点击上方“
BAT的乌托邦
”,选择“
设为星标
”
✍前言 你好,我是YourBatman。
上篇文章 体验了一把ObjectMapper在「数据绑定」 方面的应用,用起来还是蛮方便的有木有,为啥不少人说它难用呢,着实费解。我群里问了问,主要原因是它不是静态方法调用,并且方法名取得不那么见名之意......
虽然ObjectMapper在数据绑定上既可以处理简单类型(如Integer、List、Map等),也能处理完全类型(如POJO),看似无所不能。但是,若有如下场景它依旧「不太好实现」 :
硕大的JSON串中我只想要
「某一个」 (某几个)属性的值而已
临时使用,我并不想创建一个POJO与之对应,只想直接使用
「值」 即可(类型转换什么的我自己来就好)
为了解决这些问题,Jackson提供了强大的「树模型」 API供以使用,这也就是本文的主要的内容。
❝
小贴士:树模型虽然是jackson-core模块里定义的,但是是由jackson-databind高级模块提供的实现
❞
版本约定
Spring Framework版本:
5.2.6.RELEASE
Spring Boot版本:
2.3.0.RELEASE
✍正文 树模型可能比数据绑定「更方便,更灵活」 。特别是在结构高度「动态」 或者不能很好地映射到Java类的情况下,它就显得更有价值了。
树模型 树模型是JSON数据内存树的表示形式,这是最灵活的方法,它就类似于XML的DOM解析器。Jackson提供了树模型API来「生成和解析」 JSON串,主要用到如下三个核心类:
JsonNodeFactory:顾名思义,用来构造各种JsonNode节点的工厂。例如对象节点ObjectNode、数组节点ArrayNode等等
JsonNode:表示json节点。可以往里面塞值,从而最终构造出一颗json树
ObjectMapper:实现JsonNode和JSON字符串的互转
这里有个萌新的概念:JsonNode。它贯穿于整个树模型中,所以有必要先来认识它。
JsonNode JSON节点,可类比XML的DOM树节点结构来辅助理解。JsonNode是所有JSON节点的基类,它是一个抽象类,它有一个较大的特点:绝大多数的get方法均放在了此抽象类里(即使它没有实现),目的是:「在不进行类型强制转换的情况下遍历结构」 。但是,大多数的「修改方法」 都必须通过特定的子类类型去调用,这其实是合理的。因为在构建/修改某个Node节点时,类型类型信息一般是明确的,而在读取Node节点时大多数时候并不太关心节点类型。
多个JsonNode节点构成Jackson实现的JSON树模型的基础,它是流式API中com.fasterxml.jackson.core.TreeNode接口的实现,同时它还实现了Iterable迭代器接口。
public abstract class JsonNode extends JsonSerializable .Base implements TreeNode , Iterable <JsonNode > JsonNode的继承图谱如下(部分):ArrayNode、数字节点NumericNode等等。
一般情况下,我们并不需要通过new关键字去构建一个JsonNode实例,而是借助JsonNodeFactory工厂来做。
JsonNodeFactory 构建JsonNode工厂类。话不多说,用几个例子跑一跑。
此类节点均为ValueNode的子类,特点是:一个节点表示一个值。
@Test public void test1 () "------ValueNode值节点示例------" );// 数字节点 1 );":" + node.intValue());// null节点 ":" + node.asText());// missing节点 "_" + node.asText());// POJONode节点 new Person("YourBatman" , 18 ));":" + node.asText());"---" + node.isValueNode() + "---" );运行程序,输出:
------ValueNode值节点示例------true :1 true :null true :Person(name=YourBatman, age=18 )true ---此类节点均为ContainerNode的子类,特点是:本节点代表一个容器,里面可以装任何其它节点。
Java中容器有两种:Map和Collection。对应的Jackson也提供了两种容器节点用于表述此类数据结构:
ObjectNode:类比Map,采用K-V结构存储。比如一个JSON结构,
「根节点」 就是一个ObjectNode
ArrayNode:类比Collection、数组。里面可以放置任何节点
下面用示例感受一下它们的使用:
@Test public void test2 () "------构建一个JSON结构数据------" );// 添加普通值节点 "zhName" , "A哥" ); // 效果完全同:rootNode.set("zhName", factory.textNode("A哥")) "enName" , "YourBatman" );"age" , 18 );// 添加数组容器节点 "java" )"javascript" )"python" );"languages" , arrayNode);// 添加对象节点 "name" , "大黄" )"age" , 3 );"dog" , dogNode);"dog" ).get("name" ));运行程序,输出:
------构建一个JSON结构数据------"zhName" :"A哥" ,"enName" :"YourBatman" ,"age" :18 ,"languages" :["java" ,"javascript" ,"python" ],"dog" :{"name" :"大黄" ,"age" :3 }}"大黄" ObjectMapper中的树模型 树模型其实是底层「流式API」 所提出和支持的,典型API便是com.fasterxml.jackson.core.TreeNode。但通过前面文章的示例讲解可以知道:底层流式API仅定义了接口而并未提供任何实现,甚至半成品都算不上。所以说要使用Jackson的树模型还得看ObjectMapper,它提供了TreeNode等API的完整实现。
不乏很多小伙伴对ObjectMapper的树模型是一知半解的,甚至从来都没有用过,其实它是「非常灵活」 和强大的。有了上面的基础示例做支撑,再来了解它的实现就得心应手多了。
ObjectMapper中提供了树模型(tree model) API 来生成和解析 json 字符串。如果你不想为你的 json 结构单独建类与之对应的话,则可以选择该 API,如下图所示:「遍历」 完整的树。同样的,我们可从读(反序列化)、写(序列化)两个方面来展开。
将Object写为JsonNode,ObjectMapper给我们提供了三个实用API俩操作它:
该方法属相对较为常用:将任意对象(包括null)写为一个JsonNode树模型。功能上类似于先将Object序列化为JSON串,再读为JsonNode,但很明显这样一步到位更加高效。
❝
小贴士:高效不代表性能高,因为其内部实现好还是调用了readTree()方法的
❞
@Test public void test1 () new ObjectMapper();new Person();"YourBatman" );18 );new Person.Dog("旺财" , 3 ));// 遍历打印所有属性 while (it.hasNext()) {if (nextNode.isContainerNode()) {if (nextNode.isObject()) {"狗的属性:::" );"name" ));"age" ));else {// 直接获取 "---------------------------------------" );"dog" ).get("name" ));"dog" ).get("age" ));运行程序,控制台输出:
Person(name=YourBatman, age=18 , dog=Person.Dog(name=旺财, age=3 ))18 "旺财" 3 "旺财" 3 对于JsonNode在这里补充一个要点:读取其属性,你既可以用迭代器遍历,也可以根据key(属性)直接获取,是不是和Map的使用几乎一毛一样?
顾名思义:将一个JsonNode使用JsonGenerator写到输出流里,此方法直接使用到了JsonGenerator这个API,灵活度杠杠的,但相对偏底层,本处仍旧给个示例玩玩吧(底层API更多详解,请参见本系列前面几篇文章):
@Test public void test2 () throws IOException new ObjectMapper();new JsonFactory();try (JsonGenerator jsonGenerator = factory.createGenerator(System.err, JsonEncoding.UTF8)) {// 1、得到一个jsonNode(为了方便我直接用上面API生成了哈) new Person();"YourBatman" );18 );// 使用JsonGenerator写到输出流 运行程序,控制台输出:
{"name" :"YourBatman" ,"age" :18 ,"dog" :null }JsonNode是TreeNode的实现类,上面方法已经给出了使用示例,所以本方法不在赘述你应该不会有意见了吧。
将一个资源(如字符串)读取为一个JsonNode树模型。_readTreeAndClose()这个protected方法,可谓“万剑归宗”。
下面以最为常见的:读取JSON字符串为例,其它的举一反三即可。
@Test public void test3 () throws IOException new ObjectMapper();"{\"name\":\"YourBatman\",\"age\":18,\"dog\":null}" ;// 直接映射为一个实体对象 // mapper.readValue(jsonStr, Person.class); // 读取为一个树模型 // ... 略 至于底层_readTreeAndClose(JsonParser)方法的具体实现,就有得捞了。不过鉴于它过于枯燥和稍有些烧脑,后面撰有专文详解,有兴趣可持续关注。
场景演练 理论和示例讲完了,「光说不练假把式」 ,下面A哥根据经验,举两个树模型的实际使用示例供你参考。
这种场景其实还蛮常见的,比如有个很经典的场景便是在MQ消费中:生产者一般会恨不得把它能吐出来的属性尽可能都扔出来,但对于不同的消费者而言它们的所需往往是不一样的:
需要较多的属性值,这时候用
「完全数据绑定」 转换成POJO来操作更为方便和合理
需要1个(较少)的属性值,这时候“杀鸡岂能用牛刀”呢,这种case使用树模型来做就显得更为优雅和高效了
譬如,生产者生产的消息JSON串如下(模拟数据,总之你就当做它属性很多、嵌套很深就对了):
{"name" :"YourBatman" ,"age" :18 ,"dog" :{"name" :"旺财" ,"color" :"WHITE" },"hobbies" :["篮球" ,"football" ]}这时候,我仅关心狗的颜色,肿么办呢?相信你已经想到了:树模型
@Test public void test4 () throws IOException new ObjectMapper();"{\"name\":\"YourBatman\",\"age\":18,\"dog\":{\"name\":\"旺财\",\"color\":\"WHITE\"},\"hobbies\":[\"篮球\",\"football\"]}" ;"dog" ).get("color" ).asText());运行程序,控制台输出:WHITE,目标达成。值得注意的是:如果node.get("dog")没有这个节点(或者值为null),是会抛出NPE异常的,因此请你自己保证代码的健壮性。
当你不想创建一个Java Bean与JSON属性相对应时,树模型的「所见即所得」 特性就很好解决了这个问题。
当数据结构高度动态化(随时可能新增、删除节点)时,使用树模型去处理是一个较好的方案(稳定之后再转为Java Bean即可)。这主要是利用了树模型它具有动态可扩展的特性,满足我们日益变化的结构:
@Test public void test5 () throws JsonProcessingException "{\"name\":\"YourBatman\",\"age\":18}" ;new ObjectMapper().readTree(jsonStr);"-------------向结构里动态添加节点------------" );// 动态添加一个myDiy节点,并且该节点还是ObjectNode节点 "myDiy" ).put("contry" , "China" );运行程序,控制台输出:
-------------向结构里动态添加节点------------"name" :"YourBatman" ,"age" :18 ,"myDiy" :{"contry" :"China" }}说白了,也没啥特殊的。拿到一个JsonNode后你可以任意的造它,就像Map<Object,Object>一样~
✍总结 树模型(tree model) API比Jackson 流式(Streaming) API 简单了很多,不管是生成 json字符串还是解析json字符串。但是相对于「自动化」 的数据绑定而言还是比较复杂的。
树模型(tree model) API在只需要取出一个大json串中的几个值时比较方便。如果json中每个(大部分)值都需要获得,那么这种方式便显得比较繁琐了。因此在实际应用中具体问题具体分析,「但是,Jackson的树模型你必须得掌握」 。

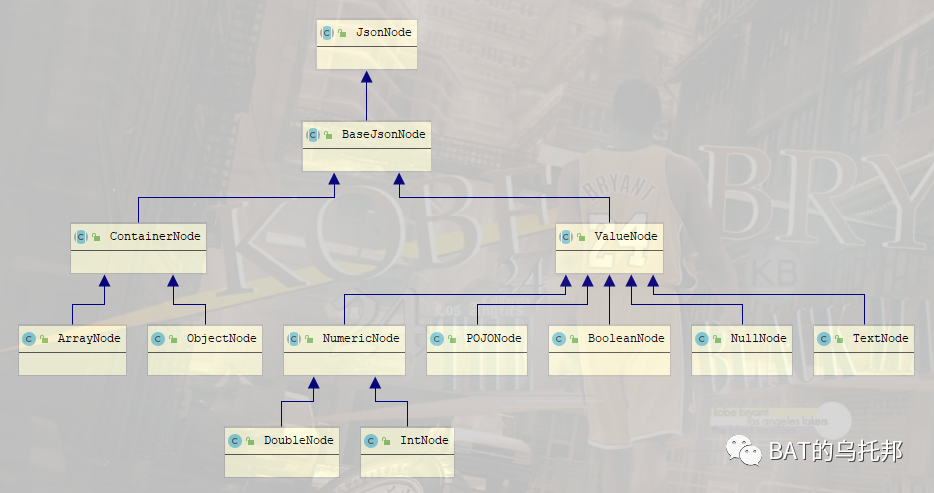 一目了然了吧,基本上每个数据类型都会有一个JsonNode的实现类型对应。譬如数组节点
一目了然了吧,基本上每个数据类型都会有一个JsonNode的实现类型对应。譬如数组节点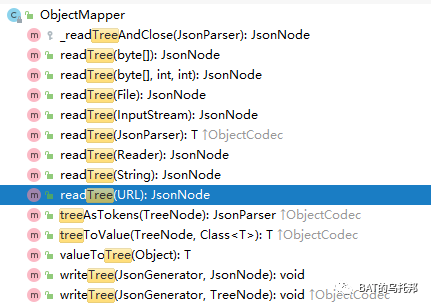 ObjectMapper在读取JSON后提供指向树的根节点的指针, 根节点可用于「遍历」完整的树。同样的,我们可从读(反序列化)、写(序列化)两个方面来展开。
ObjectMapper在读取JSON后提供指向树的根节点的指针, 根节点可用于「遍历」完整的树。同样的,我们可从读(反序列化)、写(序列化)两个方面来展开。
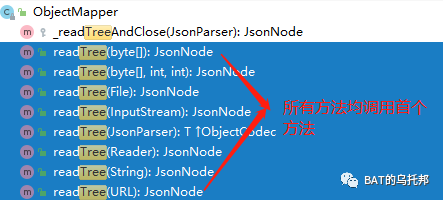 这是典型的方法重载设计,API更加友好,所有方法底层均为
这是典型的方法重载设计,API更加友好,所有方法底层均为


