![]()
以前也零零碎碎发过一些HashMap的文章,这次简短总结一下有关HashMap的重要考点,这也是求职面试的经常问的,看完记得点个赞和在看哦~
1、Hash的概念
将任意长度的输入通过散列算法之后映射成固定长度的输出。
2、Hash冲突
当关键字集合很大时(key的数量很多的时候),关键字值不同的元素可能会映像到哈希表的同一地址上,即K1!=K2,但f(K1)=f(K2),这种现象称为hash冲突,实际中冲突是不可避免的,只能通过改进哈希函数的性能来减少冲突。
3、你认为好的Hash算法的点应该有哪些?
(1)效率得高,做到长文本也能高效计算出Hash值
(2)根据Hash值不能逆推出原文
(3)两次输入,如果有一点不同也得保证Hash值是不同的
(4)尽可能要分散,因为在table中slot大部分都处于空闲状态时要尽可能降低Hash冲突
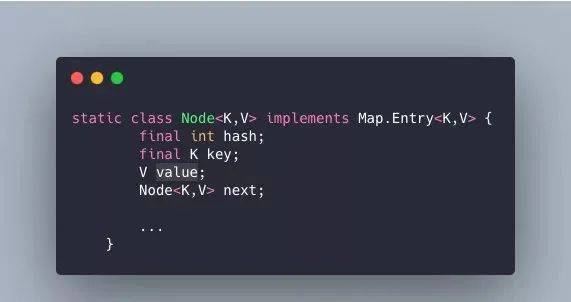
4、HashMap的存储结构长啥样?
JDK1.8:
(1)数组+链表+红黑树构成,每个数据单元为一个Node结构,Node结构中有key字段、value字段、next字段、hash字段
(2)next字段就是发生Hash冲突的时候,当前桶位中的Node与冲突Node连接成一个链表所需要的字段
![]()
![]() JDK1.7:
JDK1.7:
数组+链表
45、如果创建HashMap的时候没有指定HashMap散列表的长度,初始长度为多少?
在JDK 8中,关于默认容量的定义为:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //16 ,其故意把16写成1<<4,就是提醒开发者,这个地方要是2的幂。
(1)为啥用位运算呢?直接写16不好么?
这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。
(2)那为啥用16不用别的呢?
因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率,太大了又浪费空间,不划算。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。
6、散列表是New HashMap()的时候创建的,还是什么时候创建的?
散列表是懒加载机制,只有在第一次put数据的时候才创建(JDK1.8,JDK1.7是直接加载散列表)
7、负载因子默认是多少,有啥作用?为什么负载因子为0.75?什么时候进行扩容(resize)?
(1)默认为0.75,用于计算扩容阈值
(2)loadFactor是负载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
(3)影响扩容主要有两个因素:
Capacity:HashMap当前长度。
LoadFactor:负载因子,默认值0.75f。
怎么理解呢,就比如当前的容量大小为100,当你存进第76个的时候,判断发现大于扩容阈值100*0.75=75需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
8、扩容?它是怎么扩容的呢?
分为两步
(1)扩容:创建一个新的Entry空数组,长度是原数组的2倍。
(2)ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,直接复制过去不香么?
是因为长度扩大以后,Hash的规则也随之改变。
![]()
比如原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
9、链表转化为红黑树的条件
(1)链表长度达到8
(2)当前散列表长度达到64
以上两个条件同时满足链表才会转化为红黑树,如果仅仅链表长度达到8,它不会发生链表转红黑树,只会发生一次散列表扩容(resize)
10、Node对象里面的hash字段的值是key对象的hashcode的返回值吗?
不是的,通过key的hashcode的高16位异或低16位得到的新值,这样即使数组table的length比较小的时候,也能保证高低bit都参与到Hash的计算中,避免高16位浪费没起到作用,尽可能的得到一个均匀分布的hash。
11、为啥我们重写equals方法的时候需要重写hashCode方法呢?你能用HashMap给我举个例子么?
因为在java中,所有的对象都是继承于Object类。Ojbect类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了object的equals方法,那里的 equals是比较两个对象的内存地址,显然我们new了2个对象内存地址肯定不一样
比如发生Hash冲突的时候,我们去get,他就是根据key去hash然后计算出index,找到了2,那我怎么找到具体的”电脑“还是”脑电“呢?
equals!是的,所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
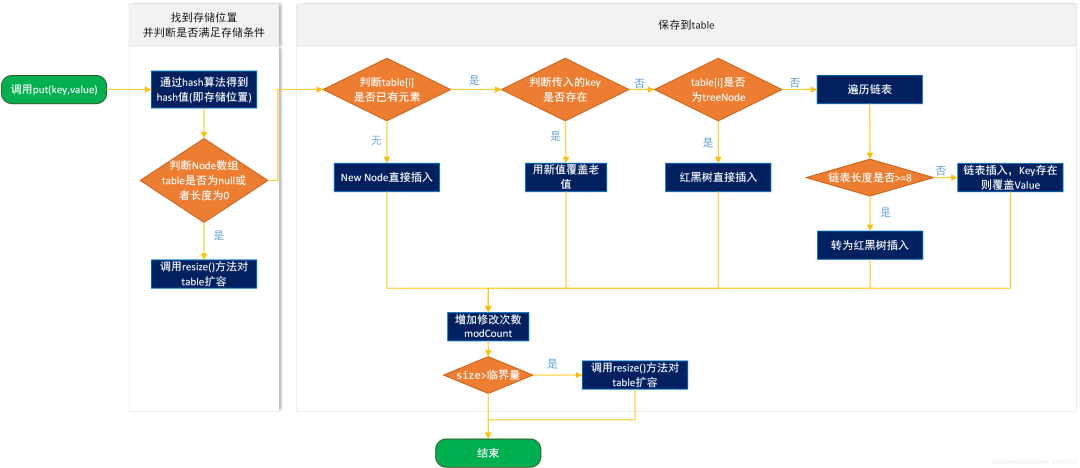
12、HashMap的put数据的流程
![]()
13、为什么java8以后链表数据超过8以后,就改成红黑树存储?
这就涉及到拒接服务攻击了,比如某些人通过找到你的hash碰撞值,来让你的HashMap不断地产生碰撞,那么相同key位置的链表就会不断增长,当你需要对这个HashMap的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。java8使用红黑树来替代超过8个节点数的链表后,查询方式性能得到了很好的提升,从原来的是O(n)到O(logn),容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小(约为10万分之一),所以作者应该是根据概率统计而选择了8作为阀值。
14、Hashmap的结构,1.7和1.8有哪些区别?
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?
因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(2)扩容后数据存储位置的计算方式也不一样:1. 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
15、首先HashMap是线程不安全的,其主要体现在哪里?
(1)在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
(2)在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。