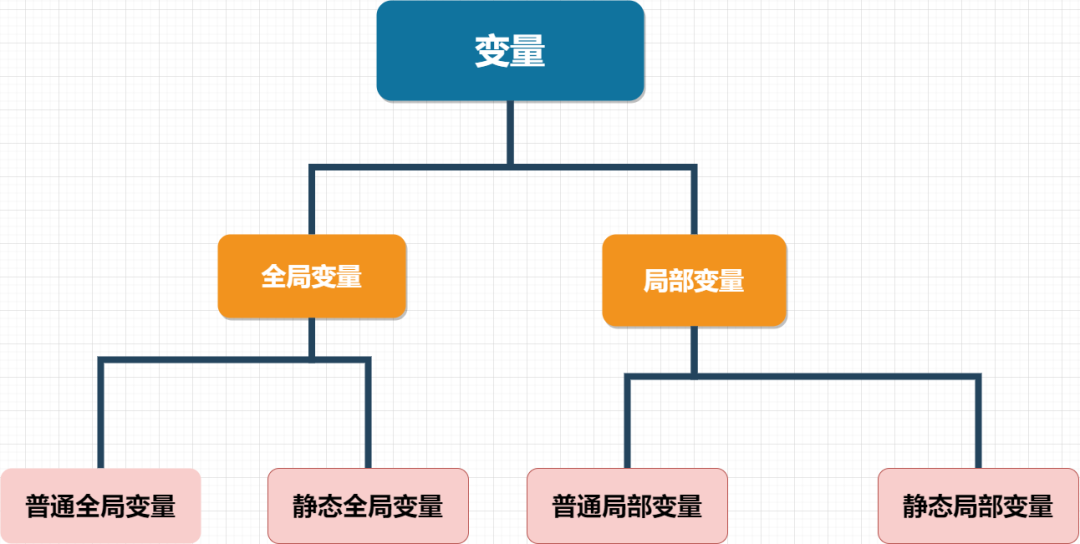
变量一般可以细分为如下图:
本节重点为了让大家理解内存模型的“栈”,暂时不考虑“静态变量” 的情况,并约定如下:
“全局变量”仅仅默认为“普通全局变量”;
“局部变量”仅仅默认为“普通局部变量”。
简单直观的来说,全局变量就是在函数外面定义的变量,局部变量就是在函数内部定义的变量,下面的例子能很清晰地说明全局变量和局部变量的判定方法:
unsigned char a; //在函数外面定义的, 所以是全局变量。while (1)单片机内存包括ROM和RAM 两部分,ROM存储的是单片机程序中的指令和一些不可更改的常量数据,而 RAM存放的是可以被更改的变量数据;
也就是说,全局变量和局部变量都是存放在RAM,但是,虽然都是存放在 RAM,全局变量和局部变量之间的内存模型还是有明显的区别的。
因此,分了两个不同的RAM区,全局变量占用的 RAM区称为全局数据区 , 局部变量占用的 RAM 区称为栈 。
全局数据区 就像你自己家的房间,是唯一的,一个房间的地址只能你一个人住(假设你还是单身狗的时候),而且是永久的(sorry),所以说每个全局变量都有唯一对应的 RAM 地址, 不可能重复的。
栈 就像客栈, 一年下来每天晚上住的人不一样,每个人在里面居住的时间是有期限的,不是长久的,一个房间的地址一年下来每天可能住进不同的人,不是唯一的。
全局数据区 的全局变量拥有永久产权,栈 区的局部变量只能临时居住在宾馆客栈, 地址不是唯一的, 有期限的。
栈 是给程序里所有函数内部的局部变量共用的,函数被调用的时候,该函数内部的每个局部变量就会被分配对应到栈 的某个RAM 地址,函数调用结束后,该局部变量就失效。
因此它对应的栈 的RAM空间就被收回,以便给下一个被调用的函数的局部变量占用。
void function (void); //子函数的声明function (void) //子函数的定义function () ; //子函数的调用我们看到单片机从主函数 main 往下执行, 首先遇到function()子函数的调用, 所以就跳到function()函数的定义那里开始执行, 此时的局部变量 a 开始被分配在 RAM的“栈区” 的某个地址, 相当于你入住宾馆被分配到某个房间。
单片机执行完子函数function() 后,局部变量 a 在 RAM 的栈区所分配的地址被收回, 局部变量a 消失,被收回的RAM地址可能会被系统重新分配给其它被调用的函数的局部变量。
此时相当于你离开宾馆,从此你跟那个宾馆的房间没有啥关系, 你原来在宾馆入住的那个房间会被宾馆老板重新分配给其他的客人入住。
全局变量的作用域是永久性不受范围限制的,而局部变量的作用域就是它所在函数的内部范围。全局变量的全局数据区是永久的私人房子,局部变量的栈是临时居住的客栈。
每定义一个新的全局变量,就意味着多开销一个新的RAM 内存。而每定义一个局部变量,只要在函数内部所定义的局部变量总数不超过单片机的栈区,此时的局部变量不开销新的 RAM内存, 因为局部变量是临时借用栈的, 使用后就还给栈,栈是公共区, 可以重复利用,可以服务若干个不同的函数内部的局部变量。
单片机每次进入执行函数时,局部变量都会被初始化改变,而全局变量则不会被初始化, 全局变量是一直保存之前最后一次更改的值。
全局数据区 和栈区 是谁在幕后分配的, 怎么分配的?是C编译器自动分配的, 至于怎么分配,谁分配多一点,谁分配少一点,C 编译器会有一个默认的比例分配, 我们一般都不用管。
栈区 是临时借用的,子函数被调用的时候,它内部的局部变量才会“临时” 被分配到“栈” 区的某个地址,那么问题来了,谁在幕后主持“栈区” 这些分配的工作?单片机已经上电开始运行程序的时候,编译器已经不起作用,“栈区” 分配给函数内部局部变量的工作,确实是 C 编译器做的,但这是在单片机上电前。
C 编译器就把所有函数内部的局部变量的分配工作就规划好了,都指定了如果某个函数一旦被调用,该函数内部的哪个局部变量应该分到“栈区” 的哪个地址,C 编译器都是事先把这些“后事” 都交代完毕了才结束自己的生命。
等单片机上电开始工作的时候,虽然C编译器此时不在了,但是单片机都是严格按照C编译器交代的遗嘱开始工作和分配“栈区”的。因此,“栈区” 的“临时分配” 非真正严格意义上的“临时分配”。
这种情况专业术语叫爆栈 。程序会出现莫名其妙的异常,后果特别严重。
为了避免这种情况, 一般在编写程序的时候, 函数内部都不能定义大数组的局部变量, 局部变量的数量不能定义太多太大,尤其要避免刚才所说的定义开辟大数组局部变量这种情况。
大数组的定义应该定义成全局变量,或者定义成 静态的局部变量 。
有一些C编译器,遇到“爆栈” 的情况,会好心跟你提醒让你编译不过去,但是也有一些 C 编译器可能就不会给你提醒,所以大家以后做项目写函数的时候,要对爆栈 心存敬畏。
刚才说到,全局变量的作用域是永久性并且不受范围限制的,而局部变量的作用域就是它所在函数的内部范围。
那么问题来了,假如局部变量和全局变量的名字重名了,此时函数内部执行的变量到底是局部变量还是全局变量?
这个问题就涉及到优先级。
注意 ,当面对同名的局部变量和全局变量时,函数内部执行的变量是局部变量,也就是局部变量在函数内部要比全局变量的优先级高。
unsigned char a=5; //此处第 1 个 a 是全局变量print (a); //把a发送到电脑端的串口助手软件上观察while (1)正确的答案是 2。在函数内部的局部变量比全局变量的优先级更加高。
虽然这里的两个a重名了, 但是它们的内存模型不一样,第1个全局变量的a是分配在全局数据区,是具有唯一的地址的,而第2个局部变量的a是被分配在临时的栈区的,寄生在 main 函数内部。
void function (void); //函数声明function (void) //函数定义function (); //子函数被调用print (a); //把 a 发送到电脑端的串口助手软件上观察。while (1)正确的答案是2。因为,function这个子函数是被调用结束之后,才执行 print(a)的, 就意味函数内部的局部变量(第2个局部变量 a)是在执行 print(a)语句的时候就消亡不存在了, 所以此时print(a)的a是第3个局部变量的a(在 main 函数内部定义的局部变量的 a)。
void function (void); //函数声明function (void) //函数定义function (); //子函数被调用print (a); //把a发送到电脑端的串口助手软件上观察while (1)正确的答案是5。因为function这个子函数是被调用结束之后,才执行print(a)的,就意味function函数内部的局部变量(第2个局部变量)是在执行function(a)语句的时候就消亡不存在了。
同时,因为此时main函数内部也没有定义a的局部变量,所以此时function(a)的a是必然只能是第1个全局变量的a(在main函数外面定义的全局变量的a)。
看到本文之后,相信大家已经对栈有了一些基础的认识,在嵌入式编程中,我们也要时刻注意,避免爆栈;如果有错误欢迎指出,我们下一期,再见。

 推荐阅读:
推荐阅读:

