前提 之前已经花了大量时间分析同步器框架AQS的源码实现,这篇文章分析一下CountDownLatch的源码实现,本文参看的JDK源码为JDK11,其他版本不一定适合。
❝
CountDownLatch其实是复合名词,由单词countdown和latch复合而来。countdown是倒数的意思,而latch则是闩锁、闭锁的意思,复合词容易让人联想到预先设定一个计数值,并且"锁住(阻塞)"一些东西(线程),然后进行倒数,当数值减少到0的时候进行"放行(解除阻塞)"。
❞
CountDownLatch是「AQS共享模式」 下的典型实现。本文会先简单介绍CountDownLatch的基本API、类比监视器方式的实现以及深入分析其源码实现。
CountDownLatch的基本使用 CountDownLatch的基本API如下:
// 构造函数,要求初始的计数值要大于零 public CountDownLatch (int count) ......// 当前调用线程会等待直到计数值倒数为0或者线程中断 public void await () throws InterruptedException ......// 当前调用线程会等待直到计数值倒数为0、线程中断或者超过输入的等待时间期限 public boolean await (long timeout, TimeUnit unit) throws InterruptedException ......// 计数值减少1,当计数值减少到0所有等待线程会释放(解除等待) public void countDown () ......// 获取计数值 public long getCount () ......由于count属性只在构造函数输入,它对应于AQS中的原子状态state,没有提供Setter方法去更新该原子状态,所以CountDownLatch的实例是"一次性使用的",即「不可二次使用的倒数闭锁」 。它的基本使用代码架构如下:
CountDownLatch doneSignal = new CountDownLatch(N);for (int i = 0 ; i < N; ++i) {new WorkerRunnable(doneSignal, i));class WorkerRunnable implements Runnable private final CountDownLatch doneSignal;private final int i;int i){ //setter } public void run () try {catch (InterruptedException ex) {}看一个例子:
public class CountDownLatchMain public static void main (String[] args) throws Exception final CountDownLatch latch = new CountDownLatch(3 );new Thread(() -> {"线程%s准备调用await方法......" , threadName));"线程%s解除阻塞继续运行......" , threadName));"thirdThread" ).start();500L );new Thread(() -> {"线程%s准备调用await方法......" , threadName));"线程%s解除阻塞继续运行......" , threadName));"firstThread" ).start();500L );new Thread(() -> {"线程%s准备调用await方法......" , threadName));"线程%s解除阻塞继续运行......" , threadName));"secondThread" ).start();500L );long count = latch.getCount();"main线程释放CountDownLatch......" );for (long i = 0 ; i < count; i++) {private static void await0 (CountDownLatch latch) try {catch (InterruptedException ignore) {这个例子某次的运行结果是:
线程thirdThread准备调用await方法......你会发现,多次执行控制台日志后半段打印的线程[线程名]解除阻塞继续运行.....的顺序是各不相同,难道说明了「使用了CountDownLatch后线程阻塞的顺序和被唤醒的顺序不一致吗」 ?可以带着这个疑问阅读下面的章节。
❝
这里可以提示一下注意观察PrintStream#println()方法的源码,内部有synchronized修饰的代码块。
❞
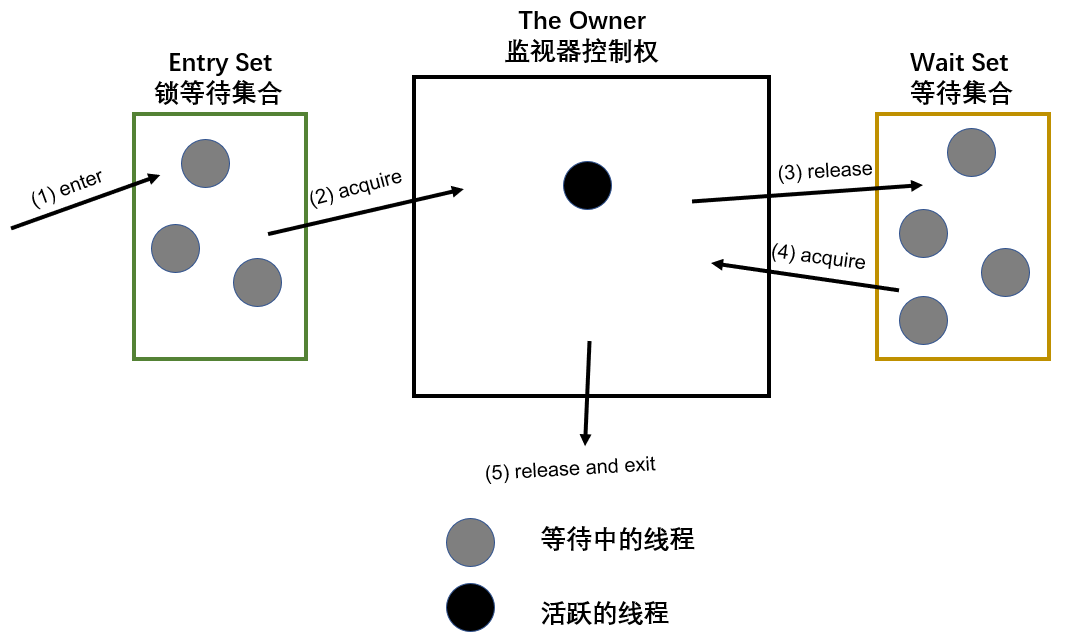
一般原理 之前笔者在分析AQS实现的时候也经常提到:AQS是使用Java语言和数据结构对VM内置监视器(Monitor)的一种实现(这里可能理解为"模拟"更加合理)。CountDownLatch其实也可以使用VM内置监视器的形式进行实现,笔者认为这是其实现的基本原理。见下面的例子:
public class CountDownLatchMonitorMain public static void main (String[] args) throws Exception final Object monitor = new Object();new Thread(() -> {"线程%s准备调用wait方法......" , threadName));"线程%s解除阻塞继续运行......" , threadName));"firstThread" ).start();500L );new Thread(() -> {"线程%s准备调用wait方法......" , threadName));"线程%s解除阻塞继续运行......" , threadName));"secondThread" ).start();500L );"main线程notifyAll......" );private static void block0 (Object monitor) synchronized (monitor) {try {catch (InterruptedException ignore) { // 暂时不处理中断,这个场景也不会存在中断 private static void wakeup0 (Object monitor) synchronized (monitor) {某次运行的结果如下:
线程firstThread准备调用wait方法......上面代码不太规范Object#wait()应该包裹在一个死循环中调用,这个过程的示意图如下:
第
(2)步理解为进入
synchronized代码块。
第
(3)步理解为通过
Object#wait()阻塞成功。
第
(4)步理解为通过
Object#notifyAll()调用后解除阻塞,然后重新获取监视器控制权的线程会继续执行,直到生命周期结束或者进入下一轮控制权获取。
❝
CountDownLatch与内置的Monitor有一点区别的是:不依赖于监视器的控制权,线程的阻塞与解除阻塞式依赖于LockSupport#park()和LockSupport#unpark(),这里笔者资历不足没有研读VM的源码去探究这种方式与Monitor的区别。
❞
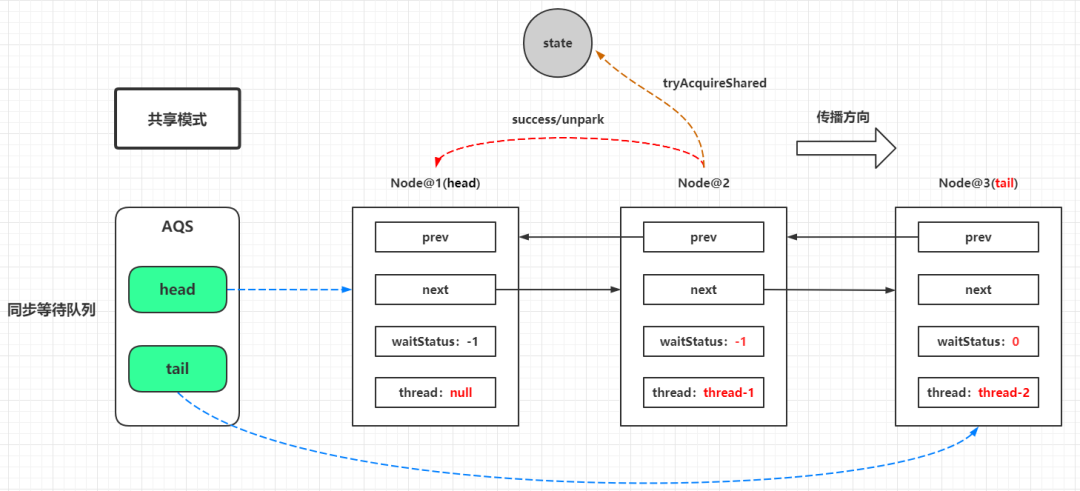
解析CountDownLatch源码 CountDownLatch是「AQS共享模式」 下的典型实现,这里贴出之前AQS共享模式的一张图:
私有静态内部类Sync是一个AQS的实现:
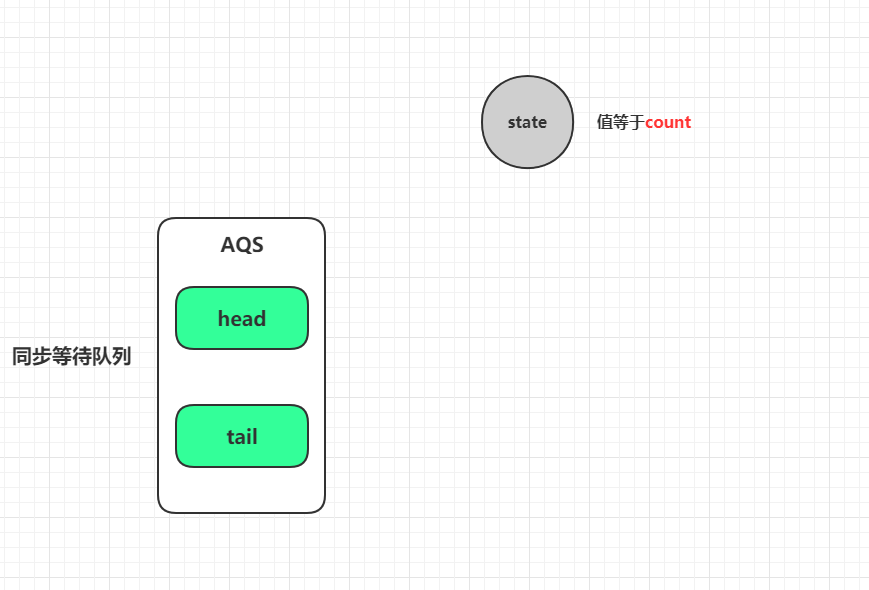
public class CountDownLatch private static final class Sync extends AbstractQueuedSynchronizer private static final long serialVersionUID = 4982264981922014374L ;// 设置AQS的state的值为输入的计数值 int count) {// 获取AQS中的state属性 int getCount () return getState();// 共享模式下获取资源,这里无视共享模式下需要获取的资源数,只判断当前的state值是否为0,为0的时候,意味资源获取成功,闭锁已经释放,所有等待线程需要解除阻塞 // 如果state当前已经为0,那么线程完全不会加入AQS同步队列中等待,表现为直接运行 protected int tryAcquireShared (int acquires) return (getState() == 0 ) ? 1 : -1 ;// 共享模式下释放资源,这里也无视共享模式下需要释放的资源数,每次让状态值通过CAS减少1,当减少到0的时候,返回true protected boolean tryReleaseShared (int releases) // Decrement count; signal when transition to zero for (;;) {int c = getState();// 这种情况下说明了当前state为0,从tryAcquireShared方法来看,线程不会加入AQS同步队列进行阻塞,所以也无须释放 if (c == 0 )return false ;// state的快照值减少1,并且通过CAS设置快照值更新为state,如果state减少为0则返回true,意味着需要唤醒阻塞线程 int nextc = c - 1 ;if (compareAndSetState(c, nextc))return nextc == 0 ;// 输入的计数值不能小于0,意味着AQS的state属性必须大于等于0 public CountDownLatch (int count) if (count < 0 ) throw new IllegalArgumentException("count < 0" );this .sync = new Sync(count);public void await () throws InterruptedException // 共享模式下获取资源,响应中断 1 );public boolean await (long timeout, TimeUnit unit) throws InterruptedException // 共享模式下获取资源,响应中断,带超时期限 return sync.tryAcquireSharedNanos(1 , unit.toNanos(timeout));public void countDown () // 共享模式下释放资源 1 );public long getCount () // 获取当前state的值 return sync.getCount();public String toString () return super .toString() + "[Count = " + sync.getCount() + "]" ;接下来再分步解析每一个方法。先看构造函数:
// 构造函数,其实就是对AQS的state进行赋值 public CountDownLatch (int count) if (count < 0 ) throw new IllegalArgumentException("count < 0" );this .sync = new Sync(count);// 私有静态内部类Sync中 private static final class Sync extends AbstractQueuedSynchronizer int count) {// ...... // AbstractQueuedSynchronizer中 public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java .io .Serializable // ...... // volatile修饰的状态值,变更会强制写回主内存,以便多线程环境下可见 private volatile int state;// 调用的是这个父类方法 protected final void setState (int newState) // ......
由于AQS的头尾节点都是「懒创建」 的,所以只初始化了state的情况下,AQS是"空的"。接着看await()方法:
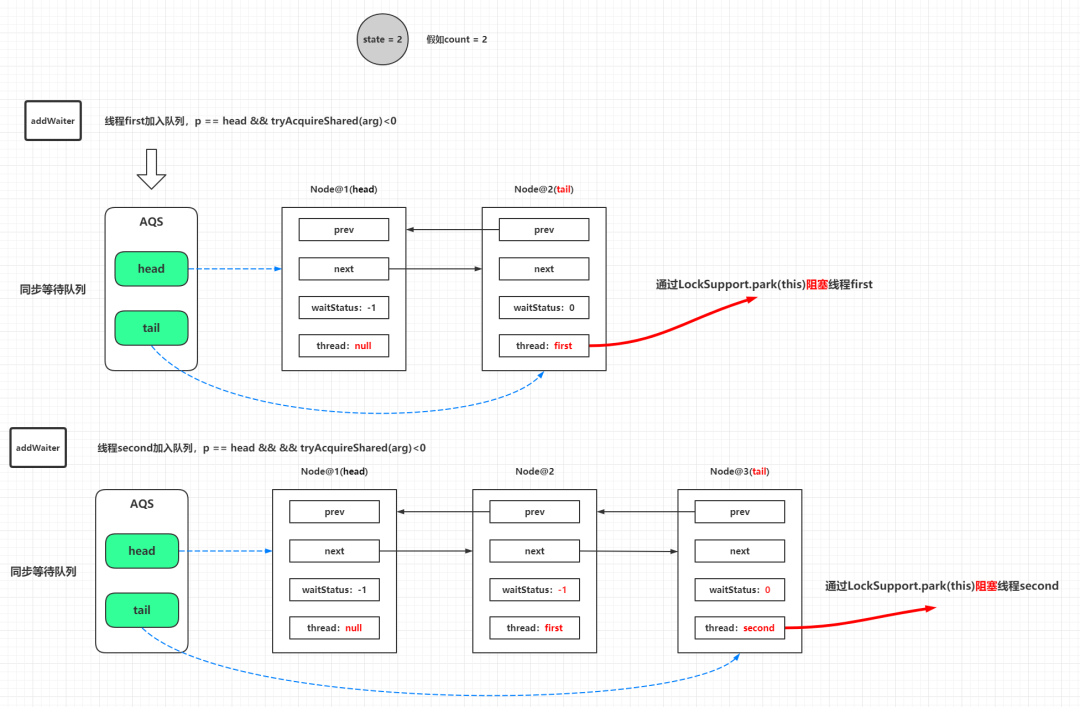
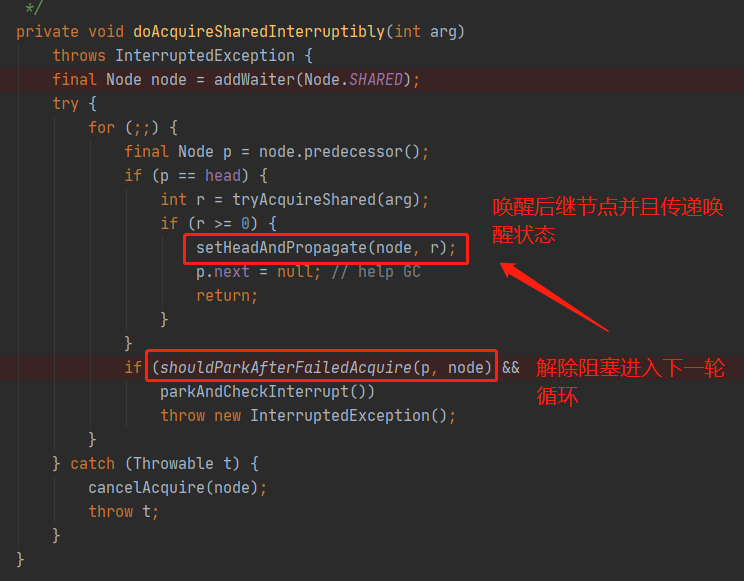
// CountDownLatch中 public void await () throws InterruptedException 1 );// 私有静态内部类Sync中 private static final class Sync extends AbstractQueuedSynchronizer // state等于0的时候返回1,大于0的时候返回-1 protected int tryAcquireShared (int acquires) return (getState() == 0 ) ? 1 : -1 ;// ...... // AbstractQueuedSynchronizer中 public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java .io .Serializable // ...... // 共享模式下获取资源,响应中断 public final void acquireSharedInterruptibly (int arg) throws InterruptedException // 如果线程已经处于中断状态,则清空中断状态位,抛出InterruptedException if (Thread.interrupted())throw new InterruptedException();// 尝试获取资源,此方法由子类CountDownLatch中的Sync实现,小于0的时候,说明state > 0 if (tryAcquireShared(arg) < 0 )// ...... // private void doAcquireSharedInterruptibly (int arg) throws InterruptedException // 基于当前线程新建一个标记为共享的新节点 final Node node = addWaiter(Node.SHARED);try {for (;;) {// 获取新入队节点的前驱节点 final Node p = node.predecessor();// 前驱节点为头节点 if (p == head) {// 并且尝试获取资源成功,也就是每一轮循环都会调用tryAcquireShared尝试获取资源(r >= 0意味获取成功),除非阻塞或者跳出循环 // 由前文可知,CountDownLatch中只有当state = 0的情况下,r才会大于等于0 int r = tryAcquireShared(arg);if (r >= 0 ) {// 设置头结点,并且传播获取资源成功的状态,这个方法的作用是确保唤醒状态传播到所有的后继节点 // 然后任意一个节点晋升为头节点都会唤醒其第一个有效的后继节点,起到一个链式释放和解除阻塞的动作 // 由于节点晋升,原来的位置需要断开,置为NULL便于GC null ; // help GC return ;// shouldParkAfterFailedAcquire -> 判断获取资源失败是否需要阻塞,这里会把前驱节点的等待状态CAS更新为Node.SIGNAL // parkAndCheckInterrupt -> 判断到获取资源失败并且需要阻塞,调用LockSupport.park()阻塞节点中的线程实例,(解除阻塞后)清空中断状态位并且返回该中断状态 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())throw new InterruptedException();catch (Throwable t) {throw t;// ...... 因为是工程化的代码,并且引入了死循环避免竞态条件下的异常,代码看起来比较复杂,其实做了下面几件事:
state不为0的时候,当前调用线程实例会包装为一个
SHARED类型的
Node加入
AQS的同步等待队列的尾部,并且通过
LockSupport.park()阻塞节点中的线程实例。
state为0的时候,直接返回,放行线程(可以尝试使用
new CountDownLatch(0))。
死循环中如果
tryAcquireShared(arg)返回值大于等于0,则任意一个晋升为头节点的节点解除阻塞后都会链式唤醒后继(正常的)节点,唤醒的逻辑在
setHeadAndPropagate()方法中,这个方法命名其实有点奇怪,直译为"设置头节点和传播"。
❝
细心一看,唤不唤同步等待队列中的阻塞节点,只取决于tryAcquireShared(arg)方法的返回值是否大于0,往前一推敲,取决于state或者说count是否为0,所以可知必定有使state变小的方法
❞
接着看countDown()方法:
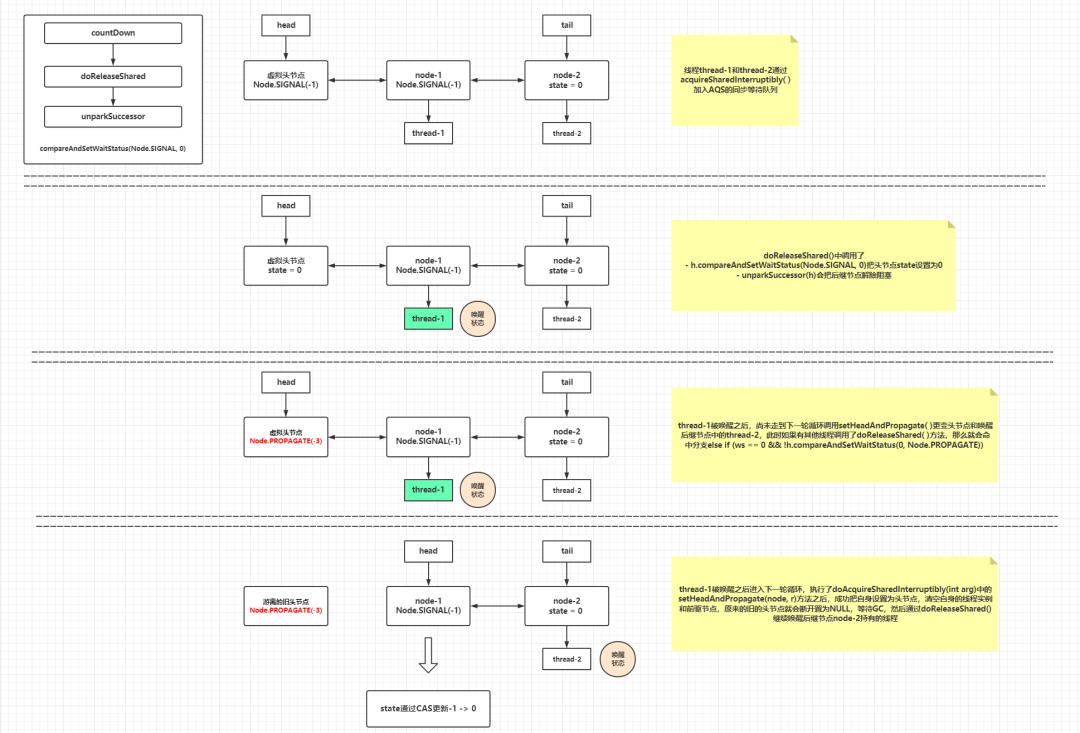
// CountDownLatch中 public void countDown () 1 );// 私有静态内部类Sync中 private static final class Sync extends AbstractQueuedSynchronizer // 共享模式下释放资源,这里也无视共享模式下需要释放的资源数,每次让状态值通过CAS减少1,当减少到0的时候,返回true protected boolean tryReleaseShared (int releases) // 减少计数值state,直到变为0,则进行释放 for (;;) {int c = getState();// 如果已经为0,直接返回false,不能再递减到小于0,返回false也意味着不会进入AQS的doReleaseShared()逻辑 if (c == 0 )return false ;int nextc = c - 1 ;// CAS原子更新state = state - 1 if (compareAndSetState(c, nextc))// 如果此次递减为0则返回true return nextc == 0 ;// ...... // AbstractQueuedSynchronizer中 public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java .io .Serializable // ...... // 共享模式下,释放arg个资源 public final boolean releaseShared (int arg) // 从上面的分析来看,这里只有一种可能返回true并且进入doReleaseShared()方法,就是state由1递减为0的时候 if (tryReleaseShared(arg)) {return true ;return false ;// 共享模式下的释放操作 private void doReleaseShared () // 死循环是避免因为新节点入队产生影响,CAS做状态设置被放在死循环中失败了会在下一轮循环中重试 for (;;) {// 头不等于尾,也就是AQS同步等待队列不为空 // h == NULL,说明AQS同步等待队列刚进行了初始化,并未有持有线程实例的节点 if (h != null && h != tail) {int ws = h.waitStatus;// 头节点为Node.SIGNAL(-1),也就是后继节点需要唤醒,CAS设置头节点状态-1 -> 0,并且唤醒头节点的后继节点(也就是紧挨着头节点后的第一个节点) if (ws == Node.SIGNAL) {// 这个if分支是对于Node.SIGNAL状态的头节点,这种情况下,说明 // 这里使用CAS的原因是setHeadAndPropagate()方法和releaseXX()方法都会调用此doReleaseShared()方法,CAS也是并发控制的一种手段 // 如果CAS失败,很大可能是头节点发生了变更,需要进入下一轮循环更变头节点的引用再进行判断 // 该状态一定是由后继节点为当前节点设置的,具体见shouldParkAfterFailedAcquire()方法 if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0 ))continue ; // loop to recheck cases // 唤醒后继节点,如果有后继节点被唤醒,则后继节点会调用setHeadAndPropagate()方法,更变头节点和转播唤醒状态 // 头节点状态为0,说明头节点的后继节点未设置前驱节点的waitStatus为SIGNAL,代表无需唤醒 // CAS更新它的状态0 -> Node.PROPAGATE(-3),这个标识目的是为了把节点状态设置为跟Node.SIGNAL(-1)一样的负数值, // 便于某个后继节点解除阻塞后,在一轮doAcquireSharedInterruptibly()循环中调用shouldParkAfterFailedAcquire()方法返回false,实现"链式唤醒" else if (ws == 0 && !h.compareAndSetWaitStatus(0 , Node.PROPAGATE)) continue ; // loop on failed CAS // 如果头节点未发生变化,则代表当前没有其他线程获取到资源,晋升为头节点,直接退出循环 // 如果头节点已经发生变化,代表已经有线程(后继节点)获取到资源, if (h == head) // loop if head changed break ;// 解除传入节点的第一个后继节点的阻塞状态,当前处理节点的等待状态会被CAS更新为0 private void unparkSuccessor (Node node) // 当前处理的节点状态小于0则直接CAS更新为0 int ws = node.waitStatus;if (ws < 0 )0 );// 如果节点的第一个后继节点为null或者等待状态大于0(取消),则从等待队列的尾节点向前遍历, // 找到最后一个(这里指的是队列尾部->队列头部搜索路径的最后一个满足的节点,一般是传入的node节点的next节点)不为null,并且等待状态小于等于0的节点 if (s == null || s.waitStatus > 0 ) {null ;for (Node p = tail; p != node && p != null ; p = p.prev)if (p.waitStatus <= 0 )// 解除传入节点的后继节点的阻塞状态,唤醒后继节点所存放的线程 if (s != null )// ......
❝
unparkSuccessor()方法中使用的是从队列尾部向前遍历直到头节点的方式,其实方法中有一段注释,翻译如下:需要解除阻塞的线程保存在(当前处理节点的)后继节点中,而后继节点通常情况下就是(当前处理节点的next引用对应)下一个节点。但是,如果(当前处理节点的next引用对应的节点)处于取消状态或者明显为NULL,那么需要从队列尾部由后往前找到实际的未取消的后继节点。
❞
❝
对于doReleaseShared方法,这个方法笔者看过很多次源码,里面的逻辑是需要一些动态思维和想象,否则很难理解为什么需要需要做死循环、CAS和多次状态判断。if分支和else if分支是针对两个完全不同状态的头节点,需要留一个心眼。
❞
这里一定要注意,unparkSuccessor()只是会「唤醒当前传入节点参数的"正常的"后继节点,并不是唤醒同步队列中的所有阻塞节点」 。头节点的后继节点被唤醒之后,该节点所在的线程会解除阻塞,在doAcquireSharedInterruptibly()方法中被唤醒,解除阻塞后进入下一轮循环,然后调用setHeadAndPropagate()唤醒后继节点,把状态标记为Node.PROPAGATE(-3),这个过程简单理解为"链式反应唤醒"。
复杂的setHeadAndPropagate方法
这里再重点分析一下setHeadAndPropagate()方法的实现,个人认为这是AQS里面的一个比较"烧脑"的方法,复杂不在于它自身的逻辑,而在于它需要结合doAcquireSharedInterruptibly()方法中的死循环和doReleaseShared()方法中的死循环来推演。先看看setHeadAndPropagate()方法的源码 :
private void setHeadAndPropagate (Node node, int propagate) // 这里的临时变量h存放了旧的头节点引用 // Record old head for check below // 这里的输入参数node基本上就是原来旧头节点的后继节点,而propagate的值来源于tryAcquireShared(),由图中可知propagate >= 0 恒成立 /* // 这里是一个很复杂的IF条件,下文一个一个条件看 if (propagate > 0 || h == null || h.waitStatus < 0 ||null || h.waitStatus < 0 ) {if (s == null || s.isShared())// 设置头节点,输入节点的前驱节点和持有线程实例都会置空,因为它持有的线程实例已经从shouldParkAfterFailedAcquire()中解除阻塞 private void setHead (Node node) null ;null ;// 判断当获取资源失败的时候是否应该阻塞当前处理的节点中的线程实例 // node为当前处理的节点或者新入队的节点 // pred则为node的前驱节点 private static boolean shouldParkAfterFailedAcquire (Node pred, Node node) // 前驱节点的状态值 int ws = pred.waitStatus;// 前驱节点处于Node.SIGNAL(-1)状态,说明当前节点可以唤醒,返回true以便调用在下一轮循环进入setHeadAndPropagate()方法 if (ws == Node.SIGNAL)/* return true ;// 状态值大于0,说明当前处理的节点的前驱节点处于取消状态,则需要跳过这些取消状态的前驱节点 if (ws > 0 ) {/* do {while (pred.waitStatus > 0 );else {/* // 剩下的就是其他情况,初始化状态0或者无条件传播状态Node.PROPAGATE(-3),这两种情况把前驱节点状态CAS更新为Node.SIGNAL(-1),表明当前节点可以被唤醒 return false ;setHeadAndPropagate()中有一个极度复杂的IF分支判断,紧记propagate代表的是tryAcquireShared()的返回值:
node实例所持有的线程,
「一定代表当前执行中的线程」 。
if (r >= 0)的外部条件保证
propagate >= 0。
propagate == 0:这种情况下,说明的是共享模式下当前处理节点获取到资源成功之后,没有剩余资源可供获取,理论上无须唤醒
node的后继节点。
propagate > 0:这种情况下,说明的是共享模式下当前处理节点获取到资源成功之后,还有剩余资源可供获取,理论上必须唤醒
node的后继节点。
h == null和
(h = head) == null从整理好的源码分析来看,应该是不会发生的,这里感觉是应用了短路或
||来预防空指针的一种写法。
实际上这个判断分支的主要条件是
propagate > 0 || h.waitStatus < 0,这里
propagate > 0是比较容易理解的,那么
propagate > 0不成立的条件也就是
propagate < 0 && h.waitStatus < 0,说明旧的头节点的
state < 0,但是
unparkSuccessor()肯定会把头节
state点设置为
0,因此,这里
h.waitStatus < 0可以推断只有一个来源:
doReleaseShared()里的
compareAndSetWaitStatus(h, 0, Node.PROPAGATE),把旧头节点的状态设置为
-3,从而使得
h.waitStatus < 0成立,进入后面的判断后继节点和唤醒操作,这里就是所谓的"传播"。细心的伙伴会发现,
Node.PROPAGATE定义为
-3目的仅仅是为了标识一个负数值用于这些
IF逻辑块的命中,并且和特殊的唤醒状态
Node.SIGNAL(-1)做严格的区分。
s == null || s.isShared()就是判断当前新头节点的后继节点是否为空或者是否处于共享模式,
s == null说明
node不存在后继节点,也就是头节点和尾节点重合,当前的
node实例也是同步等待队列中的最后一个节点,需要进行唤醒操作。
补充一下:共享模式下(其实独占模式下也是这样)在不满足唤醒条件的前提下,一个全新的节点加入到AQS的同步等待队列中,在doAcquireSharedInterruptibly()需要经历两轮循环才会成功阻塞:
第一轮循环:
shouldParkAfterFailedAcquire()把新入队的节点的前驱节点
pred的
state通过
CAS更新为
0 -> Node.SIGNAL(-1),方法返回
false进入下一轮循环。
第二轮循环:还是进入到
shouldParkAfterFailedAcquire()方法,识别到新入队的节点的前驱节点
pred的
state == Node.SIGNAL(-1),返回
true,调用
parkAndCheckInterrupt()最终委托到
LockSupport.park()进行线程的阻塞,所以只要有新节点加入到同步等待队列,其前驱节点的状态必定先被更变为
Node.SIGNAL(-1)。
如果至此,还有不理解"PROPAGATE"这个词的含义的话,可以看看下图的状态推演,笔者把节点状态变更的细节全部标明:
最后,带超时阻塞的doAcquireSharedNanos()方法实现思路其实差不多,只是在获取资源的循环体中会判断阻塞是否超越了输入的期限,超时的节点应用cancelAcquire(node)更变状态为取消,然后阻塞线程的方法使用了LockSupport.parkNanos()。
唤醒顺序的问题 基于上面的源码分析,总结一下CountDownLatch对于阻塞线程唤醒的顺序,如果达到唤醒条件后:
虚拟头节点的首个非取消的后继节点会先被唤醒,唤醒的位置是:
releaseShared() -> doReleaseShared() -> unparkSuccessor()。
被唤醒的首个后继节点会在
doAcquireSharedInterruptibly()的死循环
for(;;)中的
setHeadAndPropagate()更变自己为头节点,并且唤醒自身的首个非取消的后继节,这一步会类似于递归执行,直到所有有效节点的阻塞线程都解除阻塞。
AQS的数据结构是CLH锁队列的变体,毕竟是队列数据结构,所以阻塞节点的出队(解除阻塞)也遵循于「FIFO」 的特性。节点持有线程解除阻塞后的执行顺序,有可能会和预期不一样,这是因为很多时候线程解除阻塞之后,会参与其他类型的锁竞争,例如System.out.println()方法,本质是一个同步方法,后解除阻塞的线程有可能先获取到锁并且先执行。这里可以取巧用其他手段监测一下这些阻塞线程的解除阻塞的顺序,例如在LockSupport.unpark()方法做一个埋点,可以应用Instrumentation和字节码增强工具。先引入Javassist:
<dependency > <groupId > org.javassist</groupId > <artifactId > javassist</artifactId > <version > 3.27.0-GA</version > </dependency > 编写一个Agent:
public class AqsAgent private static final byte [] NO_TRANSFORM = null ;public static void premain (final String agentArgs, @NonNull final Instrumentation inst) new LockSupportClassFileTransformer(), true );private static class LockSupportClassFileTransformer implements ClassFileTransformer @Override public byte [] transform(ClassLoader loader,byte [] classfileBuffer) throws IllegalClassFormatException {if (className.contains("concurrent" )) {"正在处理:" + className);if (className.equals("java.util.concurrent.locks.AbstractQueuedSynchronizer" )) {return processTransform(loader, classfileBuffer);return NO_TRANSFORM;private static byte [] processTransform(ClassLoader loader, byte [] classfileBuffer) {try {final ClassPool classPool = new ClassPool(true );if (loader == null ) {new LoaderClassPath(ClassLoader.getSystemClassLoader()));else {new LoaderClassPath(loader));final CtClass clazz = classPool.makeClass(new ByteArrayInputStream(classfileBuffer), false );final CtClass paramClass = clazz.getClassPool().get("java.util.concurrent.locks.AbstractQueuedSynchronizer$Node" );final CtMethod unparkMethod = clazz.getDeclaredMethod("unparkSuccessor" , new CtClass[]{paramClass});"{java.lang.Object x = $1;\n" +" java.lang.reflect.Field nextField = Class.forName(\"java.util.concurrent.locks.AbstractQueuedSynchronizer$Node\").getDeclaredField(\"next\");\n" +" java.lang.reflect.Field threadField = Class.forName(\"java.util.concurrent.locks.AbstractQueuedSynchronizer$Node\").getDeclaredField(\"thread\");\n" +" nextField.setAccessible(true);\n" +" threadField.setAccessible(true);\n" +" java.lang.Object next = nextField.get(x);\n" +" if (null != next){" +"java.lang.Object thread = threadField.get(next);\n" +"System.out.println(\"当前解除阻塞的线程名称为:\"+ thread);\n" +"}\n" +"}" );return clazz.toBytecode();catch (Exception e) {throw new IllegalStateException(e);private static String toClassName (@NonNull final String classFileName) return classFileName.replace('/' , '.' );文章开头提到的例子里面,在VM参数添加-javaagent:I:\J-Projects\lock-support-agent\target\lock-support-agent.jar引入这个做好的Agent,再运行一次,结果如下:
线程thirdThread准备调用await方法......可见唤醒和阻塞的顺序是完全一致的,印证了前面的源码分析过程。
CountDownLatch实战 除了一些个人项目或者Demo,笔者在生产环境中只在少量场景应用过CountDownLatch,其中一个场景是数据迁移的「生产者-消费者线程模型控制模块」 。这个方案在前公司迁移一张存量一亿多的图片信息记录表,拆分到单库128张新建的图片信息表中,过程一共用了几个小时(主要瓶颈在带宽和写操作,因为当时数据库机器的磁盘为机械硬盘,带宽有限并且需要保证业务稳定的情况下只能尽可能减少写线程的数量)。伪代码如下:
public class PhotoMigration // 毒丸对象,参考自《Java并发编程实战》的7.2.3一节 static final List<Photo> POISON = Collections.emptyList();static final int WORKER_COUNT = 10 ;static final BlockingQueue<List<Photo>> QUEUE = new ArrayBlockingQueue<>(WORKER_COUNT * 10 );public void process () throws Exception new CountDownLatch(WORKER_COUNT);new ThreadPoolExecutor(WORKER_COUNT, WORKER_COUNT, 0 , TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadFactory() {private final AtomicInteger counter = new AtomicInteger();@Override public Thread newThread (@NotNull Runnable r) new Thread(r);true );"MigrationWorker-" + counter.getAndIncrement());return thread;long id = 0 ;for (; ; ) {500 );if (photos.isEmpty()) {for (int i = 0 ; i < WORKER_COUNT; i++){break ;else {// 解除主线程阻塞 // 关闭线程池 @RequiredArgsConstructor private static class Task implements Runnable private final CountDownLatch latch;@Override public void run () for (; ; ) {try {if (POISON == photos) {break ;// 执行迁移逻辑和入库 catch (InterruptedException e) {@Data private static class Photo private Long id;上面的伪代码基本可以使用在任意的数据迁移场景,可以动态调整查询线程和写线程的数量(这里只是简单描述了一个查询线程多个写线程的伪代码,实践上应用了多线程查和多线程写,笔者之前为了简单起见,提前对需要迁移的数据进行了ID分段,查询线程已经提前规划好需要查询的ID段),如果做得更加完善,甚至可以控制每批次处理的数量、异常记录和恢复等等,「方案的灵感来源于Java并发编程圣经《Java并发编程实战》中的第五章」 。里面的组件可以做改良,升级为多进程版本,例如保证单进程做查询的前提下,把队列替换为RabbitMQ中的"队列"概念,把Worker调整为RabbitMQ的消费者即可。原则上,存在"等待某些操作完成之后执行其他操作"的场景,可以考虑使用CountDownLatch。
小结 CountDownLatch算是JUC包中实现思路相对简单的一个组件,不过在使用的时候需要注意几个事项:
CountDownLatch虽然保证唤醒的顺序和阻塞的顺序一致,但是由于线程切换以及锁竞争等原因,唤醒后的执行顺序有可能和预期不一样,如果需要严格控制顺序不防考虑使用队列数据结构。
CountDownLatch也是
Object的子类,容易误用
wait()方法,紧记应该是
await()方法。
CountDownLatch的倒数方法
countDown()避免并发调用。
CountDownLatch只有在
count(state)倒数到0的时候,才会唤醒所有的阻塞线程。
至此,CountDownLatch的基本使用和源码分析基本结束,AQS的状态变更和状态判断,大量的死循环和复杂的条件判断看起来真是让人觉得烧脑,但毫无疑问这是一个比较优秀的并发工具,推荐使用于下面的类似场景:
确保某个计算逻辑在其需要的其他服务都已经启动后才继续执行。
确保某个服务在其依赖的所有服务都已经启动后才启动。
这里给出文中编写好的Agent的仓库:
Github:
https://github.com/zjcscut/aqs-agent
(本文完 c-5-d e-a-20200831 耗费了大量时间作图、DEGUG和编写Agent)