 将被标记为NaN。
-
' right ':' left ',但在另一个DataFrame上。包括df2的所有元素, 仅当其键是df2的键时才 包含df1的元素 。
-
“outer”:包括来自DataFrames所有元素,即使密钥不存在于其他的-缺少的元素被标记为NaN的。
-
“inner”:仅包含元件的键是存在于两个数据帧键(交集)。默认合并。
记住:如果您使用过SQL,则单词“ join”应立即与按列添加相联系。如果不是,则“ join”和“ merge”在定义方面具有非常相似的含义。
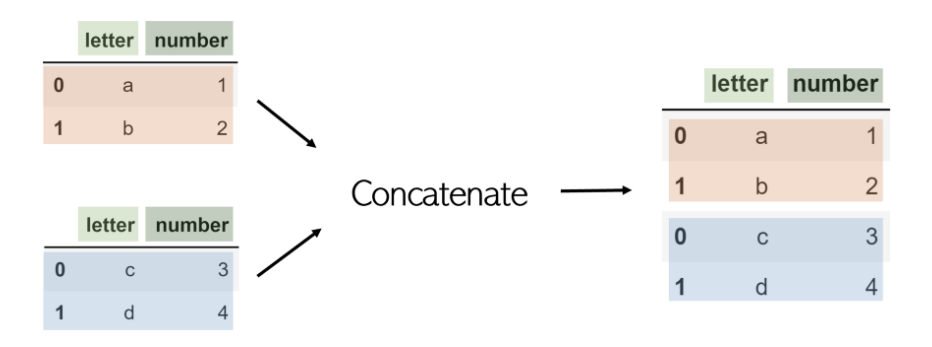
Concat
合并和连接是水平工作,串联或简称为concat,而DataFrame是按行(垂直)连接的。例如,考虑使用pandas.concat([df1,df2])串联的具有相同列名的 两个DataFrame df1 和 df2 :
尽管可以通过将axis参数设置为1来使用concat进行列式联接,但是使用联接 会更容易。
请注意,concat是pandas函数,而不是DataFrame之一。因此,它接受要连接的DataFrame列表。
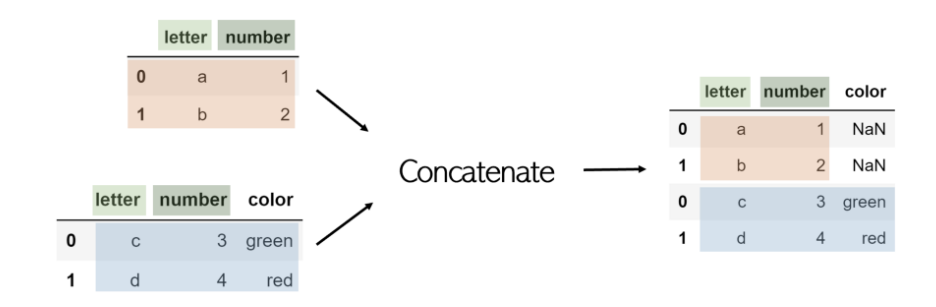
如果一个DataFrame的另一列未包含,默认情况下将包含该列,缺失值列为NaN。为了防止这种情况,请添加一个附加参数join ='inner',该参数 只会串联两个DataFrame共有的列。
切记:在列表和字符串中,可以串联其他项。串联是将附加元素附加到现有主体上,而不是添加新信息(就像逐列联接一样)。由于每个索引/行都是一个单独的项目,因此串联将其他项目添加到DataFrame中,这可以看作是行的列表。
Append是组合两个DataFrame的另一种方法,但它执行的功能与concat相同,效率较低且用途广泛。
如果您喜欢的话欢迎点赞转发!
往期精彩链接:
Github文件在线加速下载
进阶Python开发(PDF版开源了)
看完别走还有惊喜!
我精心整理了计算机/Python/机器学习/深度学习相关的2TB视频课与书籍,价值1W元。关注微信公众号“计算机与AI”,点击下方菜单即可获取网盘链接。