![]()
加群交流在后台回复“加群”,添加小编微信,小编拉你进去
多个路由协议?再正常不过了
作为一名网络行业从业者,我多么希望面对的网络架构是完美的。
就好比玩游戏可以开挂,要是生活、工作也能开挂多好。
但日常工作中,你会发现企业网络也好,其他类型的网络也好。
总是存在各种瑕疵,各种不和谐。
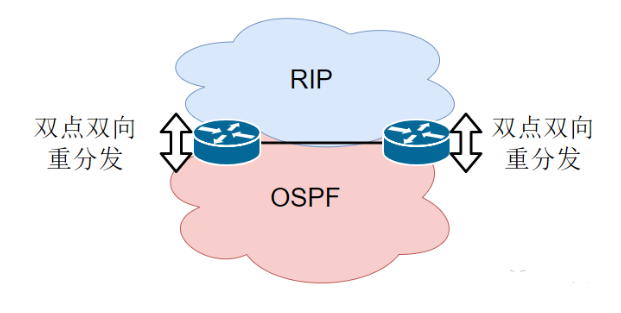
其中一个不和谐,就是一张网同时由存在多个路由协议互联互通。
再奇葩一点,多个路由协议之间通过多台路由器重分发路由,来提供两两之间的可达性。
此话怎么讲?
让我们来看一个拓扑:
![]()
上图中,存在两个路由域,OSPF域以及RIP域, 两个域通过两台路由器互联在-起。
同时,为了交换两个域内的路由,让OSPF内的设备能够与RIP设备互联互通,我们需
要在两台路由器上作双点双向重分发。
什么时候存在多个路由域?
![]()
总之,不管什么原因,当两个不同的路由协议同时存在于网络中,并有两台路由器做双
向重分发时。
若不采取人为干涉,网络故障就发生了。
网络故障,什么网络故障,可否说清楚点?
这里故意卖个关子,先看一个案例,你就明白了。
一个诡异的路由问题:
上面以OSPF和RIP组成的拓扑为例讨论此问题。
既然这样,就顺水推舟,采用此拓扑搭建一个实验环境。
让我们一起来看看,当OSPF和RIP两个点互相重分发以后,到底会发什么事情?
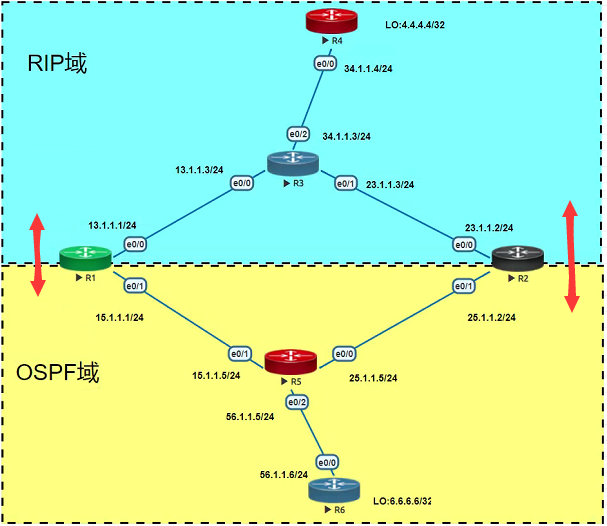
拓扑如下:
![]()
拓扑简介
上述拓扑中,存在两个路由协议,分别是OSPF (下方) ,RIP (上方)。
OSPF内部有R5,R6四台路由器。
RIP内部有R3,R4四台路由器。
R1和R2则是同时处于RIP和OSPF域中。
路由器之间的IP地址为路由器的数字名称组合而成。例如R1和R3之间的链路则是: 13.
1.1.0/24。
R1是13.1.1.1/24,R3则是13.1.1.3/24, 以此类推,非常容易理解。
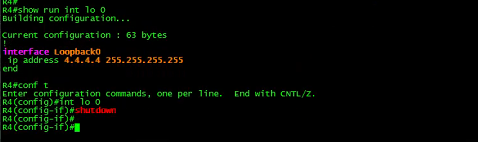
为了验证连通性, R4和R6_ 上开启了两个还回接口lo0。
R4的Io0 IP为4.4.4.4/32。R6的lo0 IP为6.6 6.6/32。
重分发说明:
此实验中,R1和R2同时双向重分发OSPF和RIP。即向OSPF里重分发了RIP的路由,
向RIP内重分发了OSPF的路由。
实验目的:
很简单,只需要让R4和R6的I0IP地址互 联互通即可。
实验配置:各路由器配置如下:
#####R4:
interface Loopback0
ip address 4.4.4.4 255.255.255.255
interface Ethernet0/0
ip address 34.1.1.4 255.255.255.0
router rip
version 2
network 4.0.0.0
network 34.0.0.0
no auto-summary
#####R3:
interface Ethernet0/0
ip address 13.1.1.3 255.255.255.0
interface Ethernet0/1
ip address 23.1.1.3 255.255.255.0
interface Ethernet0/2
ip address 34.1.1.3 255.255.255.0
router rip
version 2
network 13.0.0.0
network 23.0.0.0
network 34.0.0.0
no auto-summary
####R1:
interface Ethernet0/0
ip address 13.1.1.1 255.255.255.0
interface Ethernet0/1
ip address 15.1.1.1 255.255.255.0
router ospf 1
#重点来了,OSPF重分发RIP
redistribute rip subnets
network 15.1.1.0 0.0.0.255 area 0
router rip
version 2
#RIP重分发OSPF
redistribute ospf 1 metric 1
network 13.0.0.0
no auto-summary
#####R2
interface Ethernet0/0
ip address 23.1.1.2 255.255.255.0
interface Ethernet0/1
ip address 25.1.1.2 255.255.255.0
router ospf 1
redistribute rip subnets
#OSPF重分发RIP
network 25.1.1.0 0.0.0.255 area 0
router rip
version 2
redistribute ospf 1 metric 1
#RIP重分发OSPF
network 23.0.0.0
no auto-summary
####R5
interface Ethernet0/0
ip address 25.1.1.5 255.255.255.0
interface Ethernet0/1
ip address 15.1.1.5 255.255.255.0
interface Ethernet0/2
ip address 56.1.1.5 255.255.255.0
router ospf 1
network 0.0.0.0 255.255.255.255 area 0
####R6
interface Loopback0
ip address 6.6.6.6 255.255.255.255
interface Ethernet0/0
ip address 56.1.1.6 255.255.255.0
router ospf 1
network 0.0.0.0 255.255.255.255 area 0
上述配置浅显易懂,也没有什么复杂的网络技术,简单说来就是在R1和R2上开启了两
个路由协议,并做了互相重分发。
但是,往往越简单的东西,破坏力越大。
一段时间以后,各个路由协议收敛完成。
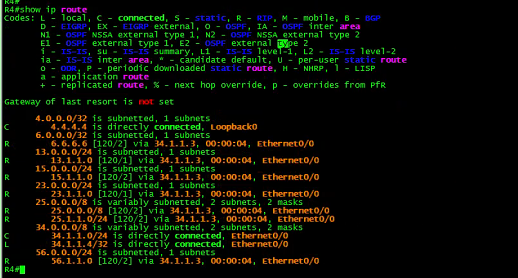
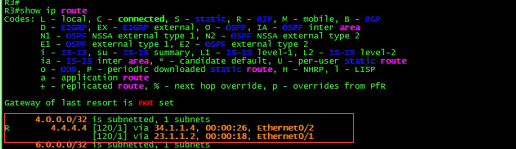
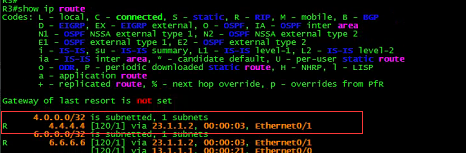
接下来看看各个路由器的路由表:
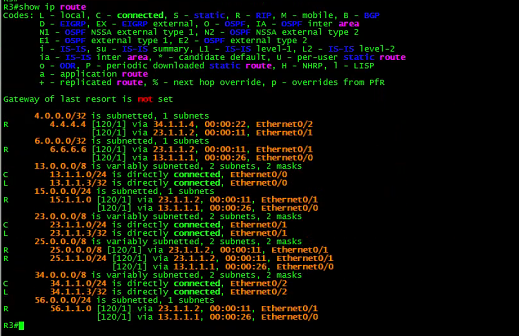
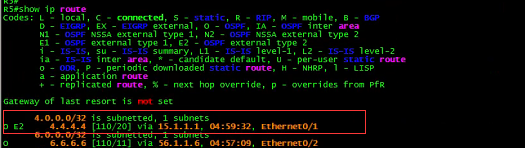
R4:
![]()
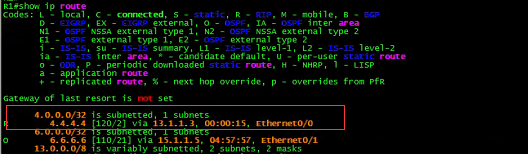
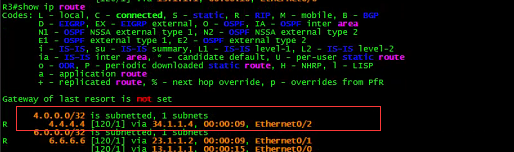
R3:
![]()
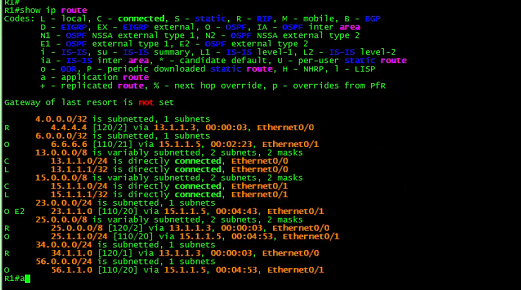
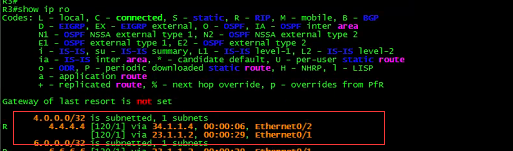
R1:
![]()
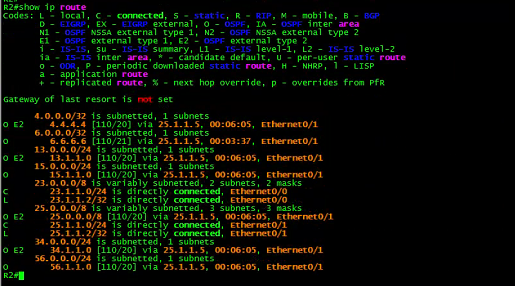
R2:
![]()
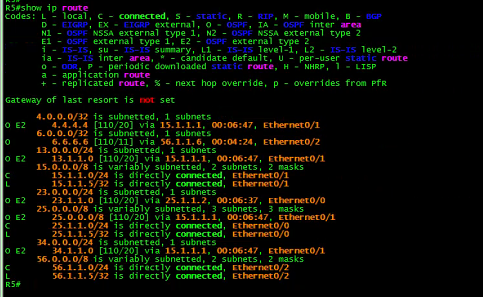
R5:
![]()
R6:
![]()
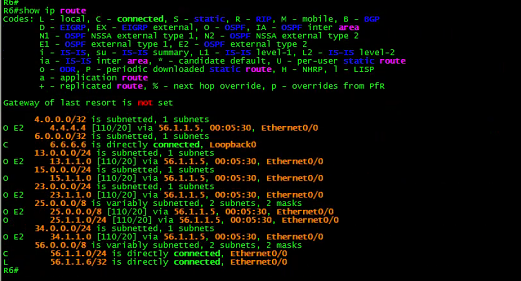
上面的路由表,不知道你是否看出来端倪。(悄悄提示:注意4. 4.4.4/32的路由。)
没看出来也无所谓,请继续往下走。
实验结果验证:
接下来进行验证环节。
很简单,验证方法为R6是否能够ping得通R4的还回地址4.4.4.4。
###R6测试:
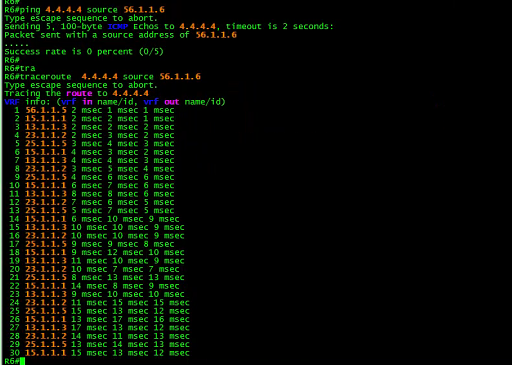
以R6的接口56.1.1.6/32为源来ping 4.4.4.4
![]()
非常完美
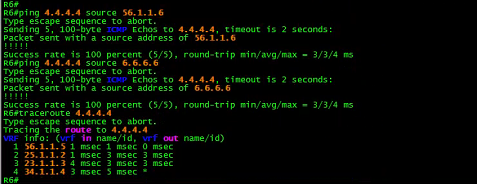
以R6的环回6.6.6。6为源来ping 4.4.4.4
![]()
居然不通????
神奇的事情发生了,R6以56.1.1.6为源ping 4.4.4.4没有问题,但是以6.6.6.6为源ping 4.4.4.4则失败。
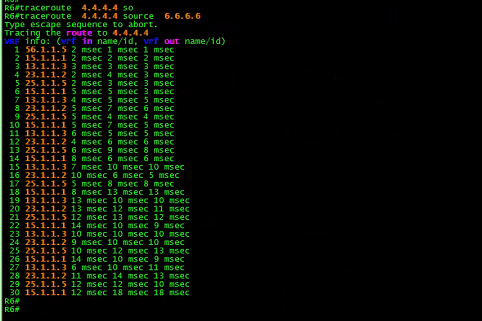
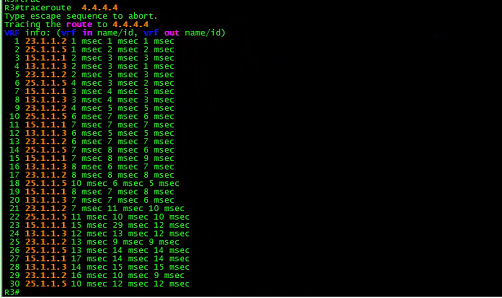
为了验证数据包的路径,这一次试试traceroute,如下所示:
采用R6的接口56.1.1.6为源
![]()
上述结果没有问题,数据包经过4跳后到达R4。
让我们继续采用R6的环回6.6.6.6为源做traceroute
![]()
##哎呀,环路了。
##怪不得,ping不通呢
从上面的traceroute发现一个很奇怪的问题,当以R6的接口IP地址6.6.6.6为源时, 就出现环路。
“全网路由都正常,4.4.4. 4和6.6 66都在路由表里面,逻辑上没问题。”
“莫非此网络还出神灵了不成,估计是Cisco bug,让我们重启路由器试试,不行的话再报case报修"。
这是很多朋友遇到此问题第一时间的反应。
但是,小编喜欢
刨根问底,分析细节。
环路问题分析
首先,从环路的信息开始分析。
上述traceroute环路发生在R1,R2, R3, R5之间,
R3做了 一件很诡异的事情。
首先R3收到到达4.4.4 4的数据包,由于R3是唯一一台去往R4的路由器, 逻辑上来讲,
不犹豫R3会把此数据包直接转发给R4。
但是R3不仅没有,反而发送给了R2。
那是什么神奇的力量让R3做如此选择呢?让我们再看看R3的路由表:
![]()
有意思,R3去往R4的4.4.4.4居然有两个下一跳。
第一个是去往真正的目的地,即R4。
第二个则是去往R2。
凭什么让R2认为它自己可以到达R4的4.4.4.4?
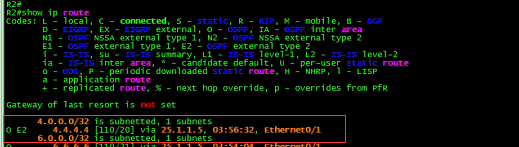
这次查看R2的路由表:
![]()
R2从R5学习到的4.4.4.4。
这件事情越来越有意思了。
以此类推,往下追查: .
R5的路由:
![]()
R1的路由:
![]()
最后发现,R5的路由来源于R1,而R1的4.4. 44/32则是来源于R3的RIP。
所以R1这里算是回到正轨了。
那为什么R5会有R1传来的4.4.4. 4/32路由,还是OSPF。
答案是:重分发。
看到这里,相信你对于此问题的理解心中已有八九分。
![]()
因为上述原因,R3又收到了一份R2发过来的4.4.4.4/32路由。凑巧的是,R3从R4那里
学到的4.4.4.4/32度量值metric为1,而R1在做OSPF>RIP重分发时,也指定了metric
度量值为1。
为此,R3上的4.4.4.4/32同时存在两个下—跳:
![]()
现在,我们总算了解清楚为什么R3上有两个下一跳的原因。
接着往下走。
详解R6诡异的ping
上述分析只是解释了R3的下一跳问题,但是开篇提到的最根本问题仍然没有回答。
为什么R6以56.1.1.6为源可以ping 4.4.4.4,但是以6.6.6.6接口地址为源反而不行?
在分析此问题之前,先说说一个背景知识,网络设备如何做负载均衡。
网络设备负载均衡浅谈
![]()
简单聊完负载均衡以后,回到话题。
对R3来说,去往4.4.4.4有两个下一跳,一个是正确的下一跳R4,另外一个则是错误的
下—跳R2。
从负载均衡的特性来看,R6通过不同IP地址ping R4的还回地址4.4.4.4,并得到了不同
的结果。
其原因可能就是遭糟遇了负载均衡算法的影响。
那如何证明此猜想是正确的。
还真有办法,方法就是去查阅转发表。
如下所示:
![]()
#上述内容为转发表FIB针对4.4.4.4/32的表项
# 接下来就是见证奇迹的时刻。
#我们可以通过一个命令来确认R3针对某个IP源、目标地址组合会采用那一个下一跳。
如下所示:
![]()
#上述命令询问R3,要是一个源地址为56.1.1.6目标地址为4.4.4.4的数据包,你选那一个接口?
#R3回答:送它去R4(34.1.1.4)
![]()
#同理,当源地址为6.6.6.6目标为4.4.4.4的数据包来时。
#R3说,送它去R2(23.1.1.2)
看了上面的输出,瞬间豁然开朗。
原来这就是R6出现如此奇葩i问题的根本原因。
再次证明,当出现某些奇葩问题时,先从每一个环节出发,掌握细节部分,逐个击破。
问题并不—定都是硬件设备故障或者软件BUG。
但是,故事还没有完,请继续。
把偶尔变成必然
![]()
综上所述,你可能质疑上述实验是一个“巧合”,现实生活中并不一定存在。
让我逐个澄清:
关于重分发度量值为1的情况,其实日常工作环境中,出现的比例相当高。例如在上述RIP网络中,R4后面可能还有更多的网络节点,而这些节点都通过RIP发布网段到网络中,最终导致R3上肯定有某一条路由和R2“"环路""的方式发布过来的度量值相同。
此时问题就发生了
而针对第二项,的确是一个概率性问题,而其导致的问题就是,你不知道什么时候某一个网段不工作了。
例如上述案例中是6.6.6.6为源到4.4.4.4不通,但是可能某一天又变为56.1.1.6为源到4.4.4.4不通了。
原因是转发表会把之前随机选择的端口记录超时掉,然后重新选择。(就好比打麻将,玩完一局以后洗牌再重来。)
但是,我个人认为上述"所谓的巧合"案例是极其值得分享,至少你遇到此种问题时,知道如何下手分析。
必然发生的网络环路:
最后,再给你演示—个必然发生的网络环路。
再次奉上R3的4.4.4.4路由条目:
![]()
你是否考虑过,如果R4哪一天突然不发送4 .4 4.4/32的RIP更新给R3了?例如接口down掉了。
会有什么事情发生?
实际操作一把看看:
![]()
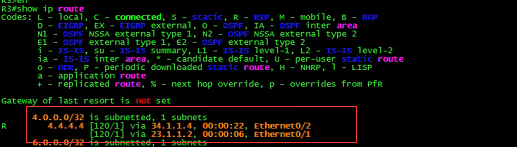
再次查看R3的路由表:
![]()
恐怖的事情发生了,4.4.4.4/32仍然健在。
此时,网络中任何流量去往4.4.4.4都是像进入网络黑洞环路诞生了。
以R6为例,之前源为56.1.1 .6的IP地址可以与4.4.4.4通讯,现在再看看:
![]()
R6无法ping通R4的4.4.4.4了,traceroute也证实了环路诞生。
不光是R6,随便挑一个路由器,咱们就挑R3吧,如下所示:
![]()
R3也环路了!幸好这是实验室,若在现网设备,估计核心交换机都要挂掉了。
让我们简述下上述问题:
R4 down掉其lo0的4.4.4.4以后,R3就全盘相信R2发来的4.4.4. 4/32路由,而R2从R5学到此路由,R5又从R1,R1其实也是从R3学来的,R3从R2学习到,以此类推,网络路由环路就诞生了。
相信很多朋友也有类似的经历,无论是计划维护,还是由于意外事故导致某个网段下线了,但是很神奇的是此网段仍然在全网的路由表里面可见,而伴随此奇怪现象的是很多网络设备的CPU利用率开始飙升。若对于某些老旧型号,并未做路由弓|擎防护策略的设备来说,冲垮它是分分钟的事情,包HSRP/VRRP离线,设备失去响应,OSPF邻居down掉等。
环路问题如何解?
对于以上路由环路问题,什么才是最根本的解法?
有人说,谁让你放两台路由器在那里的,还做了双向重分发。放一台不就没这问题了么?
道理上来说,放一台的确解决了此问题。
但是这就如饮鸩止渴,现在的问题解决了,但是更重要的网络高可用性,冗余性就没有了。
所以,两台甚至多台路由器做双向重分发仍然是需要的。
而解决方法,则是路由过滤。
再次复盘上述环路问题。
实问题的根源就在于一个路由协议域内的路由跑到了其他路由协议域内,然后通过另外一台路由器又跑回来了。
这就好比你买了一套有前后门的房子,然后叫家里小孩从家里前门出去超市给你买包烟,结果他刚从前门出去,马上又从后跑进屋玩"吃鸡"了。
唯一阻止的方法就是做标记。
标记如何做?
重点分析RIP -> OSPF方向,下述操作需要在R1和R2同时执行:
首先当R1以及R2重分发RIP路由到OSPF时,采用对应的策略工具把从RIP域里面重分发过来的路由打上一个特定的标记,此标记是一个数字,由你自己定义。(本例的Cisco工具为route-map)通过标记以后,当这些路由到达OSPF域内部时,我们可以很轻松的挑出这些从RIP来的路由。
接下来,当OSPF域里面的路由即将要被另外一台路由重分发回到RIP时,需要使用同样的策略工具,匹配上述定义的标记,从而把原来RIP来的路由网段给挑选出来,并禁止它们再次进入RIP域。(deny拒绝掉)
这样做,RIP域内部的路由器就不会收到重复的网段路由,例如R3就不会再收到从R2发过来的4.4.4.4/32路由,因为此路由在R1重分发OSPF- >RIP时,就被策略工具给过滤掉了。
在本例中,当R3不在收到R2发来的4 4.4.4/32后,任何问题都迎刃而解了。
配置演示:
R1和R2配置完全相同,你需要同时在R1和R2上都做如下配置操作,此次仅以R1配置为例:
#定义从rip重分布ospf时的策略route-map ,打上标记100。
![]()
#定义从ospf重分发到rip时的策略route-map,首先匹配任何标记为100的路由,并把它拒绝。
#同时允许其他所有路由。(这点很重要,因为你需要考虑到那些没有标记100的路由,该如何处置他们。)
![]()
#最后,把两个route-map策略分别应用到对应的路由协议上:
![]()
配置相当简单,但是为了说明这个故障,我们花了非常大的篇幅来讲解故障细节,所以
理解细节是多么的重要。
让我们看看效果:
#R3路由表:
![]()
#R6ping和Traceroute测试:
![]()
#最后,让我们通过一条命令看看那些被打上标记,挑出来的RIP路由:
#此命令在R5上执行,因为R5仅仅加入OSPF域,不会引起阅读上的误解。
#为了简化输出,我特地加入了一个include entry,只挑出带“entry”关键字的输出项。
![]()
#你会发现,上述路由网段,全都是RIP的路由
#这也变相证明我们的目的达到了
一切恢复正常, 并没有任何环路。
R6的两个源地址均能顺畅的与R4的4.4.4.4通讯了。
问题圆满解决。
题外话:为什么不标记OSPF重分发的路由?
有朋友发现,上述操作一直针对的是RIP进入OSPF的路由,并给他们打上标记。
为什么不对OSPF进入RIP的路由也打上标记呢?
同样的,你的测试一直针对R4的问题, 难道同样的问题不会发生在R6身上么?即R6的6.6.66是否也会在R5.上存在两个下一跳?
其实这样做不是偷懒,而是有原因的。
因为OSPF和RIP的管理距离问题。
此问题最根本的原因,因为RIP的管理距离120不及OSPF的110来的优先。从而导致R2一方面学习到R3发来的4.4.4. 4/32,同时也学习到了R5发来的路由。
但是因为R5发来的是OSPF E2类型外部路由,虽说是外部E2路由。但是瘦死的骆驼比马驮,外部路由仍然是OSPF路由,AD. 上仍然是110。从而导致R1只认R5传来的4.4.4.4/32,并把它放入路由表,然后进而影响了后续的OSPF->RIP的重分发。
回过头来看R6。
当R1或者R2把R6的6.6.6.6重分发到RIP, R3收到以后,通过RIP发给R1或者R2。R1、R2看都不会看一眼,因为R3的RIP路由相比OSPF来说,弱爆了。(管理距离问题,不是因为长相。)
所以此问题就不会产生,自然而然,我们也不需要做什么过滤。
总结:
此篇文章,通过一个典型的OSPF和RIP双向双重分发的案例,向你讲述了一个经典的路由环路产生的过程,复现率100%。
以及如何通过简单的路由策略过滤解决掉此问题。
用一句话总结此篇文章:当两个路由协议通过多个节点互相重分发时,务必小心管理距离较低的一方,此处一定会产生次优路由,从而在特定环境下导致环路。
解决方法为,当管理距离较低的协议路由经过重分发进入管理距离较高的协议时,务必打上标记。等到从其他节点回来时,过滤掉这些带标签的,禁I上他们再次进入管理距离较低的网络。