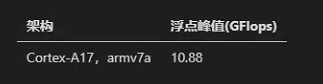
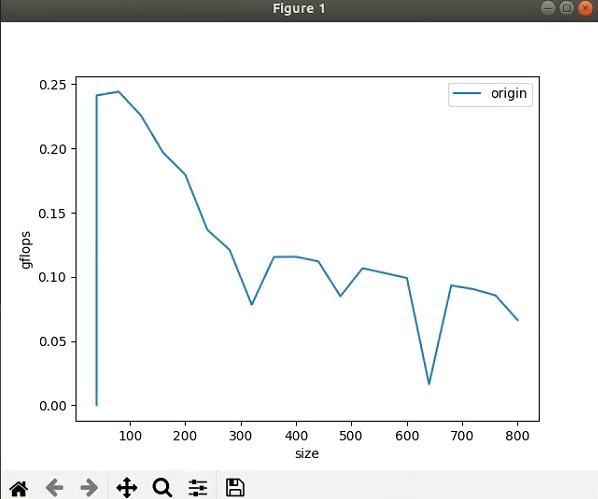
接着,我们参考https://github.com/flame/how-to-optimize-gemm来实现一个Native版的矩阵乘法,即A矩阵的一行乘以B矩阵的一列获得C矩阵的一个元素(计算量为2 * M * N * K),并统计它的运算时间以计算gflops,另外为了发现矩阵乘法的gflops和矩阵尺寸的关系,我们将各个尺寸的矩阵乘法的gflops写到一个txt文件里面,后面我们使用Python的matplotlib库把这些数据画到一张图上显示出来。首先实现不同尺寸的矩阵乘法:
#define A( i, j ) a[ (i)*lda + (j) ] #define B( i, j ) b[ (i)*ldb + (j) ] #define C( i, j ) c[ (i)*ldb + (j) ] // gemm C = A * B + C voidMatrixMultiply(int m, int n, int k, float *a, int lda, float *b, int ldb, float *c, int ldc) { for(int i = 0; i < m; i++){ for (int j=0; j<n; j++ ){ for (int p=0; p<k; p++ ){ C(i, j) = C(i, j) + A(i, p) * B(p, j); } } } }
// i代表当前矩阵的长宽,长宽都等于i for(int i = 40; i <= 800; i += 40){ m = i; n = i; k = i; gflops = 2.0 * m * n * k * 1.0e-09; lda = m; ldb = n; ldc = k; a = (float *)malloc(lda * k * sizeof(float)); b = (float *)malloc(ldb * n * sizeof(float)); c = (float *)malloc(ldc * n * sizeof(float)); prec = (float *)malloc(ldc * n * sizeof(float)); nowc = (float *)malloc(ldc * n * sizeof(float)); // 随机填充矩阵 random_matrix(m, k, a, lda); random_matrix(k, n, b, ldb); random_matrix(m, n, prec, ldc);
memset(prec, 0, ldc * n * sizeof(float));
copy_matrix(m, n, prec, ldc, nowc, ldc);
// 以nowc为基准,判断矩阵运行算结果是否正确 MatrixMultiply(m, n, k, a, lda, b, ldb, nowc, ldc);
import matplotlib.pyplot as plt import numpy as np
defsolve(filename): f = open(filename) sizes = [40] times = [0.0] title = 'origin' whileTrue: line = f.readline() if line: slices = line.split(" ") if len(slices) <= 2: break; size = int(slices[0]) time = float(slices[1]) sizes.append(size) times.append(time) return title, sizes, times
if __name__ == '__main__': plt.xlabel('size') plt.ylabel('gflops') t, x, y = solve('now.txt') plt.plot(x, y, label=t) plt.legend() plt.savefig('origin.png') plt.show()
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。